Kafka快速入门系列(5) | Kafka的工作流程及文件存储机制

【摘要】 本篇博主带来的是Kafka的工作流程及文件存储机制。
目录
一. Kafka的工作流程二. Kafka文件的存储机制
一. Kafka的工作流程
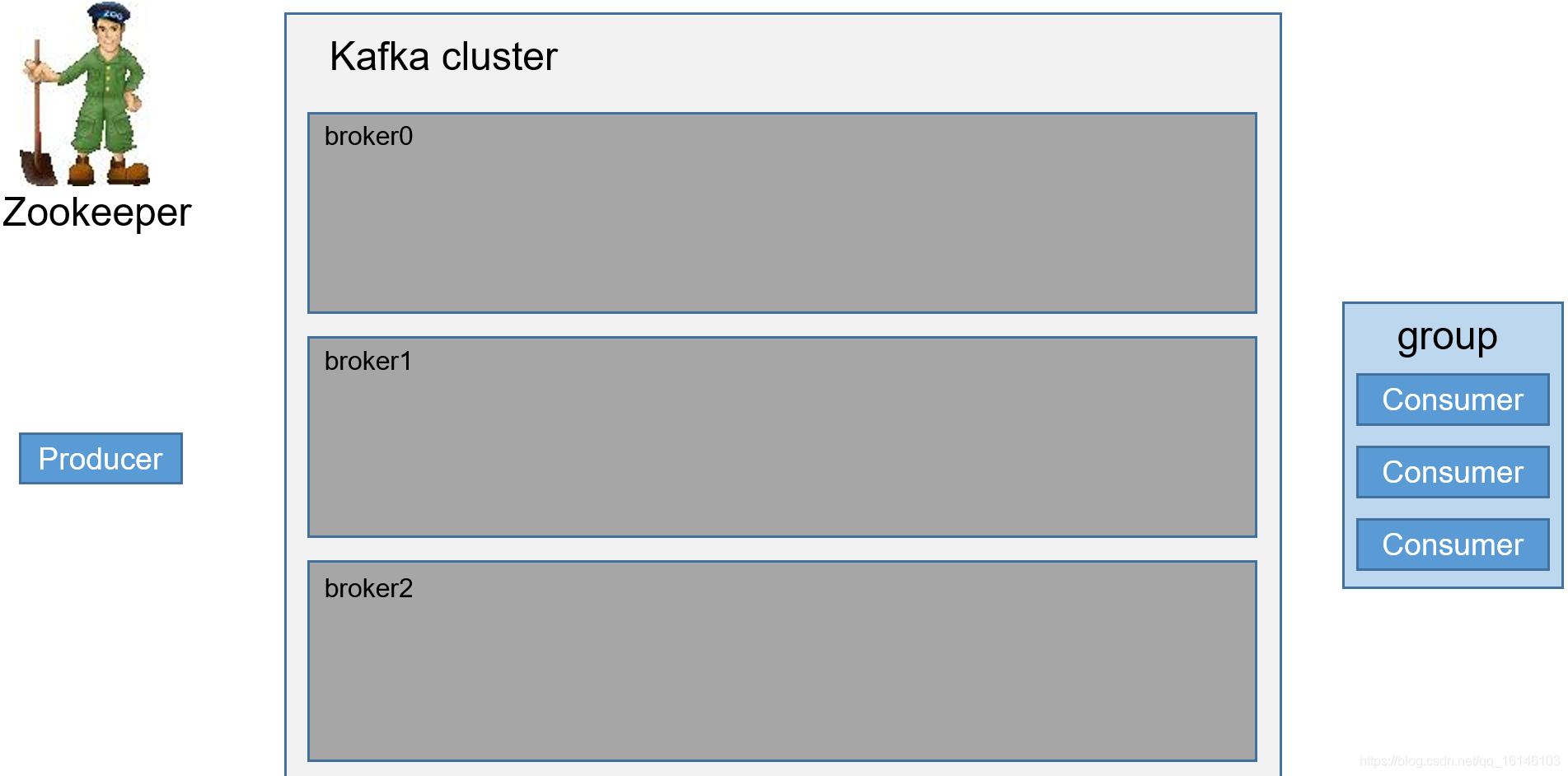
