一篇文章搞定前端面试

本文旨在用最通俗的语言讲述最枯燥的基本知识
面试过前端的老铁都知道对于前端面试官喜欢一开始先问些HTML5新增元素啊特性啊或者是js闭包啊原型啊或者是css垂直水平居中怎么实现啊之类的基础问题当你能倒背如流的回答这些之后面试官脸上会划过一丝诡异的笑容然后晴转多云故作深沉的清一下嗓子问**从用户输入URL到浏览器呈现页面经过了哪些过程**如果你懂巴拉巴拉回答了一堆他又接着问**那网页具体是如何渲染出来的呢**如果你还懂又巴拉巴拉的回答了一堆他还会继续问**那你有哪些网页性能优化的经验呢**当你还能巴拉巴拉的回答了一堆之后面试官这下心里就有逼数了转而去问你一些和技术无关的七大姑八大姨之类的事情这时候你就可以欢呼你的offer基本已经到手了。
那么各位问题来了真正轮到你去面试的时候 你能否很好的回到这些问题呢
用户输入URL回车之后浏览器到底做了啥
页面渲染的完整流程是怎样的
前端性能优化有哪些经验
如果不能那我们往下走 有人会疑惑说不是讲前端吗为毛要讲TCP、DNS这些与前端无关的知识?别慌咯跟着文章走吧多学无害
文章提纲 1. TCP 2. UDP 3. 套接字socket 4. HTTP协议 5. DNS解析 6. HTTP请求发起和响应 7. 页面渲染的过程 8. 页面的性能优化
TCP连接
TCPTransmission Control Protocol 传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议。 说的这么专业有啥用呢 先来举个栗子吧 还记得小时候我们做的纸杯电话么两个纸杯用一条绳子连到一起两个各拿一个纸杯把线拉直一个对着纸杯讲一个用耳朵对着纸杯听。
这其实就是一种最简单的连接通信两人通过一根线连接起来声音从这边的纸杯发出通过线传输到另一个纸杯接收扩展到现在家家户户都有的固定电话也是如此它的通信也是建立在双方可接受并且信任的基础上进行如
A拿起电话拨通0775-6532122开始呼叫B
B听到电话声响起拿起电话此时A收到B已经拿起电话的声音
双方开始讲话。
回到我们的tcp协议其实它和上面所说的电话协议差不多只不过电话的协议是服务于电话通信而tcp是服务于网络通讯的一种协议类似的通讯双方建立一次tcp连接也需要经过三个步骤握手。
客户端发送syn包(syn=j)到服务器并进入SYN_SEND状态等待服务器确认。
服务器收到syn包必须确认客户的SYNack=j+1同时自己也发送一个SYN包syn=k即SYN+ACK包此时服务器进入SYN_RECV状态。
客户端收到服务器的SYNACK包向服务器发送确认包ACK(ack=k+1)此包发送完毕客户端和服务器进入ESTABLISHED状态完成三次握手。

上面几个唧唧歪歪的英文看的有点懵逼翻译一下吧 (大家最好记一下这些状态码在服务器连接数的性能优化中会经常用到)
SYN:synchronous 建立联机 ACK:acknowledgement 确认 SYN_SENT:请求连接
SYN_RECV:服务端被动打开后,接收到了客户端的SYN并且发送了ACK时的状态。再进一步接收到客户端的ACK就进入ESTABLISHED状态。
值得注意的是tcp在握手过程中并不携带数据(就像你打电话给酒店订房时在确认对方是酒店客服人员之前你也不会马上把身份证号***给他吧)而是在三次握手完成之后才会进行数据传送。
至于它的应用场景其实是根据它本身的特点而定的比如对网络通讯质量有要求需要保证数据准确性时就需要用到TCP协议了如HTTP、ftp等文件传输协议、或一些邮件传输协议SMTP、pop等
UDP协议
(UDP协议并非本文需要重点着笔的内容但是讲到TCP了作为他的互补兄弟在此掠过一笔)
