Gaussdb 100 分布式集群数据操作之route by

【摘要】 Gaussdb 100在集群部署下,支持通过路由规则将SQL语句发送给对应的DN节点执行,执行过程如下图所示:以下为访问示例(演示环境为三节点分布式集群)。新建路由规则DROP DISTRIBUTE RULE IF EXISTS enmo_muggle;CREATE DISTRIBUTE RULE enmo_muggle(key char(32) not null)AS LIST(key) ...
Gaussdb 100在集群部署下,支持通过路由规则将SQL语句发送给对应的DN节点执行,执行过程如下图所示: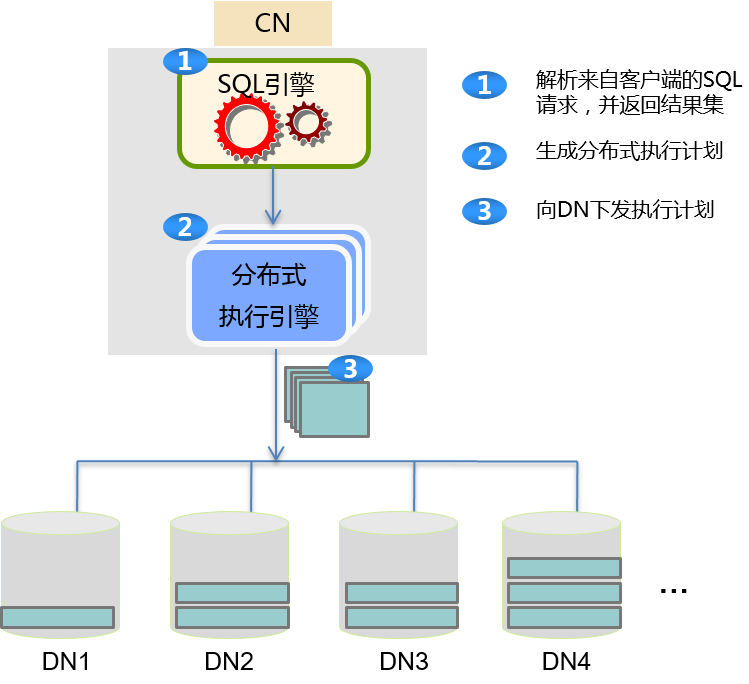
以下为访问示例(演示环境为三节点分布式集群)。
新建路由规则
DROP DISTRIBUTE RULE IF EXISTS enmo_muggle;
CREATE DISTRIBUTE RULE enmo_muggle(key char(32) not null)
AS LIST(key) (
groupid 1 values ('dn1'),
groupid 2 values ('dn2'),
groupid 3 values ('dn3')
);创建表
DROP TABLE IF EXISTS muggle;
CREATE TABLE muggle(id int, key char(32) not null) DISTRIBUTE BY
LIST(key)
(
groupid 1 values ('dn1'),
groupid 2 values ('dn2'),
groupid 3 values ('dn3')
);3.未设置路由规则,操作数据时,会自动将数据按(groupid)落盘至指定DN节点。
SQL> route by null; Succeed. SQL> SQL> INSERT INTO muggle VALUES(1, 'dn1'); 1 rows affected. SQL> INSERT INTO muggle VALUES(2, 'dn2'); 1 rows affected. SQL> INSERT INTO muggle VALUES(3, 'dn3'); 1 rows affected. SQL> commit; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 1 dn1 2 dn2 3 dn3 3 rows fetched. SQL> route by node 1; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 1 dn1 1 rows fetched. SQL> route by node 2; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 2 dn2 1 rows fetched. SQL> route by node 3; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 3 dn3 1 rows fetched. SQL>
指定路由规则名操作数据,则按路由规则名落盘数据。
SQL> ROUTE BY RULE enmo_muggle(key) VALUES('dn1');
Succeed.
SQL> INSERT INTO muggle VALUES(1, 'dn1');
1 rows affected.
SQL> ROUTE BY RULE enmo_muggle(key) VALUES('dn2');
Succeed.
SQL> INSERT INTO muggle VALUES(2, 'dn2');
1 rows affected.
SQL> ROUTE BY RULE enmo_muggle(key) VALUES('dn3');
Succeed.
SQL> INSERT INTO muggle VALUES(3, 'dn3');
1 rows affected.
SQL> commit;
Succeed.
SQL> route by node 1;
Succeed.
SQL> select * from muggle;
ID KEY
------------ --------------------------------
1 dn1
1 rows fetched.
SQL> route by node 2;
Succeed.
SQL> select * from muggle;
ID KEY
------------ --------------------------------
2 dn2
1 rows fetched.
SQL> route by node 3;
Succeed.
SQL> select * from muggle;
ID KEY
------------ --------------------------------
3 dn3
1 rows fetched.
SQL> route by null;
Succeed.
SQL> select * from muggle;
ID KEY
------------ --------------------------------
1 dn1
2 dn2
3 dn3
3 rows fetched.操作数据时,若指定按(groupid)节点ID,则数据落盘在指定的DN节点,操作数据不会按规则名进行落盘。
SQL> route by node 1; Succeed. SQL> insert into muggle values(1,'dn1'); 1 rows affected. SQL> insert into muggle values(2,'dn2'); 1 rows affected. SQL> insert into muggle values(3,'dn3'); 1 rows affected. SQL> commit; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 1 dn1 2 dn2 3 dn3 3 rows fetched. SQL> route by node 2; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 0 rows fetched. SQL> route by node 3; Succeed. SQL> select * from muggle; ID KEY ------------ -------------------------------- 0 rows fetched.
本文转自“墨天轮”社区GaussDB频道

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)