利用docx4j完美导出word文档(标签替换、插入图片、生成表格)

【摘要】 最近公司让我实现一个利用原有word模板,导出word文档的功能模块,发现docx4j是个很不错的工具,但是之前从来没有用过,对此并不了解,于是上网查找相关资料,也是非常少之,于是便自己开始摸索。
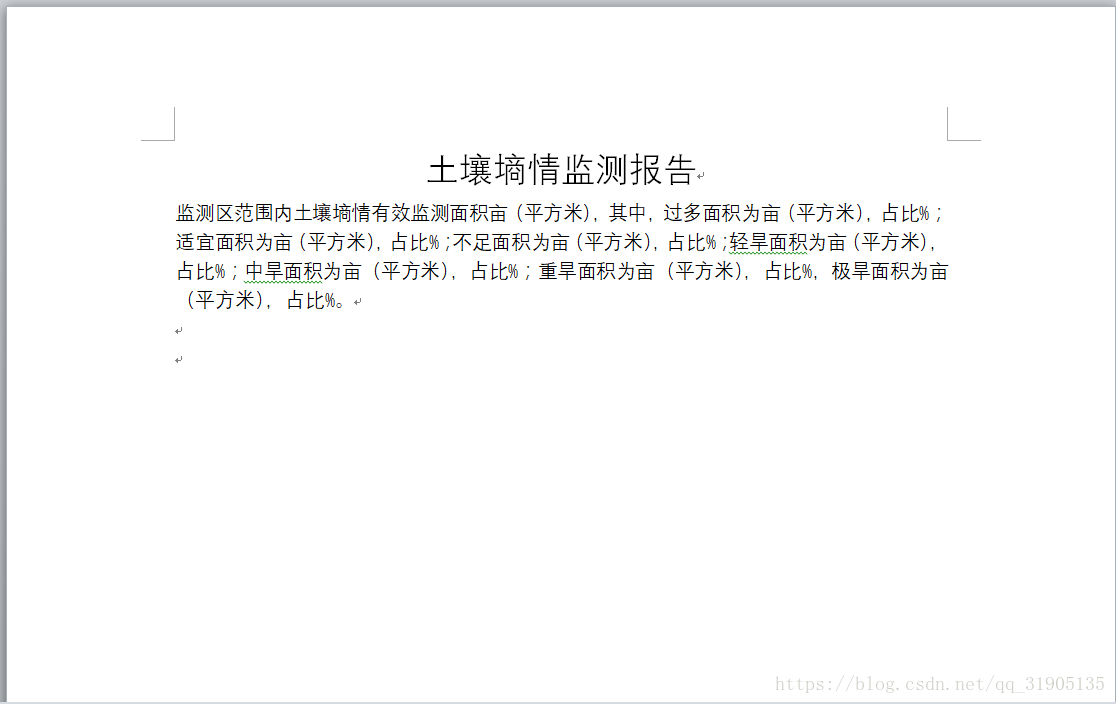
1、原有word模板内容如下:
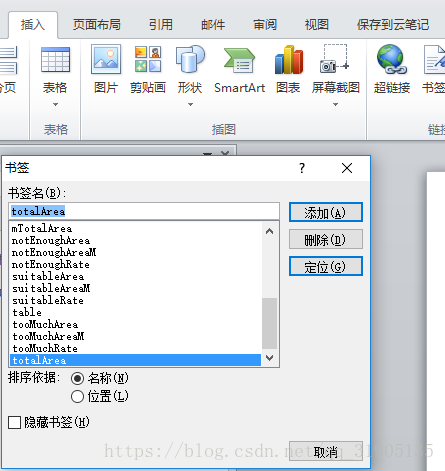
2、在想要插入数据的地方,插入书签,之后会在代码中获取书签并遍历插入内容。
3、直接上代码。
(1)首先我将word模板文件路径配置在confi...
