新手学习爬虫之创建第一个完整的scrapy工程-糗事百科

创建第一个scrapy工程-糗事百科
最近不少小伙伴儿,问我关于scrapy如何设置headers的问题,时间久了不怎么用,还真有的忘,全靠记忆去写了,为了方便大家参考,也方便我以后的查阅,这篇文章就诞生了。本章内容从实战出发让我们熟悉如何用scrapy写爬虫,本篇内容主要是实战,不讲述过多的理论性东西,因为讲多了我也不知道。
明确目标
首先,我们要明确我们的爬虫最终的目的是什么,这里我们要做的是爬取糗事百科的热门分类的前10页信息。包括发布者和内容,因为入门教程所以我们写的简单点主要是熟悉这个过程,这个如何入手呢?
分析链接的变化
一般我们会通过点击下一页,然后观察地址栏的信息来总结规律。
第一页也就是首页地址为:https://www.qiushibaike.com/
我们点击下一页可以发现第二页的的连接为:https://www.qiushibaike.com/8hr/page/2/
第三页:https://www.qiushibaike.com/8hr/page/3/
。。。以此类推第十页的连接为:https://www.qiushibaike.com/8hr/page/10/
由此我们发现规律,从第二页开始连接可以用https://www.qiushibaike.com/8hr/page/页数/来表示,有时候我比较喜欢试探,怎么说呢,我们知道这个规律是从第二页开始的,但是第一页是没有这个规律,但是我们不防试一试把第一页的https://www.qiushibaike.com/改为https://www.qiushibaike.com/8hr/page/1/。然后我们访问看看ok可以正常显示。

于是我们就确定了链接,也就是页数改为1-10就可以访问相应的页数了。
安装scrapy
我们要确保正确安装好了scrapy
针对mac和linux直接运行pip安装即可。
pip install scrapy
但是windows的坑就比较多了,关于windows的安装请参考我之前写的这篇文章
:https://www.cnblogs.com/c-x-a/p/8996716.html。这里就不多说了。
创建scrapy工程
好了下面我们开始创建工程首先我们使用scrapy的第一个命令startproject,
使用方法:scrapy startproject xxx xxx就是你的项目名,这里我们给我们的项目起名qiushibaike。
scrapy startproject qiushibaike
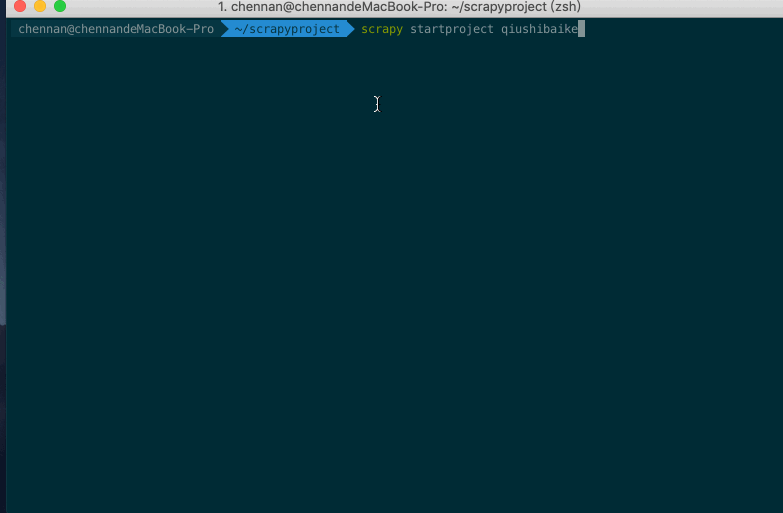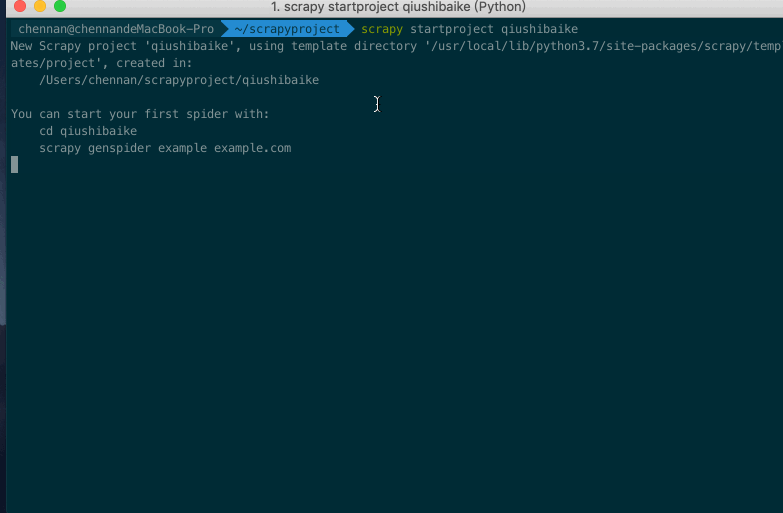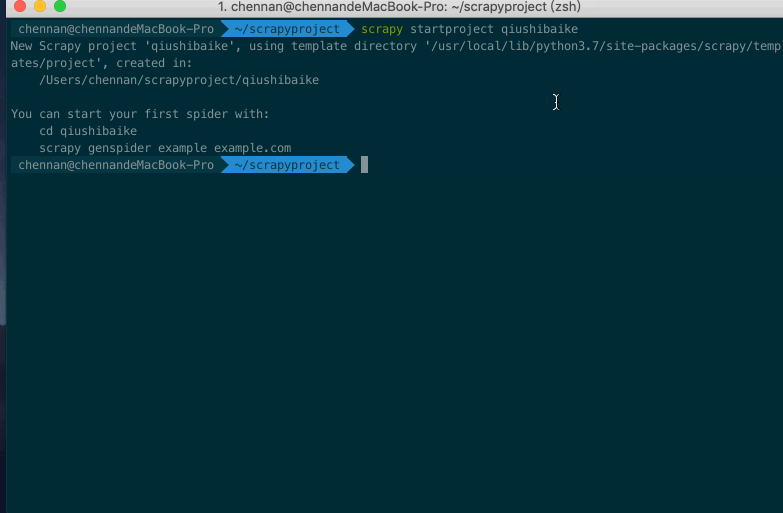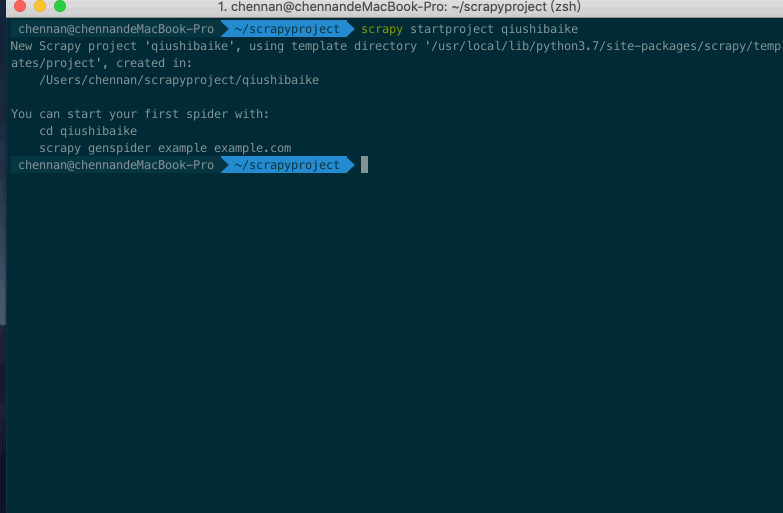
