神经网络基础

人工神经网络表示一类机器学习的模型,最初是受到了哺乳动物中央神经系统研究的启发。网络由相互连接的分层组织的神经元组成,这些神经元在达到一定条件时就会互相交换信息(专业术语是激发(fire))。最初的研究开始于20世纪50年代后期,当时引入了感知机(Perceptron)模型(更多信息请参考文章《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》,作者F. Rosenblatt,Psychological Review,vol. 65,pp. 386~408,1958)。感知机是一个可以实现简单操作的两层网络,并在20世纪60年代后期引入反向传播算法(backpropagation algorithm)后得到进一步扩展,用于高效的多层网络的训练(据以下文章《Backpropagation through Time: What It Does and How to Do It》,作者P. J. Werbos,Proceedings of the IEEE, vol. 78,pp. 1550~1560,1990;《A Fast Learning Algorithm for Deep Belief Nets》,作者G. E. Hinton,S. Osindero,Y. W. Teh,Neural Computing,vol. 18,pp. 1527~1554,2006)。有些研究认为这些技术起源可以追溯到比通常引述的更早的时候(更多信息,请参考文章《Deep Learning in Neural Networks: An Overview》,作者J. Schmidhuber,Neural Networks,vol. 61,pp. 85~117,2015)。直到20世纪80年代,人们才对神经网络进行了大量的学术研究,那时其他更简单的方法正变得更加有用。然后,由于G.Hinton提出的快速学习算法(更多信息,请参考文章《The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting》,作者S. Leven,Neural Networks,vol. 9,1996;《Learning Representations by Backpropagating Errors》,作者D. E. Rumelhart,G. E. Hinton,R. J. Williams,Nature,vol. 323,1986),以及2011年前后引入GPU后使大量数值计算成为可能,开始再度出现了神经网络研究的热潮。
这些进展打开了现代深度学习的大门。深度学习是以一定数量网络层的神经元为标志的神经网络,它可以基于渐进的层级抽象学习相当复杂的模型。几年前,3~5层的网络就是深度的,而现在的深度网络已经是指100~200层。
这种渐进式抽象的学习模型,模仿了历经几百万年演化的人类大脑的视觉模型。人类大脑视觉系统由不同的层组成。我们人眼关联的大脑区域叫作初级视觉皮层V1,它位于大脑后下方。视觉皮层为多数哺乳动物所共有,它承担着感知和区分视觉定位、空间频率以及色彩等方面的基本属性和微小变化的角色。据估计,初级视觉层包含了1亿4000万个神经元,以及100亿个神经元之间的连接。V1层随后和其他视觉皮层V2、V3、V4、V5和V6连接,以进一步处理更复杂的图像信息,并识别更复杂的视觉元素,如形状、面部、动物等。这种分层组织是1亿年间无数次尝试的结果。据估计,人类大脑包含大约160亿个脑皮质神经细胞,其中10%~25%是负责视觉信息处理的(更多信息,请参考文章《The Human Brain in Numbers: A Linearly Scaled-up Primate Brain》,作者 S. Herculano-Houzel,vol. 3,2009)。深度学习就是从人类大脑视觉系统的层次结构中获得了启发,前面的人工神经网络层负责学习图像基本信息,更深的网络层负责学习更复杂的概念。
本书涵盖了神经网络的几个主要方面,并提供了基于Keras和最小有效Python库作为深度学习计算的可运行网络实例编码,后端基于谷歌的TensorFlow或者蒙特利尔大学的Theano框架。
好的,让我们切入正题。
在本章,我们将介绍以下内容:
感知机
多层感知机
激活函数
梯度下降
随机梯度下降
反向传播算法
1.1 感知机
感知机是一个简单的算法,给定n维向量x(x1, x2, …, xn)作为输入,通常称作输入特征或者简单特征,输出为1(是)或0(否)。数学上,我们定义以下函数:

