关于深度学习的一些概念记录

【摘要】 前言 最近在学深度学习基础,想通过博客记录一些概念,从而达到总结和加深印象的目的。学习的书籍是《动手学深度学习》,对书本内容感兴趣的同学可以访问[动手学深度学习](https://github.com/ShusenTang/Dive-into-DL-PyTorch)# 误差## 训练误差和泛化误差**训练误差**:模型在训练数据集上表现出的误差。**泛化误差**:模型在任意一个测试数据样本上...
前言
最近在学深度学习基础,想通过博客记录一些概念,从而达到总结和加深印象的目的。学习的书籍是《动手学深度学习》,对书本内容感兴趣的同学可以访问[动手学深度学习](https://github.com/ShusenTang/Dive-into-DL-PyTorch)
# 误差
## 训练误差和泛化误差
**训练误差**:模型在训练数据集上表现出的误差。
**泛化误差**:模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来表示。
**误差计算**:损失函数。
**举例说明**:让我们以高考为例来直观地解释训练误差和泛化误差这两个概念。训练误差可以认为是做往年高考试题(训练题)时的错误率,泛化误差则可以通过真正参加高考(测试题)时的答题错误率来近似。假设训练题和测试题都随机采样于一个未知的依照相同考纲的巨大试题库。如果让一名未学习中学知识的小学生(未训练好的模型)去答题,那么测试题和训练题的答题错误率可能很相近。但如果换成一名反复练习训练题的高三备考生(训练完毕的模型)答题,即使在训练题上做到了错误率为0,也不代表真实的高考成绩会如此。
**机器学习模型应关注降低泛化误差。**
# 模型选择
## 验证数据集
**验证数据集**:进行模型选择时,预留一部分在训练数据集和测试数据集以外的数据。
**$K$折交叉验证**:改善当训练数据不够用时,预留大量的验证数据显得太奢侈情况的方法
**欠拟合**:指模型无法得到较低的训练误差
**过拟合**:指模型的训练误差远小于它在测试数据集上的误差
**模型复杂度**:
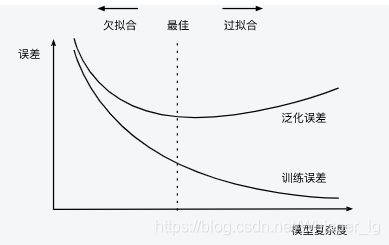
**应选择复杂度合适的模型并避免使用过少的训练样本**

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)