MySQL复制

复制
复制概述
复制解决的基本问题是让一台服务器的数据与其他服务器保持同步,一台主库的数据可以同步到多台从库上,当然从库可以被配置成另一台服务器的主库。主库和备库之间可以有多种不同的组合方式。
MySQL支持两种复制方式,基于行的复制和基于语句的复制。基于语句的复制(也称为逻辑复制)早在MySQL3.23版本中就存在,而基于行的复制方式在5.1版本中加进来。这两种方式都是通过在主库上记录二进制日志,在从库重放日志的方式来实现异步的数据复制。这也就意味着,在同一时间点,备库上的数据可能与主库存在不一致,并且无法保证主备之间的延迟。一些大的语句可能导致备库产生几秒,几分钟甚至几小时的延迟。
mysql的复制大多数是向后兼容的,新版本的服务器可以作为老版本服务器的从库,但反过来,将老版本作为新版本服务器的从库通常是不可行的,因为它可能无法解析新版本所采用的新特性或语法,另外所使用的二进制文件也可能不同。
复制通常不会增加主库的开销,主要是启用二进制日志带来的开销,但出于备份或及时从崩溃中恢复的目的,这点开销也是必要的。除此之外,每个从库也会对主库增加一些负载(例如网络IO开销)尤其是当从库请求从主库读取旧的二进制日志文件时,可能会造成更高的IO开销。另外锁竞争也可能阻碍事务的提交。最后,如果是从一个高吞吐量的主库复制到多个备库,唤醒多个复制线程发送事件的开销也会增加。
通过复制可以将读操作指向备库来获得更好的读扩展,但对于写操作,除非设计得当,否则并不适合通过复制来扩展写操作。在一主多从的架构中,写操作会被执行多次,这时候整个系统的性能取决于写入最慢的那部分。
当我们要使用一主库多从库的架构时,可能就是会造成一些浪费,因为本质上他会复制大量不必要的重复数据。你比如说一主10从的就会有11份数据拷贝,并且这11台服务器的缓存中存储了大部分相同的数据。
复制解决的问题
下面呢,我们介绍一些复制比较常见的用途:
:kick_scooter:数据分布
MySQL复制通常不会对带宽造成很大的压力。你可以随意的停止或者开始复制,并在不同的地理位置来分布数据备份。即使你的环境网络不稳定,远程复制也可以工作。但是如果为了保持很低的复制延迟,还是选择一个稳定的低延迟的联结。
:man_juggling:负载均衡
通过MySQL复制可以将读操作分布到多个服务器上,实现对读密集应用的优化,并且实现很方便,通过简单的代码修改就能实现基本的负载均衡。
:dango:备份
对于备份来说,复制是一项很有意义的技术补充,但是复制既不是备份也不能够取代备份。
复制如何工作
首先我们来介绍一下mysql是如何复制数据的。总共三个步骤:
- 在主库上把数据记录到二进制日志(binary log)中(这些记录被称为二进制日志事件)
- 从库将主库上的日志复制到自己的中继日志(relay log)中
- 从库读取中继日志中的事件,将其重放到从库数据之上。
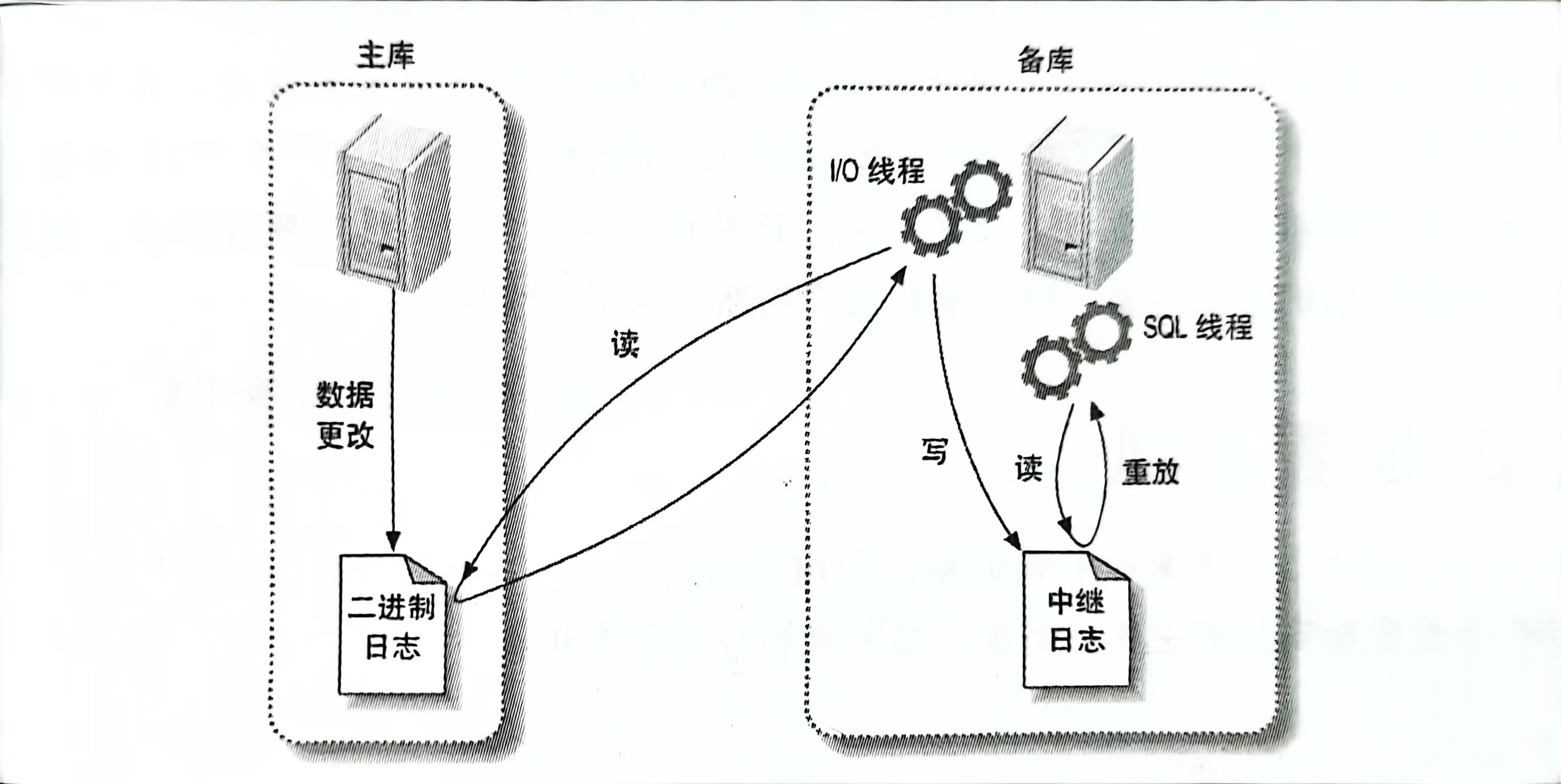
首先第一步:在主库上记录二进制日志。在每次准备提交事务完成数据更新前,主库将数据更新的事件记录到二进制日志中。MySQL会按事务提交的顺序而非每条语句的执行顺序来记录二进制日志。在记录二进制日志后,主库会告诉存储引擎可以提交事务了。
下一步:从库将主库的二进制日志复制到其本地的中继日志中。首先,从库会启动一个工作线程,称为IO线程,IO线程跟主库建立一个普通的客户端连接,然后在主库上启动一个特殊的二进制转储(binlog dump)线程(该线程没有对应的SQL命令)。这个二进制转储线程会读取主库上二进制日志中的事件。他不会对事件进行轮询。如果该线程追赶上了主库,他将进入休眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒,备库IO线程会将接受到的事件记录到中继日志中。
从库的SQL线程执行最后一步,该线程从中继日志中读取事件并在从库执行,从而实现从库的数据更新。当SQL线程追赶上IO线程时,中继日志通常已经在系统缓存中,所以中继日志的开销很低。SQL线程执行的事件也可以通过配置选项来决定是否写入其自己的二进制日志中,这点我们之后还会提到。
这种复制架构实现了获取事件和重放事件的解耦,允许这两个过程异步进行。也就是说I/O线程能够独立于SQL线程之外工作。但是这种架构也限制了复制的过程,其中最重要的一点是在主库上并发运行的查询在从库只能串行化执行,因为只有一个SQL线程来重放中继日志中的事件。
配置复制
配置复制,总的来说分为以下几步:
- 在每台服务器上创建复制账号
- 配置主库和从库
- 通知从库连接到主库并且从主库复制数据
创建复制账号
MySQL会赋予一些特殊的权限给复制线程。在从库运行的I/O线程会建立一个到主库的 TCP/IP连接,这意味着必须在主库创建一个用户,并赋予其合适的权限。从库I/O线程以该用户名连接到主库并读取其二进制日志。
我们在主库使用如下的语句创建用户账号:
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO slave@'%’ IDENTIFIED BY'mima';
刷新权限:
flush privileges;
创建一个slave用户,有REPLICATION SLAVE,REPLICATION CLIENT权限,密码是“mima”。
