分布式系统关注点——「高内聚低耦合」详解

如果这是第二次看到我的文章,欢迎点击文末连接关注我的公众号(跨界架构师)哟~
本文长度为3012字,建议阅读8分钟。
坚持原创,每一篇都是用心之作~
下面的这个场景你可能会觉得很熟悉(Z哥我又要出演了![]() ):
):
Z哥:@All 兄弟姐妹们,这次我这边有个需求需要给「商品上架」增加一道审核,会影响到大家和我交互的接口。大家抽空配合改一下,明天一起更新个版本。
小Y:哥,我这几天很忙啊,昨天刚配合老王改过促销!
小X:行~当一切已成习惯。
作为被通知人,如果在你的现实工作中也发生了类似事件,我相信哪怕嘴上不说,心里也会有不少想法和抱怨:“md,改的是你,我也要发布,好冤啊!”。
这个问题的根本原因就是多个项目之间的耦合度过于严重。
越大型的项目越容易陷入到这个昭潭中,难以自拔。
而解决问题的方式就是进行更合理的分层,并且持续保证分层的合理性。
一提到分层,必然离不开6个字「高内聚」和「低耦合」。
什么是高内聚低耦合
在z哥之前的文章中有多次提到,分布式系统的本质就是「分治」和「冗余」。
其中,分治就是“分解 -> 治理 -> 归并”的三部曲。「高内聚」、「低耦合」的概念就来源于此。
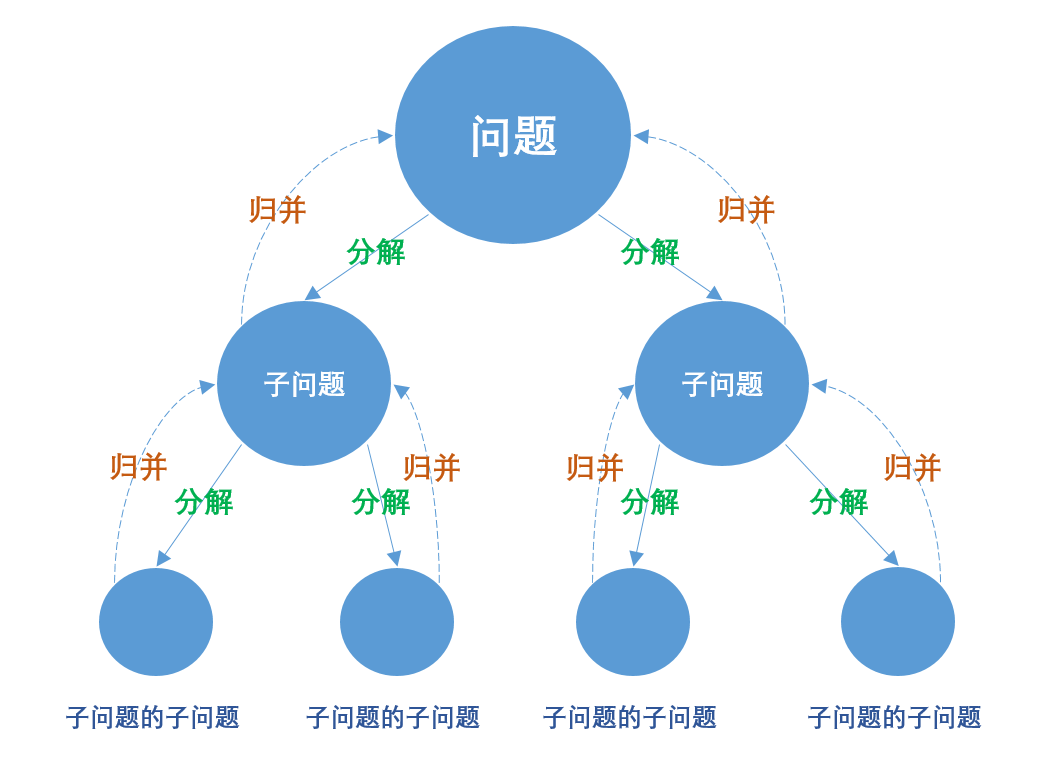
需要注意的是,当你在做「分解」这个操作的时候,务必要关注每一次的「分解」是否满足一个最重要的条件:不同分支上的子问题,不能相互依赖,需要各自独立。
因为一旦包含了依赖关系,子问题和父问题之间就失去了可以被「归并」的意义。
比如,一个「问题Z」被分解成了两个子问题,「子问题A」和「子问题B」。但是,解问题A依赖于问题B的答案,解问题B又依赖于问题A的答案。这不就等于没有分解吗?