最近公司让我实现一个利用原有word模板,导出word文档的功能模块,发现docx4j是个很不错的工具,但是之前从来没有用过,对此并不了解,于是上网查找相关资料,也是非常少之,于是便自己开始摸索。
1、原有word模板内容如下:
2、在想要插入数据的地方,插入书签,之后会在代码中获取书签并遍历插入内容。
3、直接上代码。
(1)首先我将word模板文件路径配置在config.properties文件中
-
soil_word_template=/template/soil-report.docx
-
soil_word_filename=soil-report.docx
-
/**
-
* 根据表名统计土壤墒情数据并导出word文档
-
*
-
* @param table
-
* 表名
-
* @param cropDate
-
* 监测日期
-
* @param file
-
* BASE64编码的图片文件
-
* @param request
-
* @param response
-
* @return
-
*/
-
@ApiOperation("根据表名统计土壤墒情数据并导出word文档")
-
@RequestMapping(value = "/exportWordReport", method = RequestMethod.POST)
-
@ApiImplicitParams({ @ApiImplicitParam(name = "table", value = "表名",required=false,dataType="query"), @ApiImplicitParam(name="cropDate",value="监测日期",required=false,dataType="query"),
-
@ApiImplicitParam(name = "file", value = "BASE64编码的图片字符",required=false,dataType="query")})
-
public void exportWordReport(String table, String cropDate, String file, HttpServletRequest request,
-
HttpServletResponse response) {
-
// soil_word_template=/template/soil-report.docx
-
// soil_word_filename=soil-report.docx
-
ServletOutputStream out = null;
-
InputStream in = null;
-
File resultFile = null;
-
try {
-
// 土壤墒情word文档模板路径
-
String path = request.getServletContext().getRealPath("") + PropertyUtil.get("soil_word_template");
-
String tempPath = request.getServletContext().getRealPath("");
-
WordprocessingMLPackage wPackage = soilService.exportWordReport(table, cropDate, file, path);
-
// 设置文件属性
-
// wPackage.save(new File("C:\\Users\\admin\\Desktop\\" +
-
// PropertyUtil.get("soil_word_filename")));
-
String fileName = PropertyUtil.get("soil_word_filename");
-
String msg = new String((fileName).getBytes("UTF-8"), "ISO8859-1");
-
response.setContentType("application/msword");
-
response.addHeader("Content-Disposition", "attachment;filename=" + msg);
-
-
// response.setContentType("application/octet-stream");
-
// response.setContentType("application/vnd.ms-excel");
-
response.setCharacterEncoding("UTF-8");
-
// response.addHeader("result", "ok");
-
// response.setContentType("multipart/form-data");
-
out = response.getOutputStream();
-
String strDate = DateUtil.date2String(new Date(), DateUtil.DATE_FORMAT2);
-
resultFile = new File(tempPath + "/tempfile", "soil-report(" + strDate + ").docx");
-
wPackage.save(resultFile);
-
in = new FileInputStream(resultFile);
-
byte[] buffer = new byte[1024];
-
int len = 0;
-
while ((len = in.read(buffer)) > 0) {
-
out.write(buffer, 0, len);
-
}
-
// wPackage.save(out);
-
// wPackage.save(new File("C:\\Users\\admin\\Desktop\\",
-
// "dddd1111.docx"));
-
} catch (Exception e) {
-
Log.error(e);
-
} finally {
-
try {
-
if (out != null) {
-
out.flush();
-
out.close();
-
}
-
if (in != null) {
-
in.close();
-
if (resultFile != null && resultFile.exists() && resultFile.isFile()) {
-
resultFile.delete();
-
}
-
}
-
} catch (IOException e) {
-
// TODO Auto-generated catch block
-
e.printStackTrace();
-
}
-
}
-
}
controller 层中需要注意的地方的是,最开始我用
wPackage.save(out);//直接输出到response的ServletOutPutStream流中,但是这种方式会报错,好像是socket异常之类的问题。
后来改成了代码中的方式,先将文件导出到项目src的webapp文件夹的tempfile文件夹中,然后再从此文件夹中读取该文件,并用out.write()方式输出便能成功执行导出word,前端紧接着下载该word即可。
-
int len = 0;
-
while ((len = in.read(buffer)) > 0) {
-
out.write(buffer, 0, len);
-
}
(3)service层以及serviceImpl层代码
首先来看看咱们需要
是SoilService层代码:
-
/**SoilService层
-
* 根据表名进行统计并导出word报告文档
-
*
-
* @param tableName 表名
-
* @param cropDate 监测日期
-
* @param file base64编码的图片文件字符串
-
* @param path word模板文件路径
-
* @return Map<String, Object>
-
*/
-
WordprocessingMLPackage exportWordReport(String tableName, String cropDate, String file, String path);
然后贴上SoilServiceImpl代码:
-
/**
-
* 根据表名进行统计并导出word报告文档
-
*
-
* @param tableName
-
* @param where
-
* @param file
-
* @return Map<String, Object>
-
*/
-
@Override
-
public WordprocessingMLPackage exportWordReport(String tableName, String cropDate, String file, String path) {
-
// TODO Auto-generated method stub
-
-
Map<String, Object> resultMap = new HashMap<String, Object>();
-
// DecimalFormat decimalFormat = new DecimalFormat("0.00");
-
// 此处可能添加过滤非监测区的条件
-
String where = " \"GRIDCODE\"<8 ";
-
resultMap = findStatisticsDateByTableName(tableName, where);
-
JSONArray jsonArray = (JSONArray) resultMap.get("data1");
-
double totalArea = 0.0; // 有效监测区面积
-
double tooMuchArea = 0.0; // 过多面积1
-
double suitableArea = 0.0;// 适宜面积2
-
double notEnoughArea = 0.0;// 不足面积3
-
double lightDroughtArea = 0.0;// 轻旱面积4
-
double middleDroughtArea = 0.0;// 中旱面积5
-
double heavyDroughtArea = 0.0;// 重旱面积6
-
double extremeDroughtArea = 0.0;// 极旱面积7
-
// double notMonitorArea =0.0; //非监测区8
-
-
double tooMuchRate = 0.0; // 过多面积占比1
-
double suitableRate = 0.0;// 适宜面积2
-
double notEnoughRate = 0.0;// 不足面积3
-
double lightDroughtRate = 0.0;// 轻旱面积4
-
double middleDroughtRate = 0.0;// 中旱面积5
-
double heavyDroughtRate = 0.0;// 重旱面积6
-
double extremeDroughtRate = 0.0;// 极旱面积7
-
// double notMonitorRate =0.0; //非监测区8
-
-
for (Object obj : jsonArray) {
-
JSONObject jsonObject = (JSONObject) obj;
-
String gridcode = jsonObject.getString("gridcode");
-
double area = jsonObject.getDoubleValue("area");
-
if ("1".equals(gridcode)) {
-
tooMuchArea = area * Constant.I;
-
} else if ("2".equals(gridcode)) {
-
suitableArea = area * Constant.I;
-
} else if ("3".equals(gridcode)) {
-
notEnoughArea = area * Constant.I;
-
} else if ("4".equals(gridcode)) {
-
lightDroughtArea = area * Constant.I;
-
} else if ("5".equals(gridcode)) {
-
middleDroughtArea = area * Constant.I;
-
} else if ("6".equals(gridcode)) {
-
heavyDroughtArea = area * Constant.I;
-
} else if ("7".equals(gridcode)) {
-
extremeDroughtArea = area * Constant.I;
-
}
-
// }else if("8".equals(gridcode)){
-
// notMonitorArea =area;
-
// }
-
totalArea += area * Constant.I;
-
}
-
if (totalArea != 0.0) {
-
tooMuchRate = Double.valueOf(DECIMAL_FORMAT.format((tooMuchArea / totalArea) * 100));
-
suitableRate = Double.valueOf(DECIMAL_FORMAT.format((suitableArea / totalArea) * 100));
-
notEnoughRate = Double.valueOf(DECIMAL_FORMAT.format((notEnoughArea / totalArea) * 100));
-
lightDroughtRate = Double.valueOf(DECIMAL_FORMAT.format((lightDroughtArea / totalArea) * 100));
-
middleDroughtRate = Double.valueOf(DECIMAL_FORMAT.format((middleDroughtArea / totalArea) * 100));
-
heavyDroughtRate = Double.valueOf(DECIMAL_FORMAT.format((heavyDroughtArea / totalArea) * 100));
-
extremeDroughtRate = Double.valueOf(DECIMAL_FORMAT.format((extremeDroughtArea / totalArea) * 100));
-
}
-
Map<String, Object> map = new HashMap<String, Object>();
-
-
map.put("cropDate", cropDate);
-
map.put("totalArea", DECIMAL_FORMAT.format(totalArea));
-
map.put("mTotalArea", DECIMAL_FORMAT.format(totalArea / Constant.I * Constant.M));