这里,w是权重向量,wx是点积(译者注:也称内积、数量积或标量积) ,b是偏差。如果你还记得基础的几何知识,就应该知道wx+b定义了一个边界超平面,我们可以通过设置w和b的值来改变它的位置。如果x位于直线之上,则结果为正,否则为负。非常简单的算法!感知机不能表示非确定性答案。如果我们知道如何定义w和b,就能回答是(1)或否(0)。接下来我们将讨论这个训练过程。
,b是偏差。如果你还记得基础的几何知识,就应该知道wx+b定义了一个边界超平面,我们可以通过设置w和b的值来改变它的位置。如果x位于直线之上,则结果为正,否则为负。非常简单的算法!感知机不能表示非确定性答案。如果我们知道如何定义w和b,就能回答是(1)或否(0)。接下来我们将讨论这个训练过程。
第一个Keras代码示例
Keras的原始构造模块是模型,最简单的模型称为序贯模型,Keras的序贯模型是神经网络层的线性管道(堆栈)。以下代码段定义了一个包含12个人工神经元的单层网络,它预计有8个输入变量(也称为特征):

每个神经元可以用特定的权重进行初始化。Keras提供了几个选择,其中最常用的选择如下所示。
random_uniform:初始化权重为(–0.05,0.05)之间的均匀随机的微小数值。换句话说,给定区间里的任何值都可能作为权重。
random_normal:根据高斯分布初始化权重,平均值为0,标准差为0.05。如果你不熟悉高斯分布,可以回想一下对称钟形曲线。
zero:所有权重初始化为0。
完整选项列表请参考Keras官网。
1.2 多层感知机——第一个神经网络的示例
在本章中,我们将定义一个多层线性网络,并将其作为本书的第一个代码示例。从历史上来看,感知机这个名称是指具有单一线性层的模型,因此,如果它有多层,我们就可以称之为多层感知机(Multilayer perceptron,MLP)。图1.1展示了一个一般的神经网络,它具有一个输入层、一个中间层和一个输出层。

图1.1
在图1.1中,第一层中的每个节点接收一个输入,并根据预设的本地决策边界值确定是否激发。然后,第一层的输出传递给中间层,中间层再传递给由单一神经元组成的最终的输出层。有趣的是,这种分层组织似乎模仿了我们前面讨论过的人类的视觉系统。
全连接的网络是指每层中的每个神经元和上一层的所有神经元有连接,和下一层的所有神经元也都有连接。
1.2.1 感知机训练方案中的问题
让我们来考虑一个单一的神经元如何选择最佳的权重w和偏差b?理想情况下,我们想提供一组训练样本,让机器通过调整权重值和偏差值,使输出误差最小化。为了更加的具体,我们假设有一组包含猫的图像,以及另外单独的一组不包含猫的图像。为了简单起见,假设每个神经元只考虑单个输入像素值。当计算机处理这些图像时,我们希望我们的神经元调整其权重和偏差,使得越来越少的图像被错误识别为非猫。这种方法似乎非常直观,但是它要求权重(和/或偏差)的微小变化只会在输出上产生微小变化。
如果我们有一个较大的输出增量,我们就不能进行渐进式学习(而非在所有的方向上进行尝试——这样的过程称为穷举搜索——我们不知道是否在改进)。毕竟,小孩子是一点一点学习的。不幸的是,感知机并不表现出这种一点一点学习的行为,感知机的结果是0或1,这是一个大的增量,它对学习没有帮助,如图1.2所示。
我们需要一些更平滑的东西,一个从0到1逐渐变化不间断的函数。在数学上,这意味着我们需要一个可以计算其导数的连续的函数。

图1.2
1.2.2 激活函数——sigmoid
sigmoid函数的定义如下:
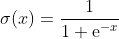
如图1.3所示,当输入在(−∞,∞)的区间上变化时,位于(0,1)区间上的输出值变化很小。从数学的角度讲,该函数是连续的。典型的sigmoid函数如图1.3所示。