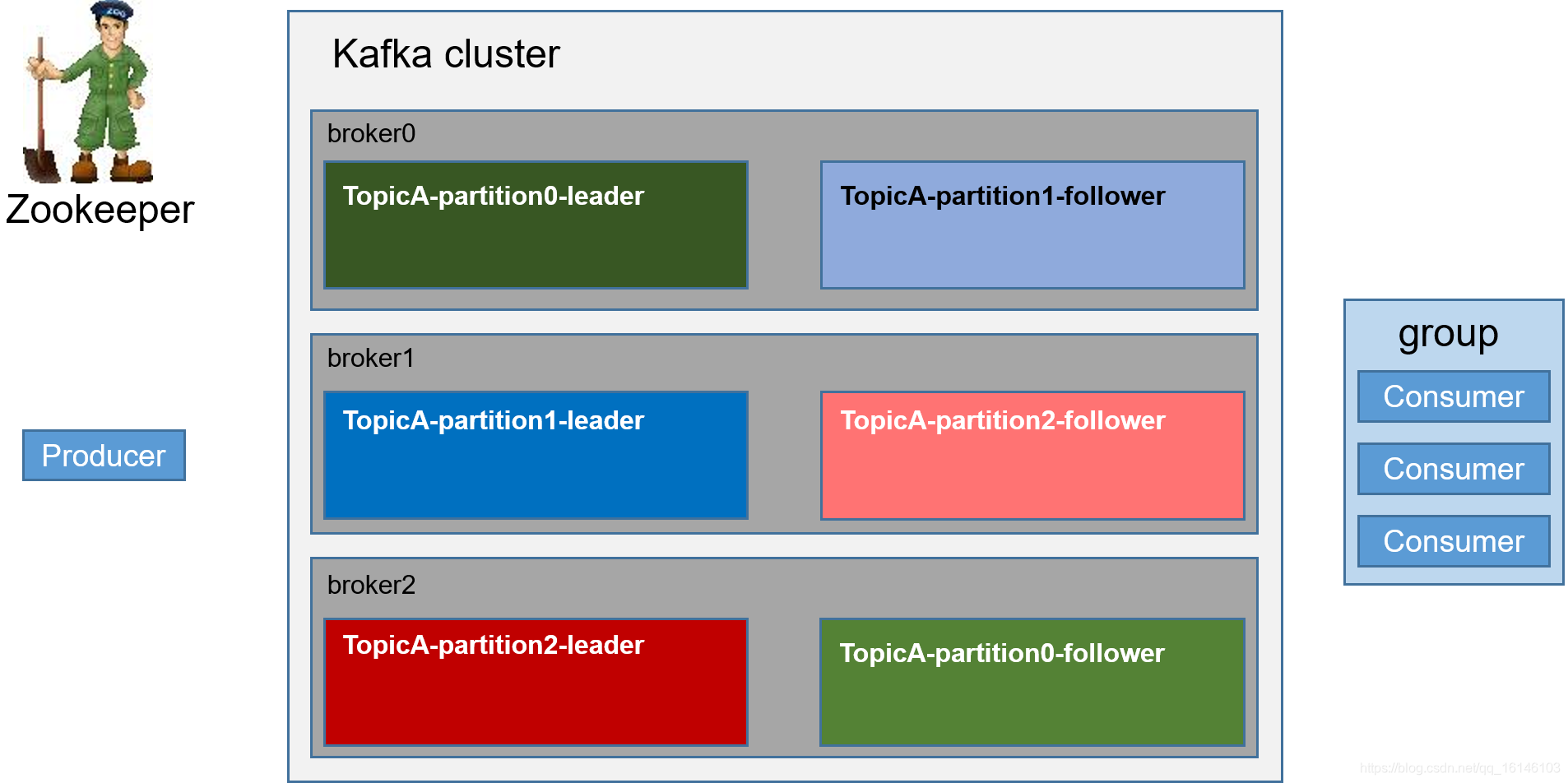
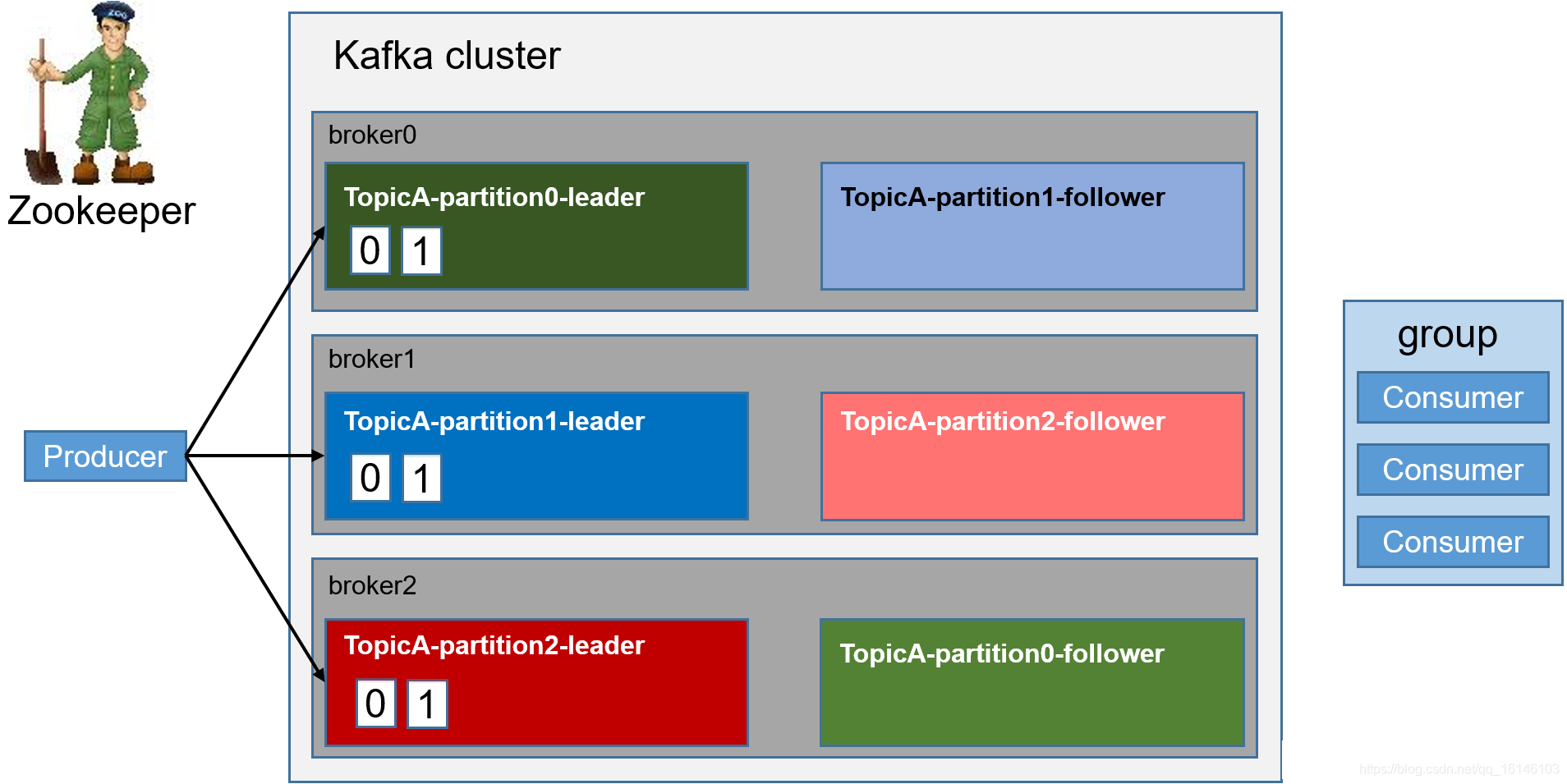
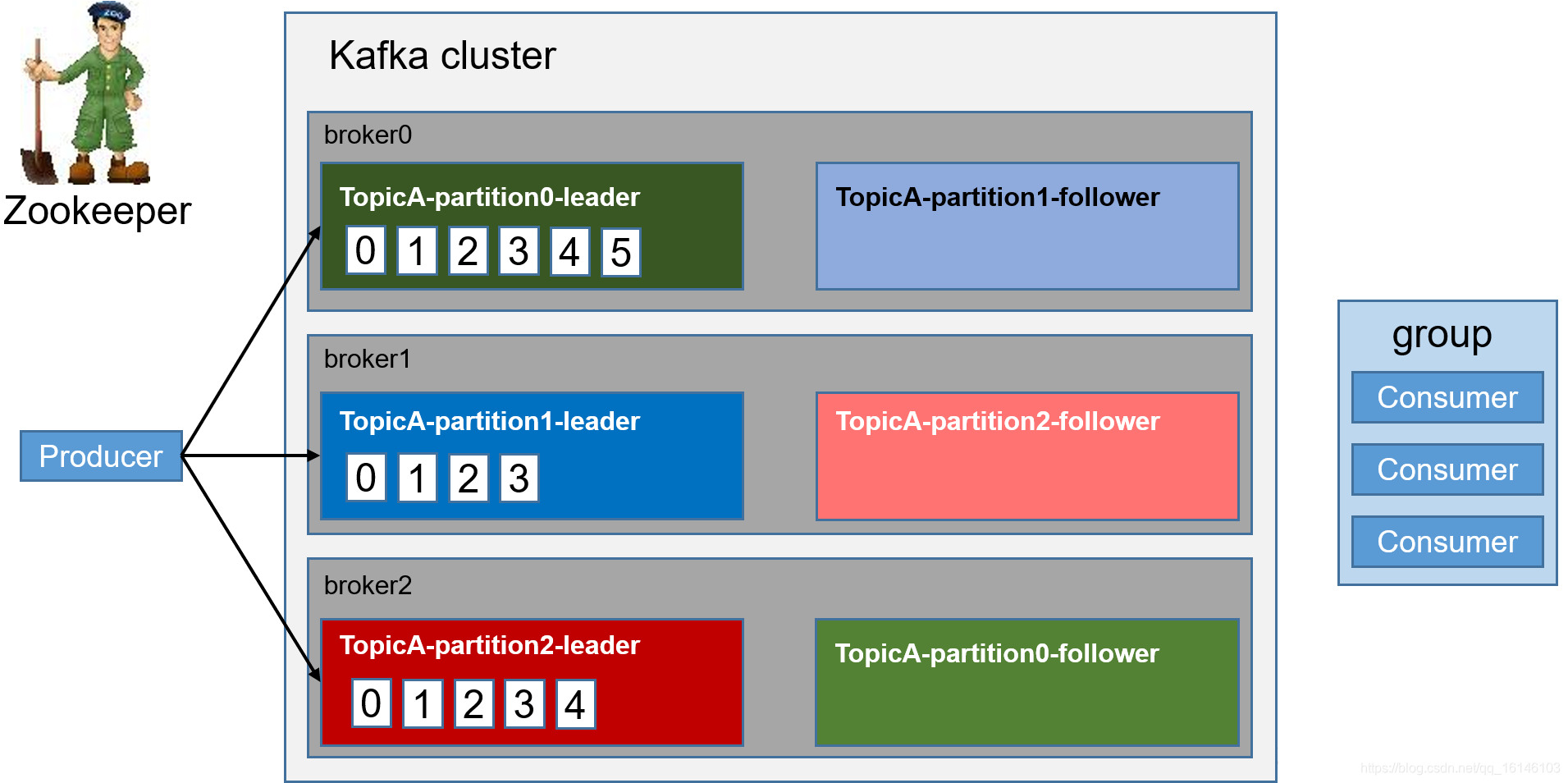
1. Kafka开始部分 2. 创建topic 3.