初识MySQL之数据查询篇(上)

本次开启MySQL专栏的博文,针对MySQL数据库的前期介绍和了解,我们设置了初识MySQL之概念认知篇,正所谓,兵马未动、粮草先行,本次我们先以MySQL的技术性操作,实用篇开启MySQL的学习,概念和前期引入我们会在后期设置,话不多说,我们步入正题!
熟练掌握MySQL的查询不仅可熟练的玩转MySQL,还可以与Hadoop里面的hive插件,还有spark这些大数据应用软件融会贯通,反正就是一句话,学好MySQL是非常重要的。
引入
SELECT语句的基本查询:
SELECT (distinct:会过滤掉相同的行) 要查询的列名 FROM 表名字 WHERE 限制条件;
- 1
select * from tb_student where name like '王%' GROUP BY MAJOR_class HAVING major_class='4'
- 1
实例操作
1:select要查询的内容,内容可以是一个字段、多个字段,或者是全部字段,也可以是表达式或者函数。如果要查询各个字段需要用“,”将其隔开,书写的顺序决定的显示的顺序,我们也可以在后面进行列名的重命名
-- SELECT 语句的基本语法
select * from tb_course;
select t.name 课程名称 from tb_course as t;
select count(*) from tb_course;
- 1
- 2
- 3
- 4


-- 限制查询
select * from tb_course where name like '数据%';
- 1
- 2
又叫模糊查询,我们有时候不知道这个表里面的一些属性的具体参数值,我们可以用模糊查询,利用like % 来通配符的查询。
总结:一般来说,我们首先有
select distinct(过滤)查询字段名 重命名 [或者 * 或者其他不重名的查询字段]
from 数据表
where 条件表达式 (= < > 等运算符)
group by 字段名列表(按照这个字段名列表进行分组)
having 逻辑表达式(在分组好的各组里面进行逻辑筛选,过滤,最终选择出符合要求的数据集)
order by 字段名(按照字段名进行排序默认为从小到大)desc(从大到小)
limit n(偏移量,start) h (stop),一般如果只想要显示5个值:limit 5 ,因为第一个参数默认为0
这样就达到了主观的查询要显示的条数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
简单查询
select
select a.`NAME`,NOW() from tb_student as a
- 1
使用now()函数输出我们查询的时间和日期
where
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值
- 1
select * from tb_student as b where b.GENDER='男' and b.BIRTHDATE>='2001-07-01';
- 1

select * from tb_electives as c where c.SCORE BETWEEN '80' and '100' ORDER BY SCORE desc;
- 1
使用其他的模式进行匹配,我们首先查询了成绩80-100的,然后对其进行排序
between...and、not between...and、and、in、not in、like、not like、or 、not、is null、is not null
- 1
这些运算符和我们之前的学习都差不多,只要可以理解单词的意思问题就不大
select * from tb_student as c where c.ID in ('2017001002','2017001011','2017001012','2017001013');
- 1
- 2

对于之前我们所说的模式匹配符
%代表可以匹配多个字符,也就是0个或多个
_代表任意单个字符,如果匹配的里面包括这个那么就需要利用到换义字符\
- 1
- 2
select * from tb_student as c where c.`NAME` like '程_忠';
- 1

select * from tb_student where id is null;
select * from tb_student where id is not null;
- 1
- 2
查看这个参数是否为空,利用这个模式来查询
select * from tb_studnet where name='k' and 条件 ,
- 1
SELECT * from tb_student as c where c.GENDER='女'
or c.BIRTHDATE>='2001-07-01' or c.MAJOR_CLASS='1';
- 1
- 2
- 3
注意这里的or and运算符的处理我们还是要理解一些,如果在同一个语句里面出现了他们,那么应该先运算and两边的条件表达式,所以下图中你才看见到了班级编号为1的排列到前面了。
order by子句
在查询结果集中,数据行是按照他们在表中的顺序进行排列的。我们可以使用order by字句对查询结果集中的数据行按照指定的排序方法。
SELECT * from tb_electives as c ORDER BY c.SCORE desc;
查询分数的排序好的数据,这里我们发现不一定需要where这个参数,如果需要也是过滤的
- 1
- 2

使用limit子句
SELECT * from tb_electives as c ORDER BY c.SCORE desc limit 10 ;
显示前面的10条数据
- 1
- 2
SELECT * from tb_electives as c ORDER BY c.SCORE desc limit 10 ,1;
显示第11行的数据,也就是10+1=11
- 1
- 2
统计查询
这个里面就会涉及到一些集合函数和group by子句,having子句的组合查询,最后对查询结果进行求和操作和其他数学操作
count(字段)对字段中的个数统计次数
sum(求和)
avg(平均值)
max(最大值)
min(最小值)
- 1
- 2
- 3
- 4
- 5
select count(*) 学生总人数 from tb_student;
- 1

select count(*) as 学生总人数 ,sum(SCORE) 总成绩, avg(SCORE) 班级平均成绩,
max(SCORE) 最高分,min(SCORE) 最低分 from tb_electives
where COURSE_CLASS_CODE='3SL1037A.01';
- 1
- 2
- 3