-
map.put("tooMuchArea", DECIMAL_FORMAT.format(tooMuchArea));
-
map.put("suitableArea", DECIMAL_FORMAT.format(suitableArea));
-
map.put("notEnoughArea", DECIMAL_FORMAT.format(notEnoughArea));
-
map.put("lightDroughtArea", DECIMAL_FORMAT.format(lightDroughtArea));
-
map.put("middleDroughtArea", DECIMAL_FORMAT.format(middleDroughtArea));
-
map.put("heavyDroughtArea", DECIMAL_FORMAT.format(heavyDroughtArea));
-
map.put("extremeDroughtArea", DECIMAL_FORMAT.format(extremeDroughtArea));
-
-
map.put("tooMuchAreaM", DECIMAL_FORMAT.format(tooMuchArea/ Constant.I * Constant.M));
-
map.put("suitableAreaM", DECIMAL_FORMAT.format(suitableArea/ Constant.I * Constant.M));
-
map.put("notEnoughAreaM", DECIMAL_FORMAT.format(notEnoughArea/ Constant.I * Constant.M));
-
map.put("lightDroughtAreaM", DECIMAL_FORMAT.format(lightDroughtArea/ Constant.I * Constant.M));
-
map.put("middleDroughtAreaM", DECIMAL_FORMAT.format(middleDroughtArea/ Constant.I * Constant.M));
-
map.put("heavyDroughtAreaM", DECIMAL_FORMAT.format(heavyDroughtArea/ Constant.I * Constant.M));
-
map.put("extremeDroughtAreaM", DECIMAL_FORMAT.format(extremeDroughtArea/ Constant.I * Constant.M));
-
-
map.put("tooMuchRate", tooMuchRate);
-
map.put("suitableRate", suitableRate);
-
map.put("notEnoughRate", notEnoughRate);
-
map.put("lightDroughtRate", lightDroughtRate);
-
map.put("middleDroughtRate", middleDroughtRate);
-
map.put("heavyDroughtRate", heavyDroughtRate);
-
map.put("extremeDroughtRate", extremeDroughtRate);
-
-
String sql = "SELECT * from (SELECT \"PROVINCE\",\"CITY\",\"COUNTY\",\"TOWN\",\"CROPTYPE\",\"GRIDCODE\",SUM(\"AREA\") \"AREA\" FROM \""
-
+ tableName
-
+ "\" WHERE \"GRIDCODE\"<8 AND \"GRIDCODE\" IS NOT NULL group by \"PROVINCE\",\"CITY\",\"COUNTY\",\"TOWN\",\"CROPTYPE\",\"GRIDCODE\") A "
-
+ "WHERE A.\"AREA\"!=0 AND A.\"AREA\" IS NOT NULL";
-
String totalAreaSql = "SELECT SUM(\"AREA\") \"TOTALAREA\" from (SELECT \"PROVINCE\",\"CITY\",\"COUNTY\",\"TOWN\",\"CROPTYPE\",\"GRIDCODE\",SUM(\"AREA\") \"AREA\" FROM \""
-
+ tableName
-
+ "\" WHERE \"GRIDCODE\"<8 AND \"GRIDCODE\" IS NOT NULL group by \"PROVINCE\",\"CITY\",\"COUNTY\",\"TOWN\",\"CROPTYPE\",\"GRIDCODE\") A "
-
+ "WHERE A.\"AREA\"!=0 AND A.\"AREA\" IS NOT NULL";
-
List<Object[]> list = getBySql(sql, null);
-
double soilTotalArea = Double.valueOf(Objects.toString(getBySql(totalAreaSql, null).get(0), "0.0"))
-
* Constant.M;
-
List<SoilDtoEntityRate> soilList = list.parallelStream().map(x -> coverProperty(x, soilTotalArea))
-
.collect(Collectors.toList());
-
map.put("table", soilList);
-
// map.put("soilTotalArea", soilTotalArea);
-
map.put("img", file);
-
try {
-
WordprocessingMLPackage wPackage = WordprocessingMLPackage.load(new FileInputStream(path));
-
replaceContentByBookmark(wPackage, map);
-
// wPackage.save(new File("C:\\Users\\admin\\Desktop\\" +
-
// PropertyUtil.get("soil_word_filename")));
-
return wPackage;
-
} catch (FileNotFoundException e) {
-
// TODO Auto-generated catch block
-
e.printStackTrace();
-
} catch (Docx4JException e) {
-
// TODO Auto-generated catch block
-
e.printStackTrace();
-
}
-
return null;
-
}
-
/**
-
* 根据多个标签替换段落中的内容
-
*
-
* @param map
-
*/
-
public void replaceContentByBookmark(WordprocessingMLPackage wPackage, Map<String, Object> map) {
-
// 载入模板文件
-
try {
-
// 提取正文
-