题外话:这里的“如何更合理的分解问题”这个思路也可以用到你的生活和工作中的任何问题上。
所以,当你在做「分解」的时候,需要有一些很好的着力点去切入。
这个着力点就是前面提到的「耦合度」和「内聚度」,两者是一个此消彼长的关系。
越符合高内聚低耦合这个标准,程序的维护成本就越低。为什么呢?因为依赖越小,各自的变更对其他关联方的影响就越小。
所以,「高内聚」和「低耦合」是我们应当持续不断追求的目标。
题外话:耦合度,指的是软件模块之间相互依赖的程度。比如,每次调用方法 A 之后都需要同步调用方法 B,那么此时方法 A 和 B 间的耦合度是高的。
内聚度,指的是模块内的元素具有的共同点的相似程度。比如,一个类中的多个方法有很多的共同之处,都是做支付相关的处理,那么这个类的内聚度是高的。
怎么做好高内聚低耦合
做好高内聚低耦合,思路也很简单:定职责、做归类、划边界。
首先,定职责就是定义每一个子系统、每一个模块、甚至每一个class和每一个function的职责。
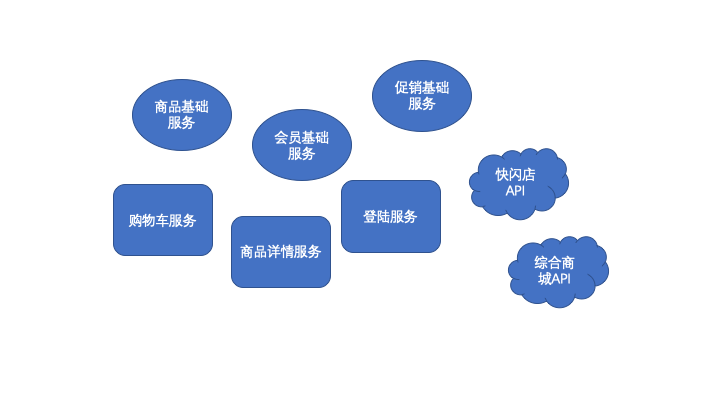
比如,在子系统或者模块层面可以这样。
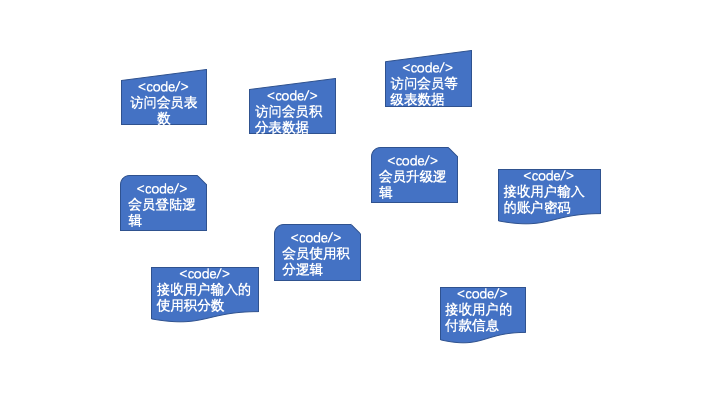
又比如,在class或者function层面可以这样。
我想这点大家平时都会有意识的去做。
做好了职责定义后,内聚性就会有很大的提升,同时也提高了代码/程序的复用程度。
至此,我们才谈得上「单一职责(SRP)」这种设计原则的运用。
其次,做归类。梳理不同模块之间的依赖关系。
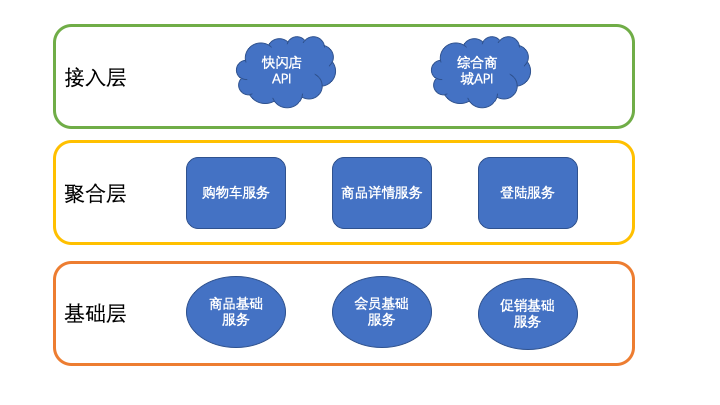
像上面提到的案例1可以归类为3层:
基础层:商品基础服务、会员基础服务、促销基础服务
聚合层:购物车服务、商品详情服务、登陆服务
接入层:快闪店API、综合商城API
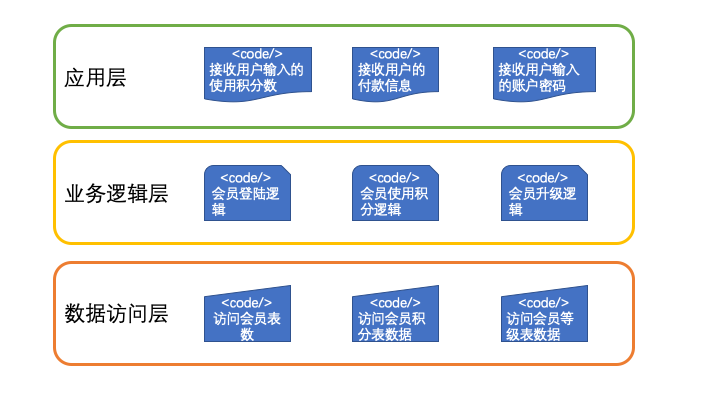
案例2也可以归类为3层:
数据访问层:访问会员表数据、访问会员积分表数据、访问会员等级表数据
业务逻辑层:会员登陆逻辑、会员使用积分逻辑、会员升级逻辑
应用层:接收用户输入的账户密码、接收用户输入的使用积分数、接收用户的付款信息
最后就是划边界。好不容易梳理清楚,为了避免轻易被再次破坏,所以需要设立好合理清晰的边界。
否则你想的是这样整齐。

实际会慢慢变成这样混乱。

那么应该怎么划边界呢?