图1.3
神经元可以使用sigmoid来计算非线性函数σ(z=wx+b)。注意,如果z=wx+b是非常大的正值,那么e−z→0,因而σ(z)→1;而如果z=wx+b是非常大的负值,e−z→∞,因而σ(z)→0。换句话说,以sigmoid为激活函数的神经元具有和感知机类似的行为,但它的变化是渐进的,输出值如0.553 9或0.123 191非常合理。在这个意义上,sigmoid神经元可能正是我们所要的。
1.2.3 激活函数——ReLU
sigmoid并非可用于神经网络的唯一的平滑激活函数。最近,一个被称为修正线性单元(Rectified Linear Unit,ReLU)的激活函数很受欢迎,因为它可以产生非常好的实验结果。
ReLU函数简单定义为f(x)=max(0,x),这个非线性函数如图1.4所示。对于负值,函数值为零;对于正值,函数呈线性增长。

图1.4
1.2.4 激活函数
在神经网络领域,sigmoid和ReLU通常被称为激活函数。在“Keras中的不同优化器测试”一节中,我们将看到,那些通常由sigmoid和ReLU函数产生的渐进的变化,构成了开发学习算法的基本构件,这些构件通过逐渐减少网络中发生的错误,来一点一点进行调整。图1.5给出了一个使用σ激活函数的例子,其中(x1, x2, …, xm)为输入向量,(w1, w2, …, wm)为权重向量,b为偏差,表示总和。

图1.5
Keras支持多种激活函数,完整列表请参考Keras官网。
1.3 实例——手写数字识别
在本节中,我们将构建一个可识别手写数字的网络。为此,我们使用MNIST数据集,这是一个由60 000个训练样例和10 000个测试样例组成的手写数字数据库。训练样例由人标注出正确答案,例如,如果手写数字是“3”,那么“3”就是该样例关联的标签。
在机器学习中,如果使用的是带有正确答案的数据集,我们就说我们在进行监督学习。 在这种情况下,我们可以使用训练样例调整网络。测试样例也带有与每个数字关联的正确答案。然而,这种情况下,我们要假装标签未知,从而让网络进行预测,稍后再借助标签来评估我们的神经网络对于识别数字的学习程度。因此,如你所料,测试样例只用于测试我们的网络。
每个MNIST图像都是灰度的,它由28×28像素组成。这些数字的一个子集如图1.6所示。

图1.6
1.3.1 One-hot编码——OHE
在很多应用中,将类别(非数字)特征转换为数值变量都很方便。例如,[0-9]中值为d的分类特征数字可以编码为10位二进制向量,除了第d位为1,其他位始终为0。 这类表示法称为 One-hot编码(OHE),当数据挖掘中的学习算法专门用于处理数值函数时,这种编码的使用非常普遍。
1.3.2 用Keras定义简单神经网络
这里,我们使用Keras定义一个识别MNIST手写数字的网络。我们从一个非常简单的神经网络开始,然后逐步改进。
Keras提供了必要的库来加载数据集,并将其划分成用于微调网络的训练集X_train,以及用于评估性能的测试集X_test。数据转换为支持GPU计算的float32类型,并归一化为[0, 1]。另外,我们将真正的标签各自加载到Y_train和Y_test中,并对其进行One-hot编码。我们来看以下代码:

输入层中,每个像素都有一个神经元与其关联,因而共有28×28 = 784个神经元,每个神经元对应MNIST图像中的一个像素。
通常来说,与每个像素关联的值被归一化到[0,1]区间中(即每个像素的亮度除以255,255是最大亮度值)。 输出为10个类别,每个数字对应一个类。
最后一层是使用激活函数softmax的单个神经元,它是sigmoid函数的扩展。softmax将任意k维实向量压缩到区间(0, 1)上的k维实向量。在我们的例子中,它聚合了上一层中由10个神经元给出的10个答案。

