大数据——Hadoop 2.x 生态系统及技术架构图

【摘要】 一、负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大)二、负责存储数据的工具:HBaseMongoDBCassandraAccumuloMySqlOracleDB2HDFS(Hadoop Distribut File System)2.0三、底层组件Apache Common(通用模块)、A...
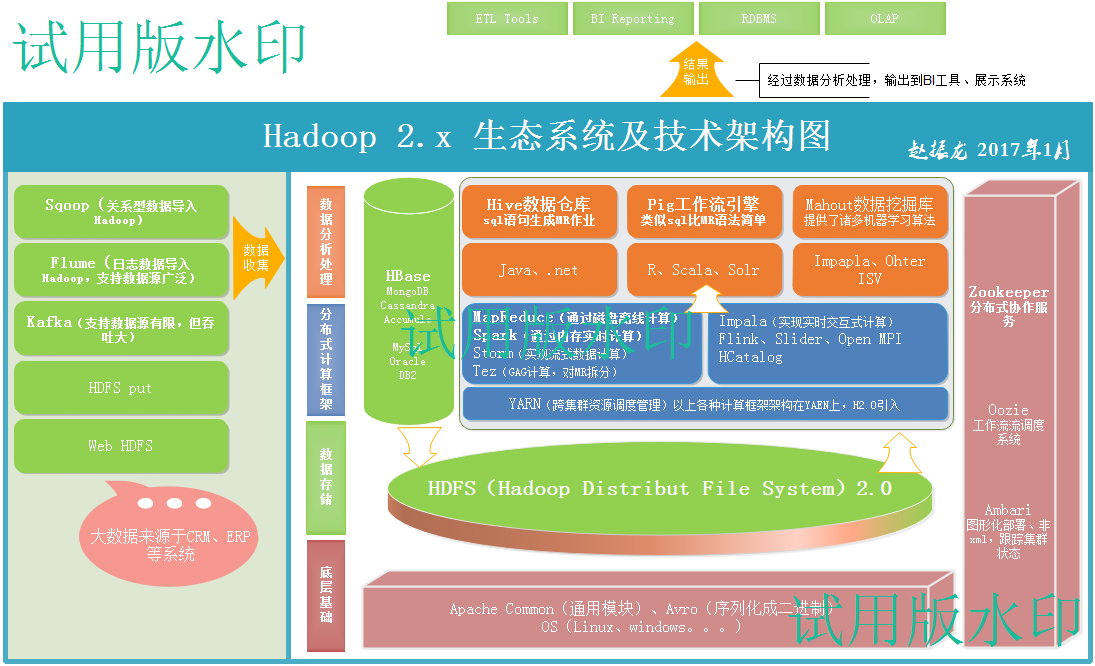
一、负责收集数据的工具:
Sqoop(关系型数据导入Hadoop)
Flume(日志数据导入Hadoop,支持数据源广泛)
Kafka(支持数据源有限,但吞吐大)
二、负责存储数据的工具:
HBase
MongoDB
Cassandra
Accumulo
MySql
Oracle
DB2
HDFS(Hadoop Distribut File System)2.0
三、底层组件
Apache Common(通用模块)、
Avro(序列化成二进制)、
OS(Linux、windows。。。)
四、通用工具
Zookeeper分布式协作服务
Oozie工作流流调度系统
Ambari图形化部署、非xml,跟踪集群状态
五、分布式计算框架
MapReduce(通过磁盘离线计算)
Spark(通过内存实时计算)
Storm(实现流式数据计算)
Tez(GAG计算,对MR拆分)
Impala(实现实时交互式计算)
Flink、Slider、Open MPI
HCatalog
YARN(跨集群资源调度管理)以上各种计算框架架构在YAEN上,H2.0引入
六、数据分析处理
Hive数据仓库
sql语句生成MR作业
Pig工作流引擎
类似sql比MR语法简单
Mahout数据挖掘库
提供了诸多机器学习算法
Java、.net
R、Scala、Solr
Impapla、Ohter ISV
七、结果输出
经过数据分析处理,输出到BI工具、展示系统
ETL Tools
BI Reporting
RDBMS
OLAP

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)