REPLICATION SLAVE 常用于建立复制时所需要用到的用户权限,也就是slave server必须被master server授权具有该权限的用户,才能通过该用户复制。并且"SHOW SLAVE HOSTS"这条命令和REPLICATION SLAVE权限有关,否则执行时会报错:ERROR 1227 (42000): Access denied; you need (at least one of) the REPLICATION SLAVE privilege(s) for this operation
REPLICATION CLIENT 不可用于建立复制,有该权限时,只是多了可以使用如"SHOW SLAVE STATUS"、“SHOW MASTER STATUS"等命令。在5.6.6版本以后,也可以使用"SHOW BINARY LOGS”。
我们在主库和从库都应该创建该账号。我在上面创建是%登录。但其实我们最好使用192.168.3.%,这种形式,把这个账户限制到本地网络中去,因为这是一个特权账号(尽管该账号无法执行select或修改数据,但任然能从二进制日志中获得一些数据)
配置主库和从库
在主库的my.cnf文件中增加或者修改如下内容:
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
#设置需要复制的数据库
binlog-do-db=test_slave
#设置logbin格式 默认
binlog_format=STATEMENT
配置从库:
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
查询master状态:
show master status;
记录下File和Position的值
执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化
在从机数据库执行:
CHANGE MASTER TO MASTER_HOST='192.168.10.106',
MASTER_USER='slave',
MASTER_PASSWORD='root',
MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=438;
438那个数据要根据你的具体情况更改。
启动从服务器复制功能:
start slave;
#查看从服务器状态
show slave status\G;
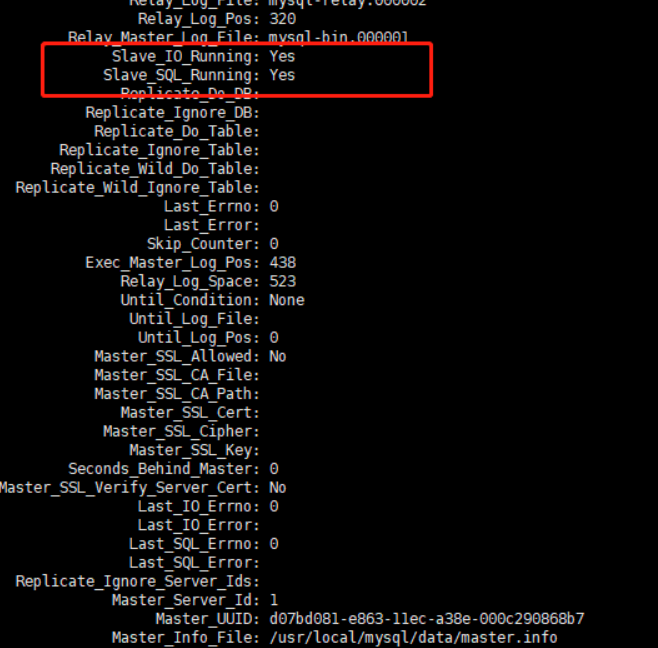
这两个都是yes,我们的主从数据库的配置就完成了。

- 点赞
- 收藏
- 关注作者
评论(0)