使用group by子句
group by 语句的作用就是可以利用相同字段的进行分组,然后达到相应的查询目的
SELECT column_name, function(column_name) FROM table_name
WHERE column_name operator value
GROUP BY column_name;
- 1
- 2
- 3
例如:
SELECT COURSE_CLASS_CODE 课程编号,avg(score) 班级平均分 from tb_electives GROUP BY COURSE_CLASS_CODE;
- 1
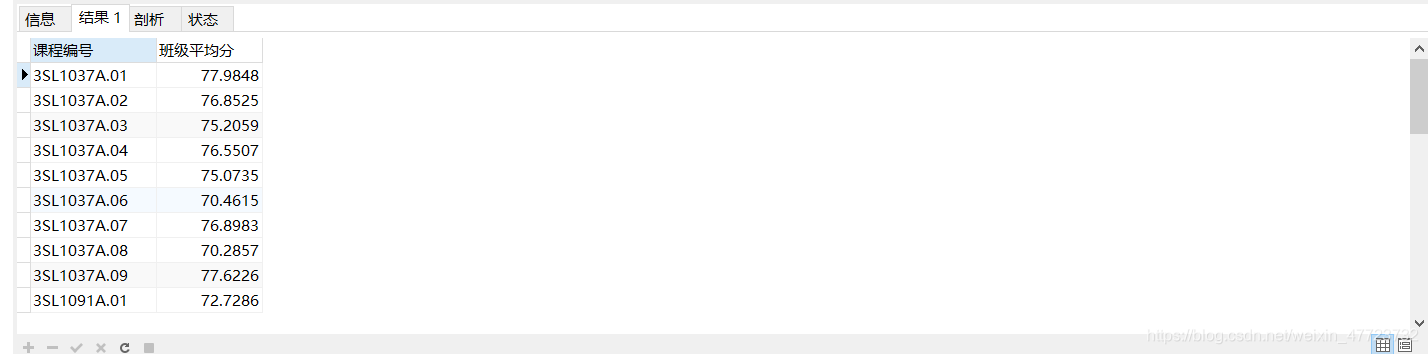
按照相应的条件进行筛选就必须要在后加上 having 筛选条件了
比如我想要筛选到所有班级平均成绩大于77的班级,实现过程如下:
SELECT COURSE_CLASS_CODE 课程编号,avg(score) 班级平均分 from tb_electives GROUP BY COURSE_CLASS_CODE HAVING AVG(score) >=77 ;
- 1

下面简单的排列一下顺序,也就是利用order by 字段名 desc进行相应的排序,结果如下,这里我们利用round(数据,保留的小数的位数)来格式化我们的数据:
SELECT COURSE_CLASS_CODE 课程编号,ROUND(avg(score),1) 班级平均分 from tb_electives GROUP BY COURSE_CLASS_CODE HAVING AVG(score) >=77 ORDER BY AVG(SCORE) desc ;
- 1
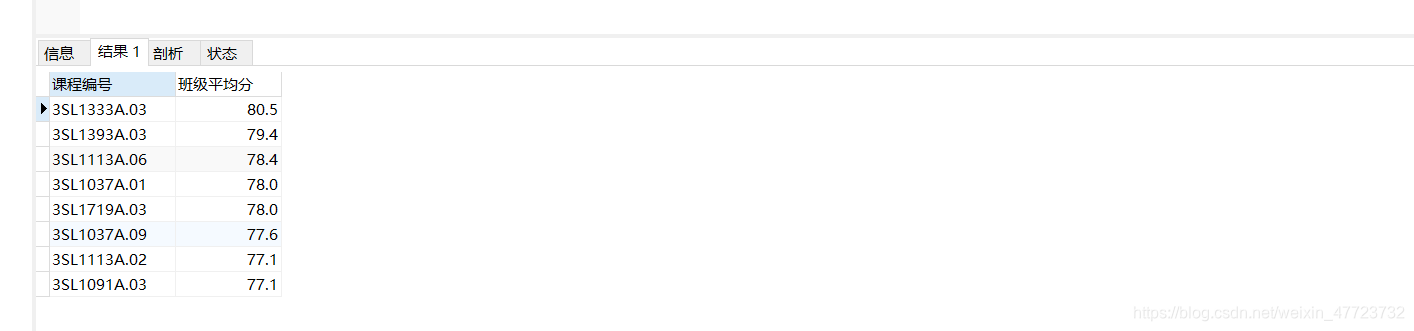
至于这里的语法查询,我觉得合理应用having的查询是比较的明智的,选取我们需要的数据,但是如果我们现在就只想要平均成绩最高的那个班级,我们可以有多种方法,比如我们利用聚合函数max,也可以排好序之后,使用limit 子句加上1 :
SELECT COURSE_CLASS_CODE 课程编号,ROUND(avg(score),1) 班级平均分 from tb_electives GROUP BY COURSE_CLASS_CODE HAVING AVG(score) >=77 ORDER BY AVG(SCORE) desc LIMIT 1 ;
- 1