MainDocumentPart main = wPackage.getMainDocumentPart();
-
Document doc = main.getContents();
-
Body body = doc.getBody();
-
// ObjectFactory factory = Context.getWmlObjectFactory();
-
// 获取段落
-
List<Object> paragraphs = body.getContent();
-
// 提取书签并创建书签的游标
-
RangeFinder rt = new RangeFinder("CTBookmark", "CTMarkupRange");
-
new TraversalUtil(paragraphs, rt);
-
-
// 遍历书签(在书签处插入文本内容和书签)
-
for (CTBookmark bm : rt.getStarts()) {
-
// 这儿可以对单个书签进行操作,也可以用一个map对所有的书签进行处理
-
if (!bm.getName().equals(DocUtil.tableName)) {
-
if (bm.getName().equals(DocUtil.imageBookMarkName)) { // 图片
-
String file = (String) map.get(bm.getName());
-
if (StringUtils.isNotBlank(file)) {
-
// InputStream inputStream =file.getInputStream();
-
DocUtil.addImage(wPackage, bm, file);
-
}
-
} else {
-
DocUtil.replaceText(bm, map.get(bm.getName()));
-
}
-
} else { // 表格
-
List<SoilDtoEntityRate> list = (List<SoilDtoEntityRate>) map.get(bm.getName());
-
// 创建表格
-
int rowIndex = 2; // 从第三行开始写起(表格从0开始)
-
Tbl tbl = Doc4JUtil.createTable(wPackage, list.size() + rowIndex, 6);
-
Doc4JUtil.mergeCellsHorizontal(tbl, 0, 0, 5);
-
// 设置表格大标题
-
P p = Doc4JUtil.createP("农作物墒情统计列表", "36");
-
Doc4JUtil.setTcValue(tbl, 0, 0, p);
-
// 设置表格副标题
-
Doc4JUtil.setTcValue(tbl, 1, 0, "县区");
-
Doc4JUtil.setTcValue(tbl, 1, 1, "乡镇");
-
Doc4JUtil.setTcValue(tbl, 1, 2, "作物");
-
Doc4JUtil.setTcValue(tbl, 1, 3, "墒情等级");
-
Doc4JUtil.setTcValue(tbl, 1, 4, "面积(亩)");
-
Doc4JUtil.setTcValue(tbl, 1, 5, "占比");
-
-
Map<String, List<SoilDtoEntityRate>> provinceCollect = list.stream()
-
.collect(Collectors.groupingBy(x -> x.getProvince() == null ? "" : x.getProvince()));
-
-
for (Entry<String, List<SoilDtoEntityRate>> proEntry : provinceCollect.entrySet()) {
-
-
Map<String, List<SoilDtoEntityRate>> cityCollect = proEntry.getValue().stream()
-
.collect(Collectors.groupingBy(x -> x.getCity() == null ? "" : x.getCity()));
-
for (Entry<String, List<SoilDtoEntityRate>> cityEntry : cityCollect.entrySet()) {
-
Map<String, List<SoilDtoEntityRate>> countyCollect = cityEntry.getValue().stream()
-
.collect(Collectors.groupingBy(x -> x.getCounty() == null ? "" : x.getCounty()));
-
-
for (Entry<String, List<SoilDtoEntityRate>> countyEntry : countyCollect.entrySet()) {
-
operateCounty(countyEntry, rowIndex, tbl);
-
rowIndex += countyEntry.getValue().size();
-
}
-
-
}
-
-
}
-
Doc4JUtil.setTblAllJcAlign(tbl, JcEnumeration.CENTER);
-
Doc4JUtil.setTblAllVAlign(tbl, STVerticalJc.CENTER);
-
wPackage.getMainDocumentPart().addObject(tbl);
-
}
-
}
-
} catch (Exception e) {
-
// TODO Auto-generated catch block
-
e.printStackTrace();
-
}
-
}
-
-
/**
-
* 写入县区数据
-
*
-
* @param countyEntry
-
* @param rowIndex
-
* @param tbl
-
*/
-
private void operateCounty(Entry<String, List<SoilDtoEntityRate>> countyEntry, int rowIndex, Tbl tbl) {
-
// TODO Auto-generated method stub
-
// 获取每个entry的记录条数
-
int beginRow = rowIndex;
-
int size = countyEntry.getValue().size();
-
// 处理县区
-
// 合并单元格
-
Doc4JUtil.mergeCellsVertically(tbl, 0, beginRow, beginRow + size);
-
Doc4JUtil.setTcValue(tbl, beginRow, 0, countyEntry.getKey());
-
// 处理镇
-
Map<String, List<SoilDtoEntityRate>> townCollect = countyEntry.getValue().stream()
-
.collect(Collectors.groupingBy(x -> x.getTown() == null ? "" : x.getTown()));
-
for (Entry<String, List<SoilDtoEntityRate>> townEntry : townCollect.entrySet()) {
-
