大数据——spark streaming 与 storm 的对比

最近一段时间由于公司项目的需要,调研了一下storm和spark streaming,并进行了一个简单的对比,下面从以下几个方面给大家做个简单分享
前言
由于公司的业务增长及大数据在互联网金融风控的普及,公司开始使用大数据进行相关风控规则的计算及模型训练,在此背景下,数据平台组这边进行了一次大数据实时计算相关技术的调研及试运行,在此把其中的storm和spark streaming的相关对比分享给大家,希望给大家带来帮助
storm 集群架构图
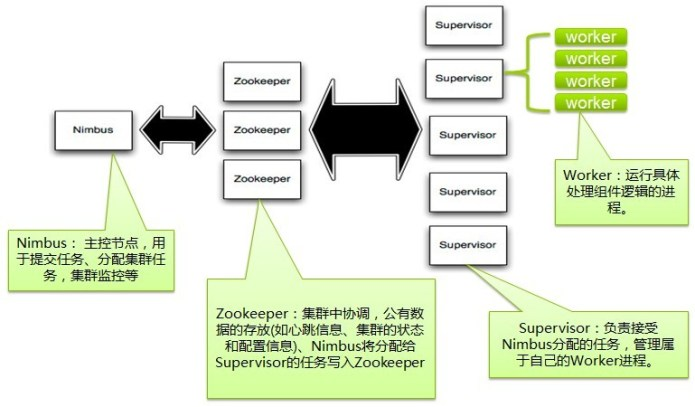
storm 集群相关术语介绍
集群的物理机可以分为master节点和Supervisor节点,master,Supervisor说的是集群节点的角色,Worker是在集群节点上面运行的进程,executor是worker上的物理线程,Task是执行计算逻辑的线程,这个前提先搞清楚,下面是各组件作用
Nimbus :Storm集群的master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker进程,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor:Storm集群的从节点,负责管理运行在Supervisor节点上的Worker进程的启动和终止;通过Storm的配置文件中的supervisor.slots.ports配置项可以指定一个Supervisor节点上最大允许多少个Slot(所谓slot就是可用的worker进程),每个Slot(槽)就是一个JVM,就是一个Worker进程。
Worker:运行executor,executor是一个物理线程,一个Worker可以运行一个或者多个executor。
Task:每一个spout/bolt的线程称为一个Task,在storm0.8之后,task不再与物理线程(executor)对应,不同的spout/bolt可能共享一个物理线程(executor)。
Zookeeper:用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology中的组件,Nimbus会第一时间感知到,并重新分配组件到其他可用的Supervisor上运行
在上面的组件中,worker,executor,task(spout/bolt)的关系容易混,通过下图可以清楚的看懂(图是storm0.8之前的图,storm0.8以后是不同的(spout/bolt)task实例可以共享一个物理线程(executor))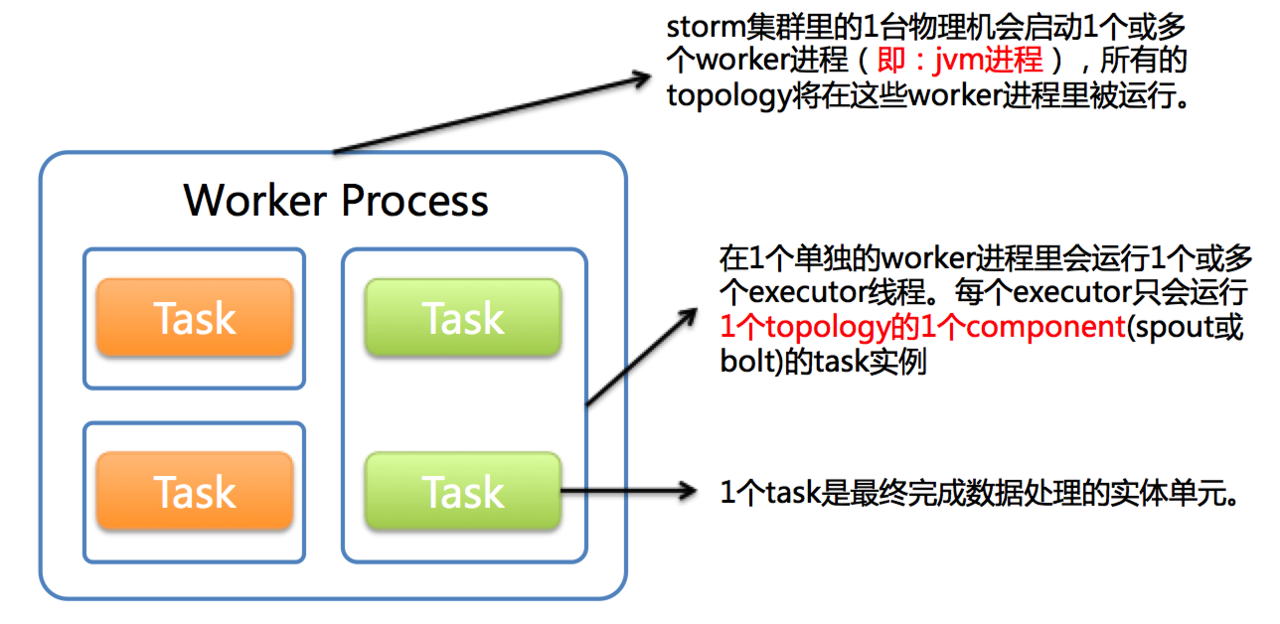
spark 集群架构图
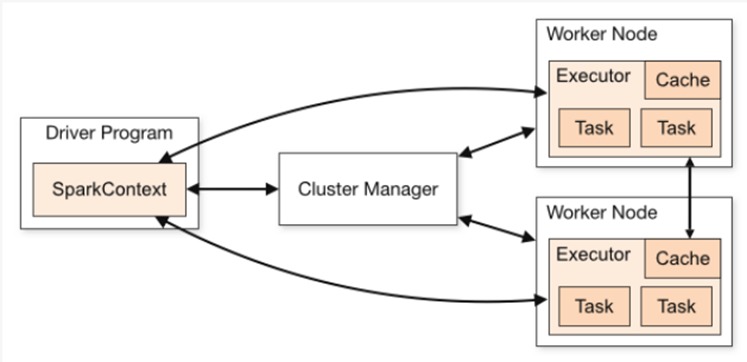
spark 相关术语的介绍
Application:用户编写的Spark应用程序
Driver:运行上述Application的main()函数创建SparkContext,由架构图也可以看出在Spark中由Driver创建的SparkContext负责和ClusterManager进行通信,进行资源的申请,任务的分配,任务的监控等,当Executor运行完毕后,Driver负责将SparkContext关闭。由于大部分功能都是有Driver创建的SparkContext完成,所以通常用SparkContext代表Driver;