UDP User Datagram Protocol 用户数据报协议 相比于TCP的面向连接需要反复确认的繁琐步骤UDP是一中性格特立独行并且主观性超强的非面向连接的协议使用udp协议经常通信并不需要建立连接它只是负责把数据尽可能快的发送出去简单粗暴并且不可靠而在接收端UDP把每个消息断放入队列中接收端程序从队列中读取数据。
有人会说UDP协议这么不可靠为啥还会造出来呢 话说回来天底下没有无用之人只有你不懂用的人而已虽然UDP不可靠但是它的传输速度快效率高在一些对数据准确性要求不高的场景UDP就变得很有用了比如qq语音、qq视频。
套接字socket
为什么要说嵌套字 那是因为就像前面说的TCP或UDP都是一种协议也就是计算机网络通信中在传输层的一种协议简单地说就是一种约定就像合作双方的合同一样然后合同是死的只有履行合同才是实质性的行动因此无论是TCP还是UDP要产生作用都需要有实际的行为去执行才能体现协议的作用 那么有什么办法让这些协议作用呢 这就要说到socket了。
socket也叫嵌套字 是一组实现TCP/UDP通信的接口API也就是说无论TCP还是UDP通过对scoket的编程都可以实现TCP/UCP通信作为一个通信链的句柄它包含网络通信必备的5种信息
连接使用的协议
本地主机的IP地址
本地进程的协议端口
远地主机的IP地址
远地进程的协议端口
可见socket包含了通信本方和对方的ip和端口以及连接使用的协议TCP/UDP。通信双方中的一方暂称客户端通过scoket嵌套字对另一方暂称服务端发起连接请求服务端在网络上监听请求当收到客户端发来的请求之后根据socket里携带的信息定位到客户端就相应请求把socket描述发给客户端双方确认之后连接就建立了。 因此套接字之间的连接过程有三个步骤
服务器监听:服务器实时监控网络状态等待客户端发来的连接请求
客户端请求:客户端根据远程主机服务器的IP地址和协议端口向其发起连接请求
连接确认:服务端收到套接字的连接请求之后就响应请求把服务端套接字描述发给客户端客户端收到后一旦确认则双方建立连接进行数据交互。
通常情况下socket连接就是TCP连接因此socket连接一旦建立,通讯双方开始互发数据进行通信直到其中一方或双方断开连接为止。
socket在即时通讯qq等各种聊天软件等应用上应用广泛。
HTTP协议
HTTP协议Hypertext Transfer Protocol 也叫超文本传送协议 它是一种基于TCP/IP协议栈、在表示层和应用层上的协议TCP在传输层的协议通俗一点说就是
TCP/IP是位于传输层上的一种协议用于在网络中传输数据
HTTP协议是应用层协议基于TCP协议用于包装数据程序使用它进行通信可以简单高效的处理通信中数据的传输和识别处理
而在现在应用非常广泛的HTTP连接则是建立在HTTP协议上的、处于应用层中的一种具体应用。 上面说到socket连接一旦建立就保持连接状态而HTTP连接则不一样它基于tcp协议的短连接也就是客户端发起请求服务器响应请求之后连接就会自动断开不会一直保持。
URL
前面讲了tcp、udp、http...等等都是为了讲一个具体问题而做的知识点铺垫那就是我们开发的web应用中请求的发起和响应是一个怎样的底层原理。 我们都知道web应用绝大部分都是通过HTTP来进行请求的而URL则是HTTP用来做连接建立和传输数据的一种具体实现因此在此要简单讲一下URL。
URLUniform Resource Locator 统一资源定位符。说白了就是网络上用来标识具体资源的一个地址包含了用户查找该资源的信息HTTP使用它来传输数据和建立连接 一个URL有以下组成部分
协议
服务器地址域名或IP+端口
路径
文件名
比如https://www.baidu.com/index.html 其中
https://是一种协议 当然HTTP也是 ftp也是...
