Oracle应用之分组函数之ROLLUP用法

【摘要】 rollup函数 本博客简单介绍一下oracle分组函数之rollup的用法,rollup函数常用于分组统计,也是属于oracle分析函数的一种
环境准备
create table dept as select * from scott.dept;
create table emp as select * from scott.emp;
12
业务场景:求各部门的...
rollup函数
本博客简单介绍一下oracle分组函数之rollup的用法,rollup函数常用于分组统计,也是属于oracle分析函数的一种
环境准备
create table dept as select * from scott.dept;
create table emp as select * from scott.emp;
- 1
- 2
业务场景:求各部门的工资总和及其所有部门的工资总和
这里可以用union来做,先按部门统计工资之和,然后在统计全部部门的工资之和
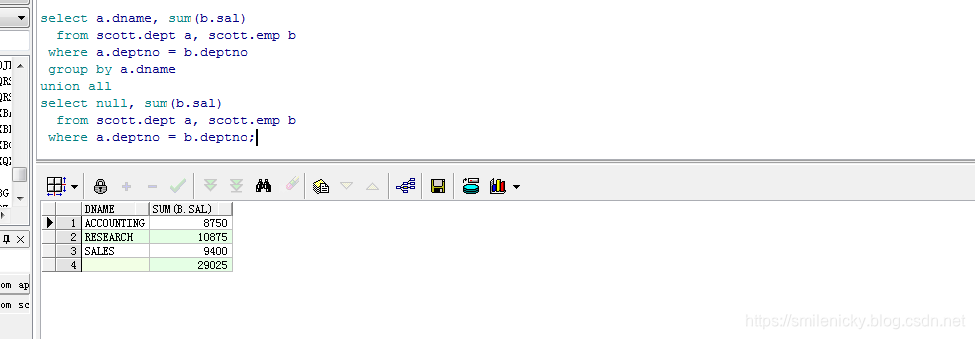
select a.dname, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname
union all
select null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面是用union来做,然后用rollup来做,语法更简单,而且性能更好
select a.dname, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(a.dname);
- 1
- 2
- 3
- 4
- 5
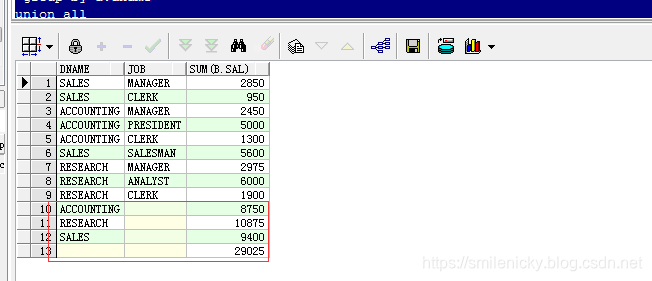
业务场景:基于上面的统计,再加需求,现在要看看每个部门岗位对应的工资之和
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname, b.job
union all//各部门的工资之和
select a.dname, null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname
union all//所有部门工资之和
select null, null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
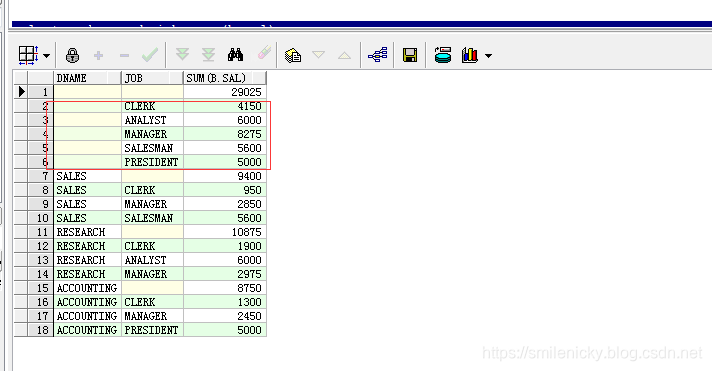
用rollup实现,语法更简单
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(a.dname, b.job);
- 1
- 2
- 3
- 4
假如再加个时间统计的,可以用下面sql:
select to_char(b.hiredate, 'yyyy') hiredate, a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(to_char(b.hiredate, 'yyyy'), a.dname, b.job);
- 1
- 2
- 3
- 4
- 5
cube函数
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by cube(a.dname, b.job);
- 1
- 2
- 3
- 4
- 5
cube函数是维度更细的统计,语法和rollup类似
假设有n个维度,那么rollup会有n个聚合,cube会有2n个聚合
-
rollup统计列
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
… -
cube统计列
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、©、()
…
文章来源: smilenicky.blog.csdn.net,作者:smileNicky,版权归原作者所有,如需转载,请联系作者。
原文链接:smilenicky.blog.csdn.net/article/details/94589276

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)