operateTown(townEntry, beginRow, tbl);
-
beginRow += townEntry.getValue().size();
-
}
-
}
-
-
/**
-
* 写入镇数据
-
*
-
* @param townEntry
-
* @param rowIndex
-
* @param tbl
-
*/
-
private void operateTown(Entry<String, List<SoilDtoEntityRate>> townEntry, int rowIndex, Tbl tbl) {
-
// TODO Auto-generated method stub
-
// 获取每个entry的记录条数
-
int beginRow = rowIndex;
-
int size = townEntry.getValue().size();
-
// 处理县区
-
// 合并单元格
-
Doc4JUtil.mergeCellsVertically(tbl, 1, beginRow, beginRow + size);
-
Doc4JUtil.setTcValue(tbl, beginRow, 1, townEntry.getKey());
-
Map<String, List<SoilDtoEntityRate>> cropCollect = townEntry.getValue().stream().sorted((x, j) -> {
-
return (int) (x.getGridcode() - j.getGridcode());
-
}).collect(Collectors.groupingBy(x -> x.getCroptype() == null ? "" : x.getCroptype()));
-
for (Entry<String, List<SoilDtoEntityRate>> cropEntry : cropCollect.entrySet()) {
-
operateCropType(cropEntry, beginRow, tbl);
-
beginRow += cropEntry.getValue().size();
-
}
-
-
}
-
-
/**
-
* 写入种植类型、土壤墒情等级,面积,占比
-
*
-
* @param cropEntry
-
* @param rowIndex
-
* @param tbl
-
*/
-
private void operateCropType(Entry<String, List<SoilDtoEntityRate>> cropEntry, int rowIndex, Tbl tbl) {
-
// TODO Auto-generated method stub
-
-
int beginRow = rowIndex;
-
int size = cropEntry.getValue().size();
-
// 处理县区
-
// 合并单元格
-
Doc4JUtil.mergeCellsVertically(tbl, 2, beginRow, beginRow + size);
-
Doc4JUtil.setTcValue(tbl, beginRow, 2, cropEntry.getKey());
-
List<SoilDtoEntityRate> soilList = cropEntry.getValue();
-
for (int i = 0; i < size; i++) {
-
Doc4JUtil.setTcValue(tbl, beginRow + i, 3, gridCodeMap.get(soilList.get(i).getGridcode()));
-
Doc4JUtil.setTcValue(tbl, beginRow + i, 4, String.valueOf(soilList.get(i).getArea()));
-
Doc4JUtil.setTcValue(tbl, beginRow + i, 5, soilList.get(i).getRate());
-
}
-
}
-
public SoilDtoEntityRate coverProperty(Object[] x, double totalSoilArea) {
-
String rate = "0.00%";
-
double area = Double.valueOf(Objects.toString(x[6], "0")) * Constant.M;
-
area = Double.valueOf(DECIMAL_FORMAT.format(area));
-
if (totalSoilArea != 0) {
-
rate = DECIMAL_FORMAT.format((area / totalSoilArea) * 100) + "%";
-
}
-
return new SoilDtoEntityRate(Objects.toString(x[0], ""), Objects.toString(x[1], ""), Objects.toString(x[2], ""),
-
Objects.toString(x[3], ""), Objects.toString(x[4], ""), Double.valueOf(Objects.toString(x[5], "0")),
-
area, rate);
-
}
接下来是以上业务代码中用到的工具类中的方法:
-
/**
-
* @Description:创建表格(默认水平居中,垂直居中)
-
*/
-
public static Tbl createTable(WordprocessingMLPackage wordPackage, int rowNum,
-
int colsNum) throws Exception {
-
colsNum = Math.max(1, colsNum);
-
rowNum = Math.max(1, rowNum);
-
int widthTwips = getWritableWidth(wordPackage);
-
int colWidth = widthTwips / colsNum;
-
int[] widthArr = new int[colsNum];
-
for (int i = 0; i < colsNum; i++) {
-
widthArr[i] = colWidth;
-
}
-
return createTable(rowNum, colsNum, widthArr);
-
}
-
-
/**
-
* @Description:创建表格(默认水平居中,垂直居中)
-
*/
-
public static Tbl createTable(int rowNum, int colsNum, int[] widthArr)
-
throws Exception {
-
colsNum = Math.max(1, Math.min(colsNum, widthArr.length));
-
rowNum = Math.max(1, rowNum);
-
Tbl tbl = new Tbl();
-
StringBuffer tblSb = new StringBuffer();
-
tblSb.append("<w:tblPr ").append(Namespaces.W_NAMESPACE_DECLARATION)
-
.append(">");
-
tblSb.append("<w:tblStyle w:val=\"TableGrid\"/>");
-