www.baidu.com是服务器地址当然你知道百度的IP也可以,例如我用ping命令得到百度的ip 14.215.177.39那么我可以用http://14.215.177.39打开百度
index.html包含了路径和文件名当然通常index.html是可以省略的所以你打开百度时并没有看到这个。
DNS
DNS:Domain Name Server域名服务器。 是进行域名(domain name)和与之相对应的IP地址 (IP address)转换的服务器。DNS中保存了一张域名(domain name)和与之相对应的IP地址 (IP address)的表以解析消息的域名。 在平时我们进行开发时后端提供的接口地址通常是有IP地址加上端口号8080什么鬼的组成的但是当我们把网站发布出去时通常都需要把IP改成用域名。 为什么呢 你想想哦比如谷歌的地址是89.12.21.221:9090,百度的地址是132.21.33.221:8766。。。 这么一看你根本没有欲望是记住这些乱七八糟的数字吧 但是域名就不一样了比如谷歌的google.com百度的baidu.com 是不是一遍就记住了呢 所以为了处理这个问题就需要用域名去映射IP地址达到易记易用的目的。
因此当用户在浏览器输入https://www.baidu.com回车时它经历了以下步骤
浏览器根据地址去本身缓存中查找dns解析记录如果有则直接返回IP地址否则浏览器会查找操作系统中hosts文件是否有该域名的dns解析记录如果有则返回。
如果浏览器缓存和操作系统hosts中均无该域名的dns解析记录或者已经过期此时就会向域名服务器发起请求来解析这个域名。
请求会先到LDNS本地域名服务器让它来尝试解析这个域名如果LDNS也解析不了则直接到根域名解析器请求解析
根域名服务器给LDNS返回一个所查询余的主域名服务器gTLDServer地址。
此时LDNS再向上一步返回的gTLD服务器发起解析请求。
gTLD服务器接收到解析请求后查找并返回此域名对应的Name Server域名服务器的地址这个Name Server通常就是你注册的域名服务器比如阿里dns、腾讯dns等
Name Server域名服务器会查询存储的域名和IP的映射关系表正常情况下都根据域名得到目标IP记录连同一个TTL值返回给DNS Server域名服务器
返回该域名对应的IP和TTL值Local DNS Server会缓存这个域名和IP的对应关系缓存的时间有TTL值控制。
把解析的结果返回给用户用户根据TTL值缓存在本地系统缓存中域名解析过程结束。
HTTP请求发起和响应
如果这篇文章的主题是网络通信那到这里已经可以告一段落了但今天我们要讲的是web应用中请求的发起和响应以及页面渲染的原理因此以上只是铺垫。 在一个web程序开发中一般都有前端和后端之分前端负责向后端请求数据和展示页面后端负责接收请求和做出响应发回给前端他们之间的协作的桥梁是什么呢 是API API是什么不就是一个URL吗 URL又是啥呢上面说到就是HTTP连接的一种具体的载体 因此 无论对于前端或者是后端理解HTTP无论是对自身对编程的理解还是和同事协作都是好处大大的 下面根据上面各个知识点的理解我们来整理一下并解决一下上面提到的第一个问题 从用户输入URL到浏览器呈现给用户页面经过了什么过程