一旦我们定义好模型,我们就要对它进行编译,这样它才能由Keras后端(Theano或TensorFlow)执行。编译期间有以下几个选项。
我们需要选择优化器,这是训练模型时用于更新权重的特定算法。
我们需要选择优化器使用的目标函数,以确定权重空间(目标函数往往被称为损失函数,优化过程也被定义为损失最小化的过程)。
我们需要评估训练好的模型。
目标函数的一些常见选项(Keras目标函数的完整列表请参考官网)如下所示。
MSE:预测值和真实值之间的均方误差。从数学上讲,如果γ是n个预测值的向量,Y是n个观测值的向量,则它们满足以下等式:
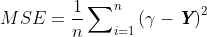
这些目标函数平均了所有预测错误,并且如果预测远离真实值,平方运算将让该差距更加明显。
Binary cross-entropy:这是二分对数损失。假设我们的模型在目标值为t时预测结果为p,则二分交叉熵定义如下:
{-:-}−tlog(p)−(1−t)log(1−p)
该目标函数适用于二元标签预测。
Categorical cross-entropy:这是多分类对数损失。如果目标值为ti,j时预测结果为pi,j,则分类交叉熵是:
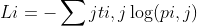
该目标函数适用于多分类标签预测。它也是与激活函数softmax关联的默认选择。
一些常见的性能评估指标(Keras性能评估指标的完整列表请参考官网)如下所示。
Accuracy:准确率,针对预测目标的预测正确的比例。
Precision:查准率,衡量多分类问题中多少选择项是关联正确的。
Recall:查全率,衡量多分类问题中多少关联正确的数据被选出。
性能评估与目标函数类似,唯一的区别是它们不用于训练模型,而只用于评估模型。 在Keras中编译模型很容易:

一旦模型编译好,就可以用fit()函数进行训练了,该函数指定了以下参数。
epochs:训练轮数,是模型基于训练集重复训练的次数。在每次迭代中,优化器尝试调整权重,以使目标函数最小化。
batch_size:这是优化器进行权重更新前要观察的训练实例数。
在Keras中训练一个模型很简单。假设我们要迭代NB_EPOCH步:

我们留出训练集的部分数据用于验证。关键的思想是我们要基于这部分留出的训练集数据做性能评估。对任何机器学习任务,这都是值得采用的最佳实践方法,我们也将这一方法应用在所有的例子中。
一旦模型训练好,我们就可以在包含全新样本的测试集上进行评估。这样,我们就可以通过目标函数获得最小值,并通过性能评估获得最佳值。
注意,训练集和测试集应是严格分开的。 在一个已经用于训练的样例上进行模型的性能评估是没有意义的。学习本质上是一个推测未知事实的过程,而非记忆已知的内容。

恭喜,你已在Keras中定义了你的第一个神经网络。仅几行代码,你的计算机已经能识别手写数字了。让我们运行代码,并看看其性能。
1.3.3 运行一个简单的Keras网络并创建基线
让我们看看代码运行结果,如图1.7所示。

首先,网络结构被铺开,我们可以看到使用的不同类型的网络层、它们的输出形状、需要优化的参数个数,以及它们的连接方式。之后,网络在48 000个样本上进行训练,12 000个样本被保留并用于验证。一旦构建好神经网络模型,就可以在10 000个样本上进行测试。如你所见,Keras内部使用了TensorFlow作为后端系统进行计算。现在,我们不探究内部训练细节,但我们可以注意到该程序运行了200次迭代,每次迭代后,准确率都有所提高。
训练结束后,我们用测试数据对模型进行测试,其中训练集上达到的准确率为92.36%,验证集上的准确率为92.27%,测试集上的准确率为92.22%。
这意味着10个手写数字中只有不到一个没有被正确识别。当然我们可以比这做得更好。在图1.8中,我们可以看到测试的准确率。

图1.8
1.3.4 用隐藏层改进简单网络
现在我们有了基线精度,训练集上的准确率为92.36%,验证集上的准确率为92.27%,测试集上的准确率为92.22%,这是一个很好的起点,当然我们还能对它进行提升,我们看一下如何改进。
第一个改进方法是为我们的网络添加更多的层。所以在输入层之后,我们有了第一个具有N_HIDDEN个神经元并将ReLU作为激活函数的dense层。这一个追加层被认为是隐藏的,因为它既不与输入层也不与输出层直接相连。在第一个隐藏层之后,是第二个隐藏层,这一隐藏层同样具有N_HIDDEN个神经元,其后是一个具有10个神经元的输出层,当相关数字被识别时,对应的神经元就会被触发。以下代码定义了这个新网络。