Worker:相当于集群的计算节点,在Worker节点上可以运行一个或者多个Executor进程
Executor:运行在Worker 节点上的一个进程,该进程负责执行Task,并且负责将数据存在内存或者磁盘上,一个Worker默认情况下分配一个Executor,根据需要也可以在worker上运行多个Executor。一个节点,如果配置了多个Executor,那么就会涉及到性能调优。
Task:逻辑计算单元,一个executor里面可以运行很多Task线程
注意:这个spark的Executor是进程,在storm中,同样的名字(executor)是个物理线程
storm 和 spark streaming 在实时性,吞吐量等方面的对比
1、实时性:一般Storm的时延性比spark streaming要低,原因是Spark Streaming是小的批处理,通过间隔时长生成批次,一个批次触发一次计算,比如我在程序里面设置间隔时长为5秒,那就是五秒接收到的数据触发一次计算,Storm是实时处理,来一条数据,触发一次计算,所以可以称spark streaming为流式计算,Storm 为实时计算,阿里的JStorm通过实现Trident,也支持小的批处理计算
2、吞吐量 :Storm的吞吐量要略差于Spark Streaming,原因一是Storm从spout组件接收源数据,通过发射器发送到bolt,bolt对接收到的数据进行处理,处理完以后,写入到外部存储系统中或者发送到下个bolt进行再处理,所以storm是移动数据,不是移动计算;Spark Streaming获取Task要计算的数据在哪个节点上,然后TaskScheduler把task发送到对应节点上进行数据处理,所以Spark Streaming是移动计算不是移动数据,移动计算也是当前计算引擎的主流设计思想;原因二大家很容易看出来,一个是批处理,一个是实时计算,批处### 理的吞吐量一般要高于实时触发的计算
3、容错机制:storm是acker(ack/fail消息确认机制)确认机制确保一个tuple被完全处理,Spark Streaming是通过存储RDD转化逻辑进行容错,也就是如果数据从A数据集到B数据集计算错误了,由于存储的有A到B的计算逻辑,所以可以从A重新计算生成B,容错机制不一样,暂时无所谓好坏
storm 和 spark streaming 的使用建议(只是建议,不做参考)
1、在那种需要纯实时的场景下使用Storm
2、由于Storm可以动态调整实时计算程序的并行度,所以在需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况)的情况下,考虑用Storm,比如用命令行动态调整并行度
storm rebalance mytopology -w 10 -n 2 -e spout=2 -e bolt=2
表示 10秒之后对mytopology进行并行度调整。把worker调整为两个,spout调整为2个executor,把bolt调整为2个executor3、复杂的实时计算逻辑选用Spark Streaming
4、Spark Streaming有一点是Storm绝对比不上的,那就是spark提供了一个统一的解决方案,在一个集群里面可以进行离线计算,流式计算,图计算,机器学习等,而storm集群只能单纯的进行实时计算

- 点赞
- 收藏
- 关注作者
评论(0)