tblSb.append("<w:tblW w:w=\"0\" w:type=\"auto\"/>");
-
// 上边框
-
tblSb.append("<w:tblBorders>");
-
tblSb.append("<w:top w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
// 左边框
-
tblSb.append("<w:left w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
// 下边框
-
tblSb.append("<w:bottom w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
// 右边框
-
tblSb.append("<w:right w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
tblSb.append("<w:insideH w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
tblSb.append("<w:insideV w:val=\"single\" w:sz=\"1\" w:space=\"0\" w:color=\"auto\"/>");
-
tblSb.append("</w:tblBorders>");
-
tblSb.append("</w:tblPr>");
-
TblPr tblPr = null;
-
tblPr = (TblPr) XmlUtils.unmarshalString(tblSb.toString());
-
Jc jc = new Jc();
-
// 单元格居中对齐
-
jc.setVal(JcEnumeration.CENTER);
-
tblPr.setJc(jc);
-
-
tbl.setTblPr(tblPr);
-
-
// 设定各单元格宽度
-
TblGrid tblGrid = new TblGrid();
-
tbl.setTblGrid(tblGrid);
-
for (int i = 0; i < colsNum; i++) {
-
TblGridCol gridCol = new TblGridCol();
-
gridCol.setW(BigInteger.valueOf(widthArr[i]));
-
tblGrid.getGridCol().add(gridCol);
-
}
-
// 新增行
-
for (int j = 0; j < rowNum; j++) {
-
Tr tr = new Tr();
-
tbl.getContent().add(tr);
-
// 列
-
for (int i = 0; i < colsNum; i++) {
-
Tc tc = new Tc();
-
tr.getContent().add(tc);
-
-
TcPr tcPr = new TcPr();
-
TblWidth cellWidth = new TblWidth();
-
cellWidth.setType("dxa");
-
cellWidth.setW(BigInteger.valueOf(widthArr[i]));
-
tcPr.setTcW(cellWidth);
-
tc.setTcPr(tcPr);
-
-
// 垂直居中
-
setTcVAlign(tc, STVerticalJc.CENTER);
-
P p = new P();
-
PPr pPr = new PPr();
-
pPr.setJc(jc);
-
p.setPPr(pPr);
-
R run = new R();
-
p.getContent().add(run);
-
tc.getContent().add(p);
-
}
-
}
-
return tbl;
-
}
-
-
/**
-
* @Description: 跨列合并
-
*/
-
public static void mergeCellsHorizontal(Tbl tbl, int row, int fromCell, int toCell) {
-
if (row < 0 || fromCell < 0 || toCell < 0) {
-
return;
-
}
-
List<Tr> trList = getTblAllTr(tbl);
-
if (row > trList.size()) {
-
return;
-
}
-
Tr tr = trList.get(row);
-
List<Tc> tcList = getTrAllCell(tr);
-
for (int cellIndex = fromCell, len = Math
-
.min(tcList.size() - 1, toCell); cellIndex <= len; cellIndex++) {
-
Tc tc = tcList.get(cellIndex);
-
TcPr tcPr = getTcPr(tc);
-
HMerge hMerge = tcPr.getHMerge();
-
if (hMerge == null) {
-
hMerge = new HMerge();
-
tcPr.setHMerge(hMerge);
-
}
-
if (cellIndex == fromCell) {
-
hMerge.setVal("restart");
-
} else {
-
hMerge.setVal("continue");
-
}
-
}
-
}
-
/**
-
* 插入图片
-
* @param wPackage
-
* @param bm
-
* @param file
-
*/
-
public static void addImage(WordprocessingMLPackage wPackage, CTBookmark bm, String file) {
-
try {
-
// 这儿可以对单个书签进行操作,也可以用一个map对所有的书签进行处理
-
// 获取该书签的父级段落
-
P p = (P) (bm.getParent());
-
// R对象是匿名的复杂类型,然而我并不知道具体啥意思,估计这个要好好去看看ooxml才知道
-
R run = factory.createR();
-
// 读入图片并转化为字节数组,因为docx4j只能字节数组的方式插入图片
-
byte[] bytes = FileUtil.getByteFormBase64DataByImage(file);
-
-
// InputStream is = new FileInputStream;
-
// byte[] bytes = IOUtils.toByteArray(inputStream);
-
// byte[] bytes = FileUtil.getByteFormBase64DataByImage("");
-
// 开始创建一个行内图片
-
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage.createImagePart(wPackage, bytes);
-
// createImageInline函数的前四个参数我都没有找到具体啥意思,,,,
-
// 最有一个是限制图片的宽度,缩放的依据
-
Inline inline = imagePart.createImageInline(null, null, 0, 1, false, 0);
-
// 获取该书签的父级段落
-
// drawing理解为画布?