用户输入URL浏览器获取到URL
浏览器(应用层)进行DNS解析如果输入的是IP地址此步骤省略
根据解析出的IP地址+端口浏览器应用层发起HTTP请求请求中携带请求头header也可细分为请求行和请求头、请求体body
header包含 1. 请求的方法get、post、put.. 2. 协议http、https、ftp、sftp... 3. 目标url具体的请求路径已经文件名 4. 一些必要信息缓存、cookie之类
body包含 1. 请求的内容
请求到达传输层tcp协议为传输报文提供可靠的字节流传输服务它通过三次握手等手段来保证传输过程中的安全可靠。通过对大块数据的分割成一个个报文段的方式提供给大量数据的便携传输。
到网络层 网络层通过ARP寻址得到接收方的Mac地址IP协议把在传输层被分割成一个个数据包传送接收方。
数据到达数据链路层请求阶段完成
接收方在数据链路层收到数据包之后层层传递到应用层接收方应用程序就获得到请求报文。
接收方收到发送方的HTTP请求之后进行请求文件资源如HTML页面的寻找并响应报文
发送方收到响应报文后如果报文中的状态码表示请求成功则接受返回的资源如HTML文件进行页面渲染。
页面的渲染
当一个请求的发起和响应都完成之后浏览器就会收到响应内容但浏览器收到的是一串串的代码或URL链接怎么把这些代码转化成用户可以看得懂的界面呈现出来就是浏览器的工作了。 目前市场上的浏览器已经不下百种各个浏览器根据内核又可以分成几大类每一类浏览器对页面的渲染原理和过程有所差异。
但总的来说各个浏览器渲染页面都基本遵循如下图的流程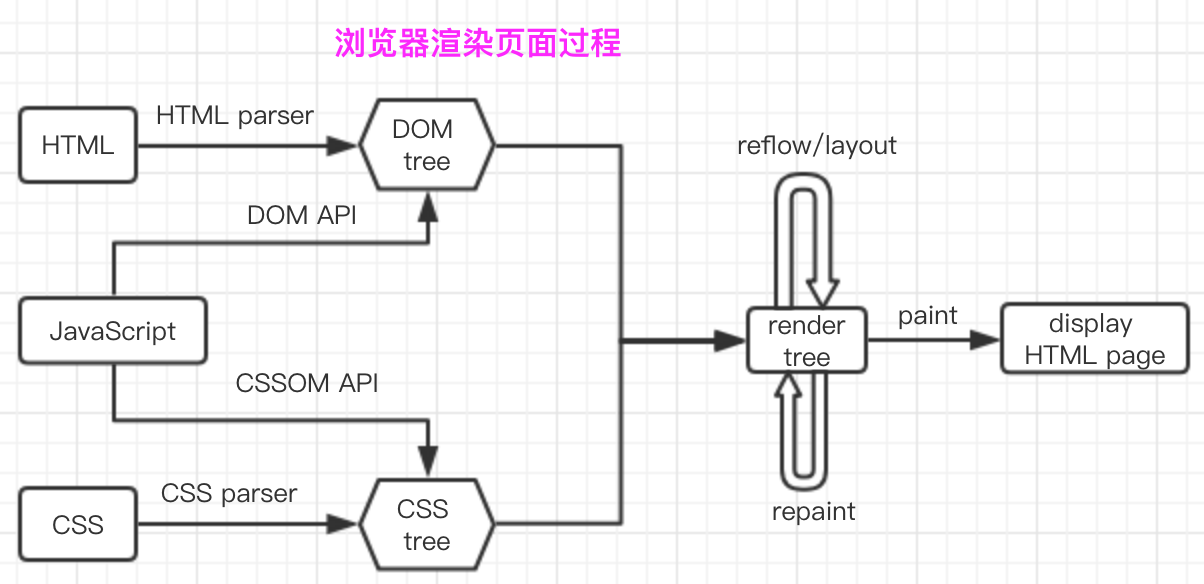
图中有几处英文词汇可能不好理解没关系先做一下解释
HTML parserHTML解析器其本质是将HTML文本解释成DOM tree。
CSS parserCSS解析器其本质是讲DOM中各元素对象加入样式信息
JavaScript引擎专门处理JavaScript脚本的虚拟机其本质是解析JS代码并且把逻辑HTML和CSS的操作应用到布局中从而按程序要的要求呈现相应的结果
DOM tree:文档对象模型树也就是浏览器通过HTMLparser解析HTML页面生成的HTML树状结构以及相应的接口。
render tree渲染树也就是浏览器引擎通过DOM Tree和CSS Rule Tree构建出来的一个树状结构和dom tree不一样的是它只有要最终呈现出来的内容像或者带有display:none的节点是不存在render tree中的。
layout也叫reflow 重排渲染中的一种行为。当rendertree中任一节点的几何尺寸发生改变了render tree都会重新布局。
repaint重绘渲染中的一种行为。render tree中任一元素样式属性几何尺寸没改变发生改变了render tree都会重新画比如字体颜色、背景等变化。