生产者往每一个partition-leader,其中所发数据为一批一批的发送(提高效率) follower为leader的备份,当leader...
本篇博主带来的是Kafka的工作流程及文件存储机制。
一. Kafka的工作流程
- 1. Kafka开始部分

- 2. 创建topic
- 3.生产者往每一个partition-leader,其中所发数据为一批一批的发送(提高效率)
follower为leader的备份,当leader挂掉的时候,follower替代挂掉的leader
follower需要向对应的leader备份数据
- 4. 消费者向leader读取数据
- 5. 如果consumer出现故障,通过offset(偏移量)可进行恢复
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
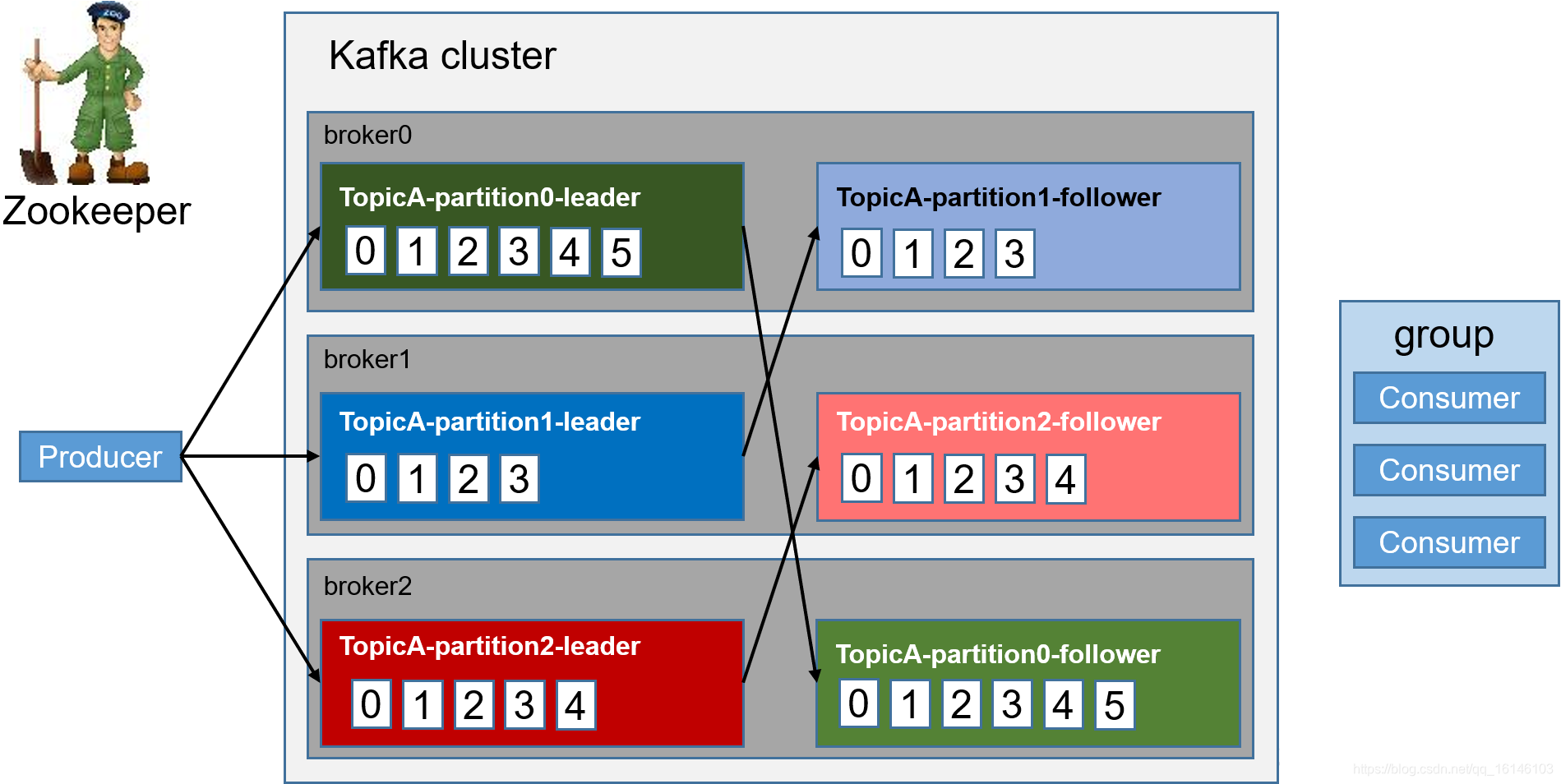
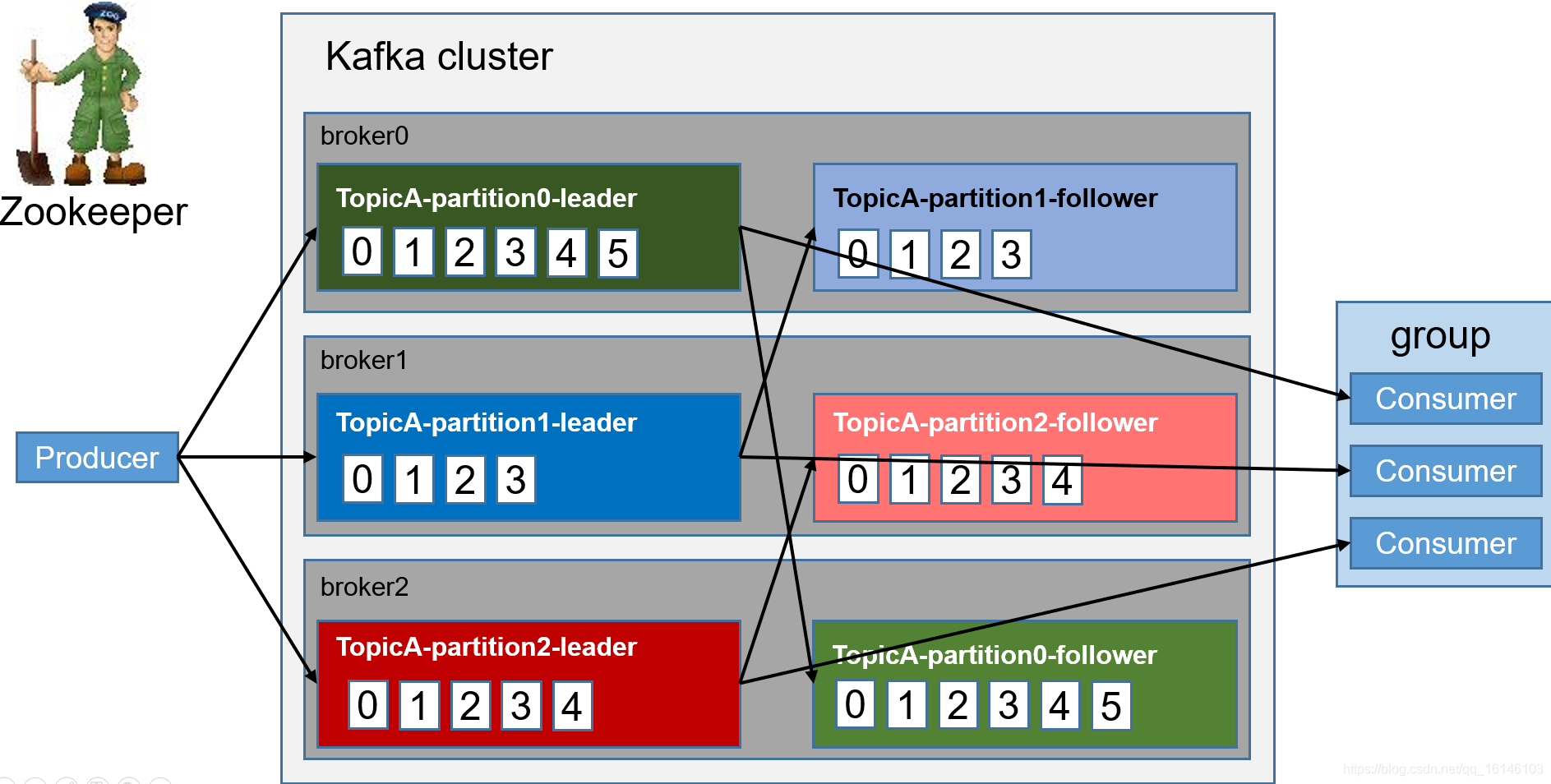