让我们运行代码并查看这一多层网络获取的结果。还不错,通过增加两个隐藏层,我们在训练集上达到的准确率为94.50%,验证集上为94.63%,测试集上为94.41%。这意味着相比之前的网络,准确率提高了2.2%。然而,我们将迭代次数从200显著减少到了20。这很好,但是我们要更进一步。
如果你想,你可以自己尝试,看看如果只添加一个隐藏层而非两个,或者添加两个以上的隐藏层结果会怎样。我把这个实验留作练习。图1.9显示了前例的输出结果。

图1.9
1.3.5 用dropout进一步改进简单网络
现在我们的基线在训练集上的准确率为94.50%,验证集上为94.63%,测试集上为94.41%。第二个改进方法很简单。我们决定在内部全连接的隐藏层上传播的值里,按dropout概率随机丢弃某些值。在机器学习中,这是一种众所周知的正则化形式。很惊奇,这种随机丢弃一些值的想法可以提高我们的性能。


让我们将代码像之前一样运行20次迭代。我们看到网络在训练集上达到了91.54%的准确率,验证集上为94.48%,测试集上为94.25%,如图1.10所示。

图1.10
注意,训练集上的准确率仍应高于测试集上的准确率,否则说明我们的训练时间还不够长。所以我们试着将训练轮数大幅增加至250,这时训练集上的准确率达到了98.1%,验证集上为97.73%,测试集上为97.7%,如图1.11所示。

图1.11
当训练轮数增加时,观察训练集和测试集上的准确率是如何增加的,这一点很有用。你可以从图1.12中看出,这两条曲线在训练约250轮时相交,而这一点后就没必要进一步训练了。


图1.12
注意,我们往往会观察到,内部隐藏层中带有随机dropout层的网络,可以对测试集中的全新样本做出更好的推测。直观地讲,你可以想象成:正因为神经元知道不能依赖于邻近神经元,它自身的能力才能更好发挥。测试时,先不加入dropout层,我们运行的是所有经过高度调整过的神经元。简而言之,要测试网络加入某些dropout功能时的表现,这通常是一种很好的方法。
1.3.6 Keras中的不同优化器测试
我们已定义和使用了一个网络,给出网络如何训练的直观解释非常有用。让我们关注一种被称为梯度下降(Gradient Descent,GD)的流行的训练方法。想象一个含有单一变量w的一般成本函数C(w),如图1.13所示。

图1.13
梯度下降可以看成一个要从山上到山谷的背包客,山上表示成函数C,山谷表示成最小值Cmin,背包客的起点为w0。背包客慢慢移动,对每一步r,梯度就是最大增量的方向。从数学上讲,该方向就是在步r到达的点wr上求得的偏导数。因此,走相反的方向,背包客就可以向山谷移动。每一步,背包客都能在下一步之前判别步长,这就是梯度下降中讲的学习率。注意,如果步长太小,背包客就会移动得很慢;如果过大,背包客又很可能错过山谷。现在,你应该记住sigmoid是一个连续函数,并可以计算导数。可以证明sigmoid函数如下所示:
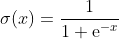
它的导数如下:
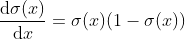
ReLU函数在点0处不可微,然而,我们可以将点0处的一阶导数扩展到整个定义域,使其为0或1。这种和点相关的ReLU函数y=max(0, x)的导数如下:

一旦我们有了导数,就可以用梯度下降技术来优化网络。Keras使用它的后端(TensorFlow或者Theano)来帮助我们计算导数,所以我们不用担心如何实现或计算它。我们只需选择激活函数,Keras会替我们计算导数。
神经网络本质上是带有几千个甚至几百万个参数的多个函数的组合。每个网络层计算一个函数,使其错误率最低,以改善学习阶段观察到的准确率。当我们讨论反向传播时,我们会发现这个最小化过程比我们的简单示例更加复杂。然而,它同样基于降至山谷的直观过程。
Keras实现了梯度下降的一个快速变体,称为随机梯度下降(Stochastic Gradient Descent,SGD),以及RMSprop和Adam这两种更先进的优化技术。除SGD具有的加速度分量之外,RMSprop和Adam还包括了动量的概念(速度分量)。这样可以通过更多的计算代价实现更快的收敛。Keras支持的优化器的完整列表请参考官网。SGD是我们到目前为止的默认选择。现在让我们尝试另外两个,这很简单,我们只需要改几行代码:

好了,我们来进行测试,如图1.14所示。

图1.14
从图1.14可以看出,RMSprop比SDG快,因为仅在20次迭代后我们就改进了SDG,并能在训练集上达到97.97%的准确率,验证集上为97.59%,测试集上为97.84%。为完整起见,让我们看看准确率和损失函数如何随训练轮数的变化而改变,如图1.15所示。


图1.15
现在我们试试另一个优化器Adam()。这相当简单,如下:

正如我们所看到的,Adam稍好些。使用Adam,训练20轮后,我们在训练集上的准确率达到了98.28%,验证集上达到了98.03%,测试集上达到了97.93%,如图1.16所示。


图1.16
这是我们修改过的第5个版本,请记住我们的初始基线是92.36%。
到目前为止,我们做了渐进式的改进;然而,获得更高的准确率现在越来越难。注意,我们使用了30%的dropout概率进行优化。为完整起见,我们在选用Adam()作为优化器的条件下,测试其他dropout概率下测试集上的准确率报表,如图1.17所示。

图1.17
1.3.7 增加训练轮数
让我们尝试将训练中使用的轮转次数从20增加到200,不幸的是,这让我们的计算时间增加了1倍,但网络并没有任何改善。这个实验并没成功,但我们知道了即使花更多的时间学习,也不一定会对网络有所提高。学习更多的是关于采用巧妙的技术,而不是计算上花费多少时间。让我们追踪一下程序第6次修改的结果,如图1.18所示。

图1.18
1.3.8 控制优化器的学习率
另外一个我们可以进行的尝试是改变优化器的学习参数。 你可以从图1.19中看出,最优值接近0.001,这是优化器的默认学习率。不错,Adam优化器表现得非常好。

图1.19
1.3.9 增加内部隐藏神经元的数量
我们还可以做另一个尝试,那就是改变内部隐藏神经元的数量。我们用不断增加的隐藏神经元汇总得出实验结果。我们可以从图1.20中看到,通过增加模型的复杂性,运行时间也显著增加,因为有越来越多的参数需要优化。然而,随着网络的增长,我们通过增加网络规模获得的收益也越来越少。

图1.20
图1.21显示了随着隐藏神经元的增多,每次迭代所需的时间。

图1.21
图1.22显示了随着隐藏神经元的增多,准确率的变化。

图1.22
1.3.10 增加批处理的大小
对训练集中提供的所有样例,同时对输入中给出的所有特征,梯度下降都尝试将成本函数最小化。随机梯度下降开销更小,它只考虑BATCH_SIZE个样例。因此,让我们看一下改变这个参数时的效果。如图1.23所示,最优的准确率在BATCH_SIZE=128时取得。