多表查询
在实际的应用场景之中,我们发现大量的数据集,并不是放在一张表里面的,可能是多张表,也可能是几百万张表,这个时候我们需要利用我们的一些分表查询
(在Hadoop里面有一种叫做,分区分桶:分区的作用提高我们查询的效率,细化数据管理直接读取相应的目录,缩小MapReduce程序要扫描的数据量;分桶的作用就是当我们利用join查询的时候可以提高效率,也就是我们利用分桶字段做连接字段的时候)
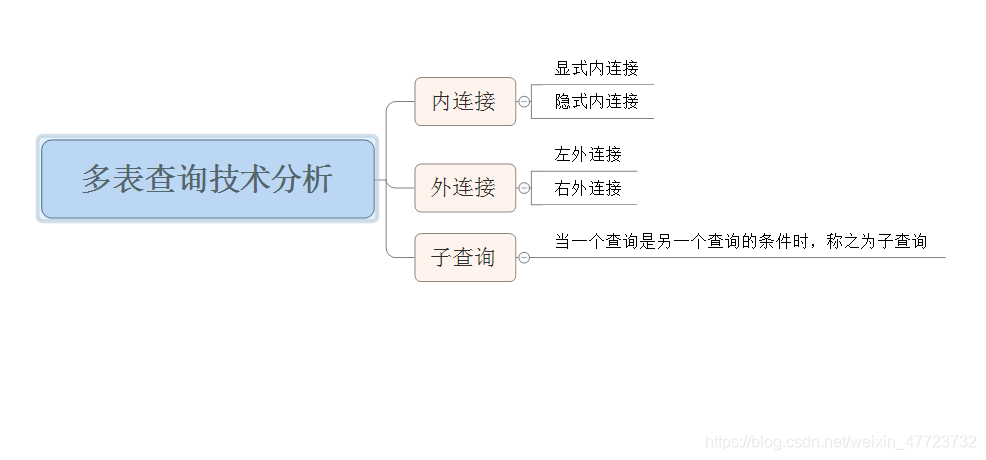
内连接
select * from a[inner] join b on a.字段=b.字段
- 1
SELECT COURSE_CLASS_CODE,count(*) from tb_student INNER JOIN tb_electives on tb_student.ID=tb_electives.STUDENT_ID GROUP BY COURSE_CLASS_CODE ;
- 1
查询出各个班级的人数分别是多少
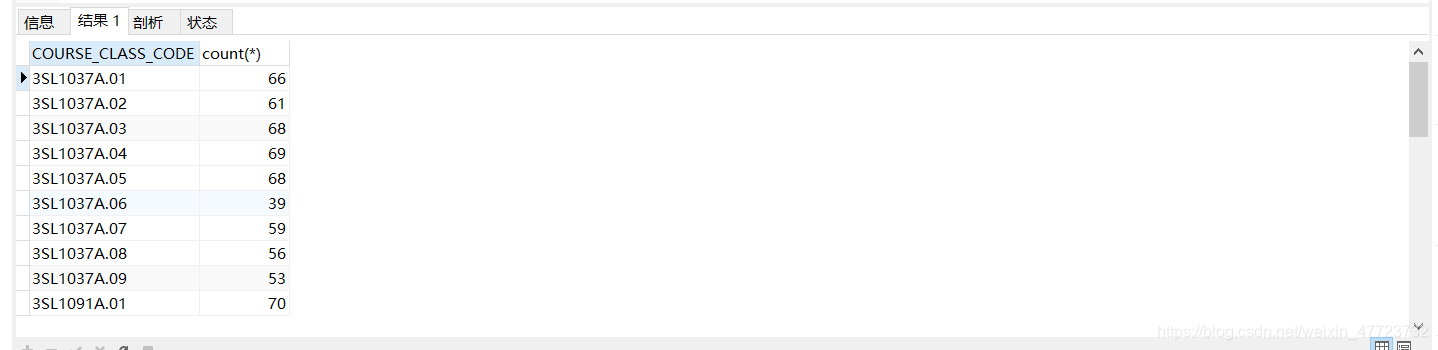
这里我们也想要输出每个班级的男女人数各是多少,应该怎么做,我把这个问题留给大家,欢迎大家到评论区留言,各抒己见,答案的方式不唯一!我们下期文章再会!!!
每文一语
时间的味道应该是清淡而细致,不应该是油腻且粗暴的,品味的是人生,而不是品味的是自己!
文章来源: blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_47723732/article/details/109497325

- 点赞
- 收藏
- 关注作者
评论(0)