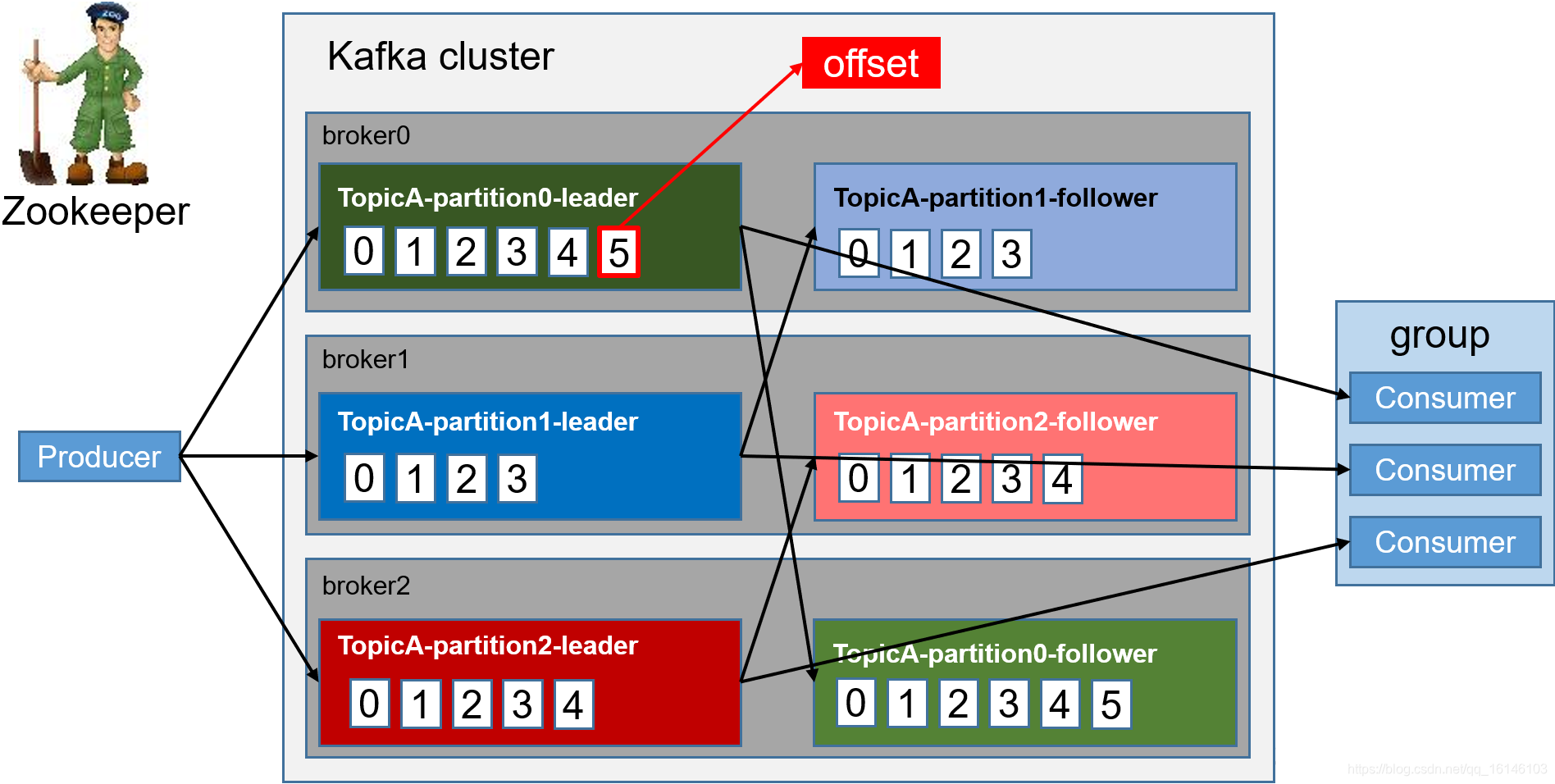
二. Kafka文件的存储机制
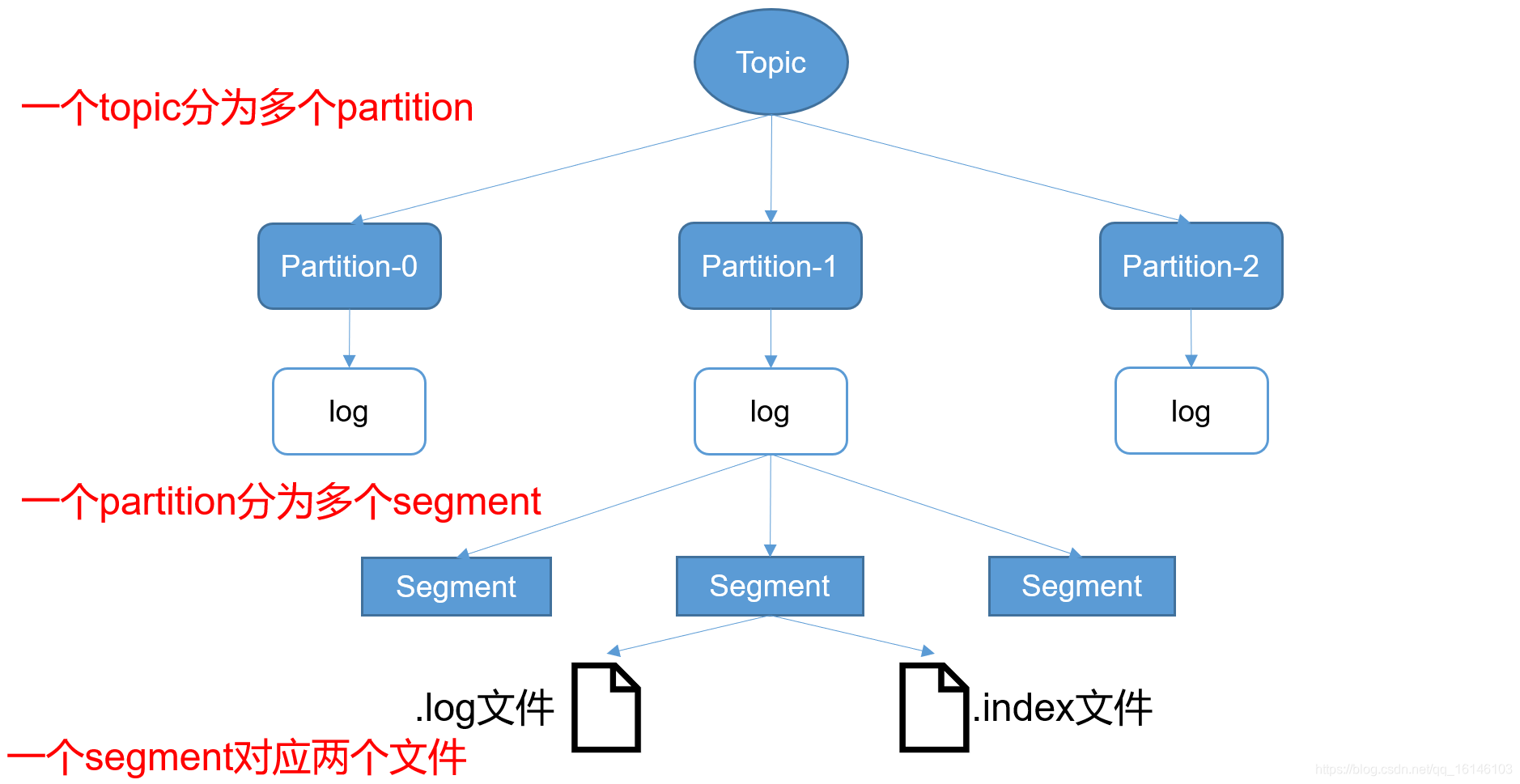
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
index和log文件以当前segment的第一条消息的offset命名。下图为index文件和log文件的结构示意图。

&emsp“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
本次的分享就到这里了,

看 完 就 赞 , 养 成 习 惯 ! ! ! \color{#FF0000}{看完就赞,养成习惯!!!} 看完就赞,养成习惯!!!^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105945311

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)