图1.23
1.3.11 识别手写数字的实验总结
现在我们总结一下:使用5种不同的修改,我们可以将性能从92.36%提高到97.93%。首先,我们在Keras中定义一个简单层的网络;然后,我们通过增加隐藏层提高性能;最后,我们通过添加随机的dropout层及尝试不同类型的优化器改善了测试集上的性能。结果汇总如表1.1所示。
表1.1
| 模型/准确率 | 训练 | 验证 | 测试 |
|---|---|---|---|
| Simple | 92.36% | 92.37% | 92.22% |
| Two hidden(128) | 94.50% | 94.63% | 94.41% |
| Dropout(30%) | 98.10% | 97.73% | 97.7%(200次) |
| RMSprop | 97.97% | 97.59% | 97.84%(20次) |
| Adam | 98.28% | 98.03% | 97.93%(20次) |
然而,接下来的两个实验没有显著提高。增加内部神经元的数量会产生更复杂的模型,并需要更昂贵的计算,但它只有微小的收益。即使增加训练轮数,也是同样的结果。 最后一个实验是修改优化器的BATCH_SIZE。
1.3.12 采用正则化方法避免过拟合
直观地说,良好的机器学习模型应在训练数据上取得较低的误差。在数学上,这等同于给定构建好的机器学习模型,使其在训练数据上的损失函数最小化,其公式表示如下:
{-:-}min:{loss(训练数据|模型)}
然而,这可能还不够。为捕捉训练数据内在表达的所有关系,模型可能会变得过度复杂。而复杂性的增加可能会产生两个负面后果。第一,复杂的模型可能需要大量的时间来执行;第二,因其所有内在关系都被记忆下来,复杂的模型可能在训练数据上会取得优秀的性能,但在验证数据上的性能却并不好,因为对于全新的数据,模型不能进行很好的泛化。再次重申,学习更多的是关于泛化而非记忆。图1.24表示了在验证集和训练集上均呈下降的损失函数。然而,由于过度拟合,验证集上的某一点后,损失函数开始增加,如图1.24所示。

图1.24
根据经验,如果在训练期间,我们看到损失函数在验证集上初始下降后转为增长,那就是一个过度训练的模型复杂度问题。实际上,过拟合是机器学习中用于准确描述这一问题的名词。
为解决过拟合问题,我们需要一种捕捉模型复杂度的方法,即模型的复杂程度。 解决方案会是什么呢?其实,模型不过是权重向量,因此,模型复杂度可以方便地表示成非零权重的数量。换句话说,如果我们有两个模型M1和M2,在损失函数上几乎实现了同样的性能,那么我们应选择最简单的包含最小数量非零权重的模型。如下所示,我们可以使用超参数λ≥0来控制拥有简单模型的重要性:
{-:-}min:{loss(训练数据|模型)}+λ*complexity(模型)
机器学习中用到了3种不同类型的正则化方法。
L1正则化(也称为lasso):模型复杂度表示为权重的绝对值之和
L2正则化(也称为ridge):模型复杂度表示为权重的平方和
弹性网络正则化:模型复杂度通过联合前述两种技术捕捉
注意,相同的正则化方案可以独立地应用于权重、模型和激活函数。
因此,应用正则化方案会是一个提高网络性能的好方法,特别是在明显出现了过拟合的情况下。这些实验可以留给对此感兴趣的读者作为练习。
请注意,Keras同时支持L1、L2和弹性网络这3种类型的正则化方法。加入正则化方法很简单。举个例子,这里我们在内核(权重W)上使用了L2正则化方法:

关于可用参数的完整说明,请参见Keras官网。
1.3.13 超参数调优
上述实验让我们了解了微调网络的可能方式。 然而,对一个例子有效的方法不一定对其他例子也有效。对于给定的网络,实际上有很多可以优化的参数(如隐藏神经元的数量、BATCH_SIZE、训练轮数,以及更多关于网络本身复杂度的参数等)。
超参数调优是找到使成本函数最小化的那些参数组合的过程。关键思想是,如果我们有n个参数,可以想象成它们定义了一个n维空间,目标是找出空间中和成本函数最优值对应的点。实现此目标的一种方法是在该空间中创建一个网格,并系统地检查每个网格顶点的成本函数值。换句话说,这些参数被划分成多个桶,并且通过蛮力法来检查值的不同组合。
1.3.14 输出预测
当网络训练好后,它就可以用于预测。在Keras中,这很简单。我们可以使用以下方法:

对于给定的输入,可以计算出几种类型的输出,包括以下方法。
model.evaluate():用于计算损失值
model.predict_classes():用于计算输出类别
model.predict_proba():用于计算类别概率
1.4 一种实用的反向传播概述
多层感知机通过称为反向传播的过程在训练数据上学习。这是个错误一经发现就逐渐改进的过程。让我们看看它是如何工作的。
请记住,每个神经网络层都有一组相关的权重,用于确定给定输入集合的输出值。 此外,还请记住神经网络可以有多个隐藏层。
开始时,所有的权重都是随机分配的。然后,网络被训练集中的每个输入激活:权重值从输入阶段开始向前传播给隐藏层,隐藏层再向前传播给进行输出预测的输出层(注意,在简化图1.25中,我们仅用绿色虚线表示几个值,但实际上,所有值都是沿网络前向传播的)。

图1.25
由于我们知道训练集中的真实观察值,因而可以计算预测中产生的误差。回溯的关键点是将误差反向传播,并使用适当的优化器算法,如梯度下降,来调整神经网络的权重,以减小误差(同样为了简单起见,只表示出几个错误值),如图1.26所示。

图1.26
将输入到输出的正向传播和误差的反向传播过程重复几次,直到误差低于预定义的阈值。整个过程如图1.27所示。

图1.27
特征表示这里用于驱动学习过程的输入和标签。模型通过这样的方式更新,损失函数被逐渐最小化。在神经网络中,真正重要的不是单个神经元的输出,而是在每层中调整的集体权重。因此,网络以这样的方式逐渐调整其内部权重,预测正确的标签数量也跟着增多。当然,使用正确的集合特征及高质量的标签数据是在学习过程中偏差最小化的基础。
1.5 走向深度学习之路
识别手写数字的同时,我们得出结论,准确率越接近 99%,提升就越困难。如果想要有更多的改进,我们肯定需要一个全新的思路。想一想,我们错过了什么?
基本的直觉是,目前为止,我们丢失了所有与图像的局部空间相关的信息。 特别地,这段代码将位图转换成空间局部性消失的平面向量:

然而,这并非我们大脑工作的方式。 请记住,我们的想法是基于多个皮质层,每一层都识别出越来越多的结构化信息,并仍然保留了局部化信息。首先,我们看到单个的像素,然后从中识别出简单的几何形状,最后识别出更多的复杂元素,如物体、面部、人体、动物等。
在第3章“深度学习之卷积网络”中,我们将看到一种特殊类型的深度学习网络,这种网络被称为卷积神经网络(Convolutional Neural Network,CNN),它同时考虑了两个方面:既保留图像(更一般地,任何类型的信息)中空间局部性的信息, 也保留层次渐进的抽象学习的思想。一层时,你只能学习简单模式;多层时,你可以学习多种模式。 在学习CNN之前,我们需要了解Keras架构方面的内容,并对一些机器学习概念进行实用的介绍。这将是下一章的主题。
1.6 小结
本章中,你学习了神经网络的基础知识。具体包括:什么是感知机,什么是多层感知机,如何在Keras中定义神经网络,当确立了良好的基线后如何逐步改进性能,以及如何微调超参数空间。 此外,你现在对一些有用的激活函数(sigmoid和ReLU)有了了解,还学习了如何基于反向传播算法来训练网络,如梯度下降、随机梯度下降,或更复杂的方法如Adam和RMSprop。
在下一章中,我们将学习如何在AWS、微软Azure、谷歌Cloud以及你自己的机器上安装Keras。除此之外,我们还将给出Keras API的概述。
本文转载自异步社区。
原文链接:https://www.epubit.com/articleDetails?id=N85b71efe-e504-4dc5-bf1b-c9847caa6a59

![http://47.93.163.221:8084/uploadimg/Material/978-7-115-48222-8/72jpg/48222_s300.jpg)]](http://47.93.163.221:8084/uploadimg/Material/978-7-115-48222-8/72jpg/48222_s300.jpg)%5D){kind=link}
- 点赞
- 收藏
- 关注作者
评论(0)