-
Drawing drawing = factory.createDrawing();
-
drawing.getAnchorOrInline().add(inline);
-
run.getContent().add(drawing);
-
p.getContent().add(run);
-
} catch (Exception e) {
-
// TODO: handle exception
-
Log.error(e);
-
}
-
}
-
/**
-
* 在标签处插入内容
-
*
-
* @param bm
-
* @param wPackage
-
* @param object
-
* @throws Exception
-
*/
-
public static void replaceText(CTBookmark bm, Object object) throws Exception {
-
if (object == null) {
-
return;
-
}
-
// do we have data for this one?
-
if (bm.getName() == null)
-
return;
-
String value = object.toString();
-
Log.info("标签名称:"+bm.getName());
-
try {
-
// Can't just remove the object from the parent,
-
// since in the parent, it may be wrapped in a JAXBElement
-
List<Object> theList = null;
-
ParaRPr rpr = null;
-
if (bm.getParent() instanceof P) {
-
PPr pprTemp = ((P) (bm.getParent())).getPPr();
-
if (pprTemp == null) {
-
rpr = null;
-
} else {
-
rpr = ((P) (bm.getParent())).getPPr().getRPr();
-
}
-
theList = ((ContentAccessor) (bm.getParent())).getContent();
-
} else {
-
return;
-
}
-
int rangeStart = -1;
-
int rangeEnd = -1;
-
int i = 0;
-
for (Object ox : theList) {
-
Object listEntry = XmlUtils.unwrap(ox);
-
if (listEntry.equals(bm)) {
-
-
if (((CTBookmark) listEntry).getName() != null) {
-
-
rangeStart = i + 1;
-
-
}
-
} else if (listEntry instanceof CTMarkupRange) {
-
if (((CTMarkupRange) listEntry).getId().equals(bm.getId())) {
-
rangeEnd = i - 1;
-
-
break;
-
}
-
}
-
i++;
-
}
-
int x = i - 1;
-
//if (rangeStart > 0 && x >= rangeStart) {
-
// Delete the bookmark range
-
for (int j = x; j >= rangeStart; j--) {
-
theList.remove(j);
-
}
-
// now add a run
-
org.docx4j.wml.R run = factory.createR();
-
org.docx4j.wml.Text t = factory.createText();
-
// if (rpr != null)
-
// run.setRPr(paraRPr2RPr(rpr));
-
t.setValue(value);
-
run.getContent().add(t);
-
//t.setValue(value);
-
-
theList.add(rangeStart, run);
-
//}
-
} catch (ClassCastException cce) {
-
Log.error(cce);
-
}
-
}
-
/**
-
* @Description: 跨行合并
-
*/
-
public static void mergeCellsVertically(Tbl tbl, int col, int fromRow, int toRow) {
-
if (col < 0 || fromRow < 0 || toRow < 0) {
-
return;
-
}
-
for (int rowIndex = fromRow; rowIndex <= toRow; rowIndex++) {
-
Tc tc = getTc(tbl, rowIndex, col);
-
if (tc == null) {
-
break;
-
}
-
TcPr tcPr = getTcPr(tc);
-
VMerge vMerge = tcPr.getVMerge();
-
if (vMerge == null) {
-
vMerge = new VMerge();
-
tcPr.setVMerge(vMerge);
-
}
-
if (rowIndex == fromRow) {
-
vMerge.setVal("restart");
-
} else {
-
vMerge.setVal("continue");
-
}
-
}
-
}
至此,大家就可以看到导出的word文档效果了,如下图:

文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/80431042

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)