class和function级别。这个层面可以通过codereview或者静态代码检测工具来进行,可以关注的点比如:
调用某些class必须通过interface而不是implement
访问会员表数据的class中不能存在访问商品数据的function
模块级别。可以选择以下方案:
给每一种类型的class分配不同project,打包到各自的dll(jar)中
每次代码push上来的时候检测其中的依赖是否有超出规定的依赖。例如,不能逆向依赖(检测dal是否包含bll);不能在基础层做聚合业务(检测商品基础服务是否包含其他基础服务的dll(jar))。
系统级别。及时识别子系统之间的调用是否符合预期,可以通过接入一个调用链跟踪系统(如,zipkin)来分析请求链路是否合法。
让边界更清晰、稳定的最佳实践
很多时候不同的模块或者子系统会被分配到不同的小组中负责,所以z哥再分享几个最佳实践给你。它可以让系统之间的沟通更稳定。
首先是:模块对外暴露的接口部分,数据类型的选择上尽量做到宽进严出。比如,使用long代替byte之类的数据类型;使用弱类型代替强类型等等。
举个「宽进严出」的例子:
//使用long代替byte之类的数据类型。
void Add(long param1, long param2){
if(param1 <1000&& param2 < 1000){ //先接收进来,到里面再做逻辑校验。
//do something...
}
else{
//do something...
}
}
其次是:写操作接口,接收参数尽可能少;读操作接口,返回参数尽可能多。
为什么呢?因为很多时候,写操作的背后会存在一个潜在预期,是「准确」。
准确度和可信度有着很大的联系,只有更多的逻辑处理在自己掌控范围内进行才能越具备「可信度」(当然是职责范围内的逻辑,而不是让商品服务去计算促销的逻辑)。反之,上游系统一个bug就会牵连到你的系统中。
而读操作背后的潜在预期是:「满足」。你得提供给我满足我当前需要的数据,否则我的工作无法开展。
但是呢,在不同时期,客户端所需要的数据可能会发生变化,你无法预测。所以呢,不要吝啬,返回参数尽可能多,用哪些,用不用是客户端的事。
还可以做的更好的一些,就是,在可以满足的基础上支持按需获取。客户端需要返回哪些字段自己通过参数传过来,如此一来还能避免浪费资源做无用的数据传输。
题外话:对外露出的接口设计,可以使用http + json 这种跨平台 + 弱类型的技术组合,可具备更好的灵活性。
实际上,一个程序大多数情况下,在某些时刻是客户端,又在某些时刻是服务端。站在一个完整程序的角度来提炼参数设计的思路就是:“吃”的要少,“产出”的要多。
题外话:有一些设计原则可以扩展阅读一下。
单一职责原则SRP(Single Responsibility Principle)
开放封闭原则OCP(Open-Close Principle)
里式替换原则LSP(the Liskov Substitution Principle LSP)
依赖倒置原则DIP(the Dependency Inversion Principle DIP)
接口分离原则ISP(the Interface Segregation Principle ISP)
总结
本文z哥带你梳理了一下「高内聚低耦合」的本质(来自于哪,意义是什么),并且分享了一些该怎么做的思路。
可以看到「高内聚」、「低耦合」其实没有这个名字那么高端。哪怕你现在正在工作的项目是一个单体应用,也可以在class和function的设计中体会到「高内聚」、「低耦合」的奥妙。
来来来,接下去马上开始在项目中「刻意练习」起来吧~![]()
「易伸缩」篇的相关文章:
作者:Zachary
出处:https://www.cnblogs.com/Zachary-Fan/p/highcohesionlowcoupling.html
如果你喜欢这篇文章,可以点一下底部的「大拇指」。
这样可以给我一点反馈。: )
谢谢你的举手之劳。
▶关于作者:张帆(Zachary,个人微信号:Zachary-ZF)。坚持用心打磨每一篇高质量原创。欢迎点击下方连接关注我哟~。
定期发表原创内容:架构设计丨分布式系统丨产品丨运营丨一些思考。
如果你是初级程序员,想提升但不知道如何下手。又或者做程序员多年,陷入了一些瓶颈想拓宽一下视野。欢迎关注我的公众号「跨界架构师」,回复「技术」,送你一份我长期收集和整理的思维导图。
如果你是运营,面对不断变化的市场束手无策。又或者想了解主流的运营策略,以丰富自己的“仓库”。欢迎关注我的公众号「跨界架构师」,回复「运营」,送你一份我长期收集和整理的思维导图。

- 点赞
- 收藏
- 关注作者
评论(0)