所以根据关键词汇的解释以及顺着流程图的流程可以总结出浏览器解析渲染页面主要包括以下过程
浏览器通过HTMLParser根据深度遍历的原则把HTML解析成DOM Tree。
将CSS解析成CSS Rule TreeCSSOM Tree。
根据DOM树和CSSOM树来构造render Tree。
layout根据得到的render tree来计算所有节点在屏幕的位置。
paint遍历render树并调用硬件图形API来绘制每个节点。
前端性能优化
对于页面渲染基本上这样就是一个的流程看完之后有没有什么感觉在实际编码中可以优化的点呢没有吧因为很多细节都没有讲述因此为了找到可优化的点在此对页面渲染过程的几个关键步骤做一下陈述
1. HTML解析
上面讲到HTML解析是浏览器的HTML解析器把HTML解析成dom tree而在解析过程浏览器根据HTML文件的结构从上到下解析htmlHTML元素是以深度优先的方式解析而script、link、style等标签会使解析过程产生阻塞阻塞的情况有
外部样式会阻塞内部脚本的执行。
外部样式与外部脚本并行加载但外部样式会阻塞外部脚本执行。
如果外部脚本带有async属性则外部脚本的加载与执行不受外部样式影响
如果link标签是动态创建js生成不管有无async属性都不会阻塞外部脚本的加载与执行。
2. CSS解析:
CSS Parser作用就是将很多个CSS文件中的样式合并解析出具有树形结构Style Rules在对样式解析的过程中默认CSS选择器是从右往左进行解析的。至于为什么是从右到左而不是从左到右、也是不会从左到左... 下面举个栗子来说一下 假如现在有这样的一个样式:
#parent .ch1 .dh1 {}
.fh1 .ch1 .dh1{}
.ah1 .ch1 .eh1 {}
#parent .fh1 {}
.ch1 .dh1{}我们来比较从左到右和从右到左两种方式的结果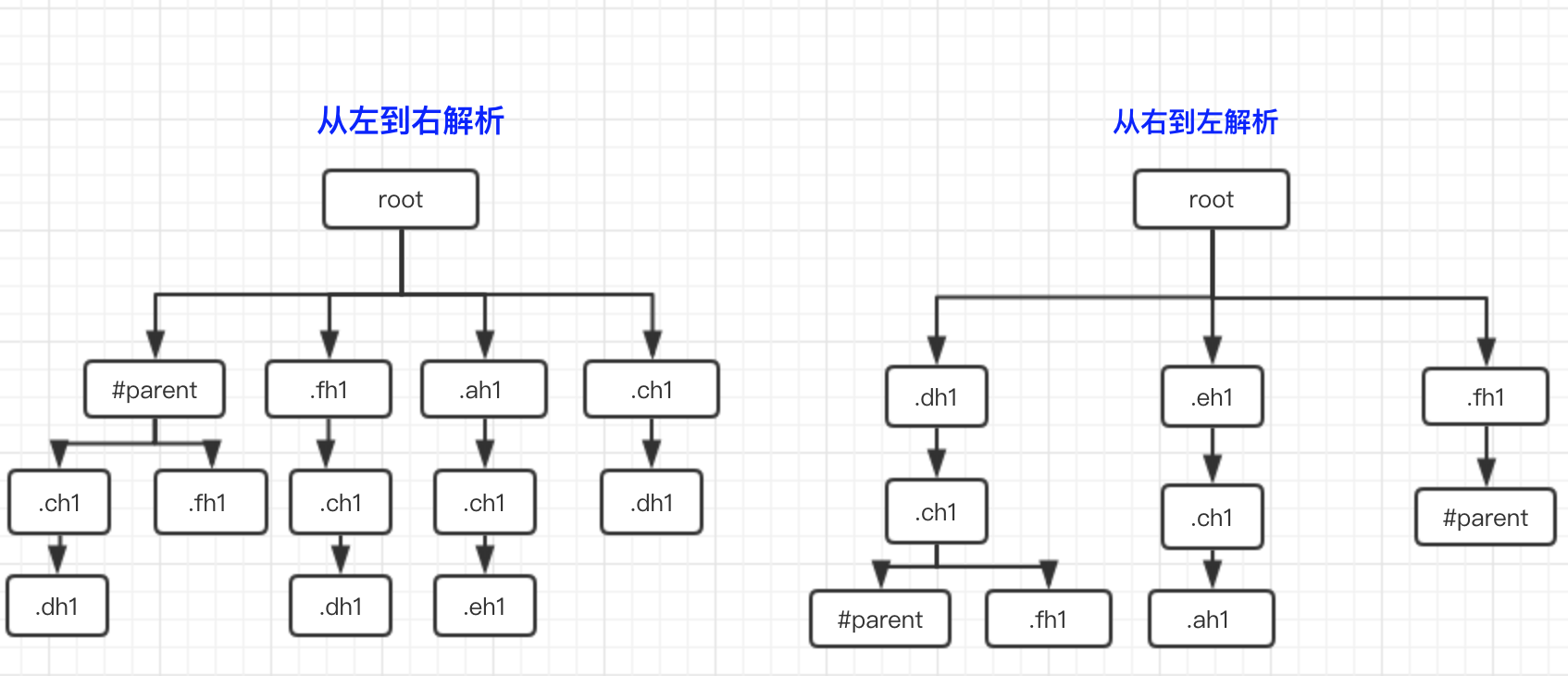 从两个图的比较就可以看几点
从两个图的比较就可以看几点
右边的tree复杂度要比左边的低
右边的tree公用样式重合度比左边的低
右边的tree从根开始的节点数要比左边的少
可能光看这几点没看出什么问题但你要知道浏览器中的css解析器负责css的解析并为每个节点计算出样式因此虽然css解析器要做的事情不多但要每个节点都要进行遍历查找计算计算量极大因此解析的方式是决定其性能的关键点。 就如
#parant .a{}
和
.a{}估计绝大多数人都会认为前者要比后者性能更优其实不然在解析过程中 #paran .a{}意味着css解析器要先找到#parent再找到他下面的.a所在节点 而后者可以直接定位到.a{}因此哪一种方式更优显而易见。
3. 脚本执行:
浏览器解析HTML时当遇到 script标签就会立即解析脚本同时阻塞解析文档直到脚本执行完毕你可能问为什么要这样设计明显啊脚本的执行是改变css和dom会造成render tree不停的重绘和重排的而当script是引入外部js文件时会阻塞到js文件下载完成并且执行完成为止除非加了defer或者async属性。脚本在解析过程中将对dom或css的操作解析出来加入到DOM Tree和cssom中。
性能优化
把这些度讲完之后对于性能优化的点相信大家心里都有点X数了吧下面简单总结一下日常开发过程中常用的性能优化的地方
1.对于css
优化选择器路径健全的css选择器固然是能让开发看起来更清晰然后对于css的解析来说却是个很大的性能问题因此相比于 .a .b .c{} 更倾向于大家写.c{}。
压缩文件尽可能的压缩你的css文件大小减少资源下载的负担。
选择器合并把有共同的属性内容的一系列选择器组合到一起能压缩空间和资源开销
精准样式尽可能减少不必要的属性设置比如你只要设置{padding-left:10px}的值,那就避免{padding:0 0 0 10px}这样的写法
雪碧图在合理的地方把一些小的图标合并到一张图中这样所有的图片只需要一次请求然后通过定位的方式获取相应的图标这样能避免一个图标一次请求的资源浪费。
避免通配符.a .b *{} 像这样的选择器根据从右到左的解析顺序在解析过程中遇到通配符*回去遍历整个dom的这样性能问题就大大的了。
少用Float:Float在渲染时计算量比较大尽量减少使用。
0值去单位对于为0的值尽量不要加单位增加兼容性
2.对于JavaScript
尽可能把script标签放到body之后避免页面需要等待js执行完成之后dom才能继续执行最大程度保证页面尽快的展示出来。
尽可能合并script代码
css能干的事情尽量不要用JavaScript来干。毕竟JavaScript的解析执行过于直接和粗暴而css效率更高。
尽可能压缩的js文件减少资源下载的负担
尽可能避免在js中逐条操作dom样式尽可能预定义好css样式然后通过改变样式名来修改dom样式这样集中式的操作能减少reflow或repaint的次数。
尽可能少的在js中创建dom而是预先埋到HTML中用display:none来隐藏在js中按需调用减少js对dom的暴力操作。
3. 对于HTML
避免再HTML中直接写css代码。
使用Viewport加速页面的渲染。
使用语义化标签减少css的代码增加可读性和SEO。
减少标签的使用dom解析是一个大量遍历的过程减少无必要的标签能降低遍历的次数。
避免src、href等的值为空。
减少dns查询的次数。
以上就是文章的所有内容总的来说入门的文章是领人入门进阶的文章带人进阶就像Java的书会有入门教程和进阶教程一样这个文章里边写的大部分知识点都是为了让读者对页面请求和呈现有一个铺垫和整体的认知由于涉及的知识点过多每个知识点拎出来都可以写一本书所以大家把本文作为一个引路文需要对某个知识点进行深入研究时再找相关书籍研究不喜勿喷。
本文转载自异步社区
原文链接https://www.epubit.com/articleDetails?id=N63bc296f-59f7-44a3-9b1d-a1fad7f8ddb3

- 点赞
- 收藏
- 关注作者
评论(0)