然后我们会发现了多了一个文件名为qiushibaike的文件夹
然后我们通过命令创建一个事例工程
进入qiushibaike
cd qiushibaike
然后用下面scrapy的第二个命令genspider
使用方法 scrapy genspider spider_name domain
spider_name就是爬虫的名字,每一个爬虫有一个名字这个名字是唯一的,后面运行的时候也是通过这个名字来运行的,下面的qsbk就是我们的爬虫名字,domain指定爬虫的域也就是爬虫的范围。查找网页我们发现域名为
scrapy genspider qsbk qiushibaike.com
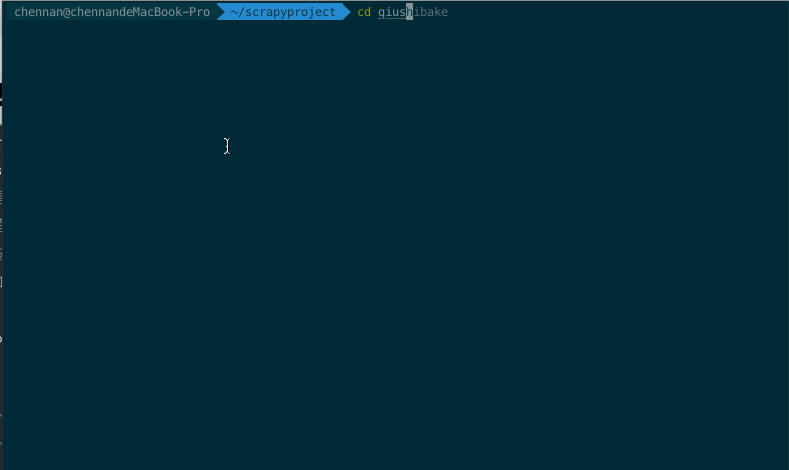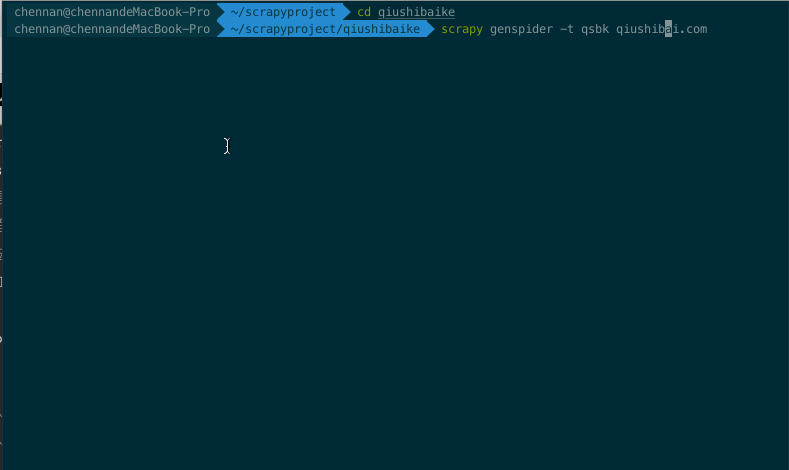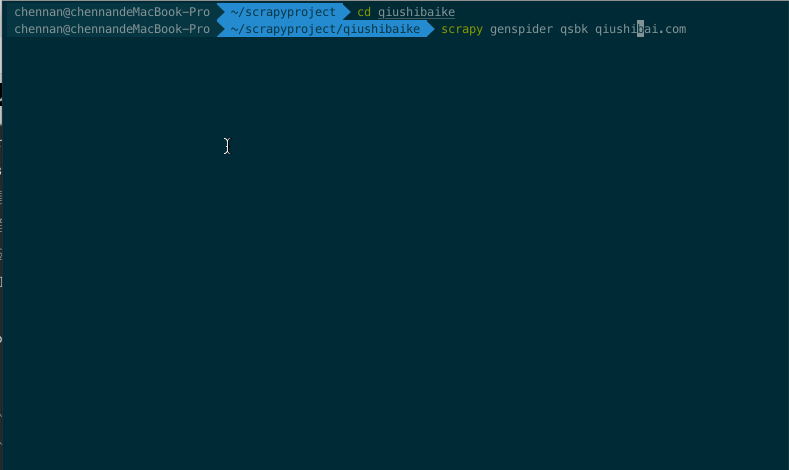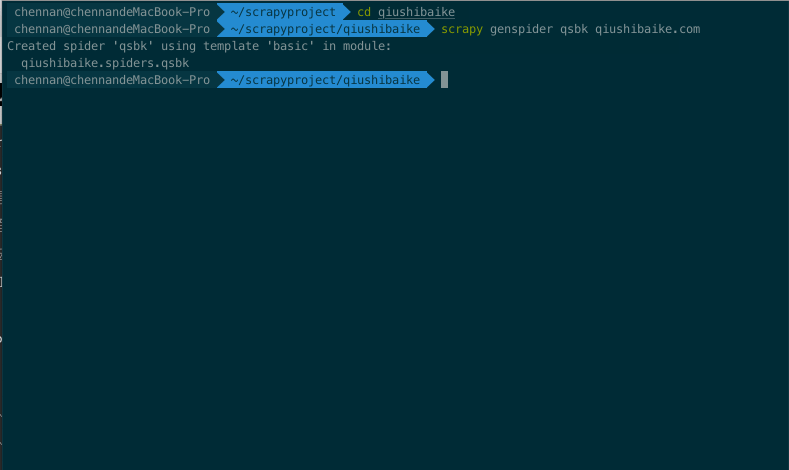
看到以下命令证明我们成功的创建了项目。
Created spider 'qsbk' using template 'basic' in module:
qiushibaike.spiders.qsbk
开始编写spider文件
我们这里使用pycharm把我们的爬虫工程加载进来。
目录结构如下
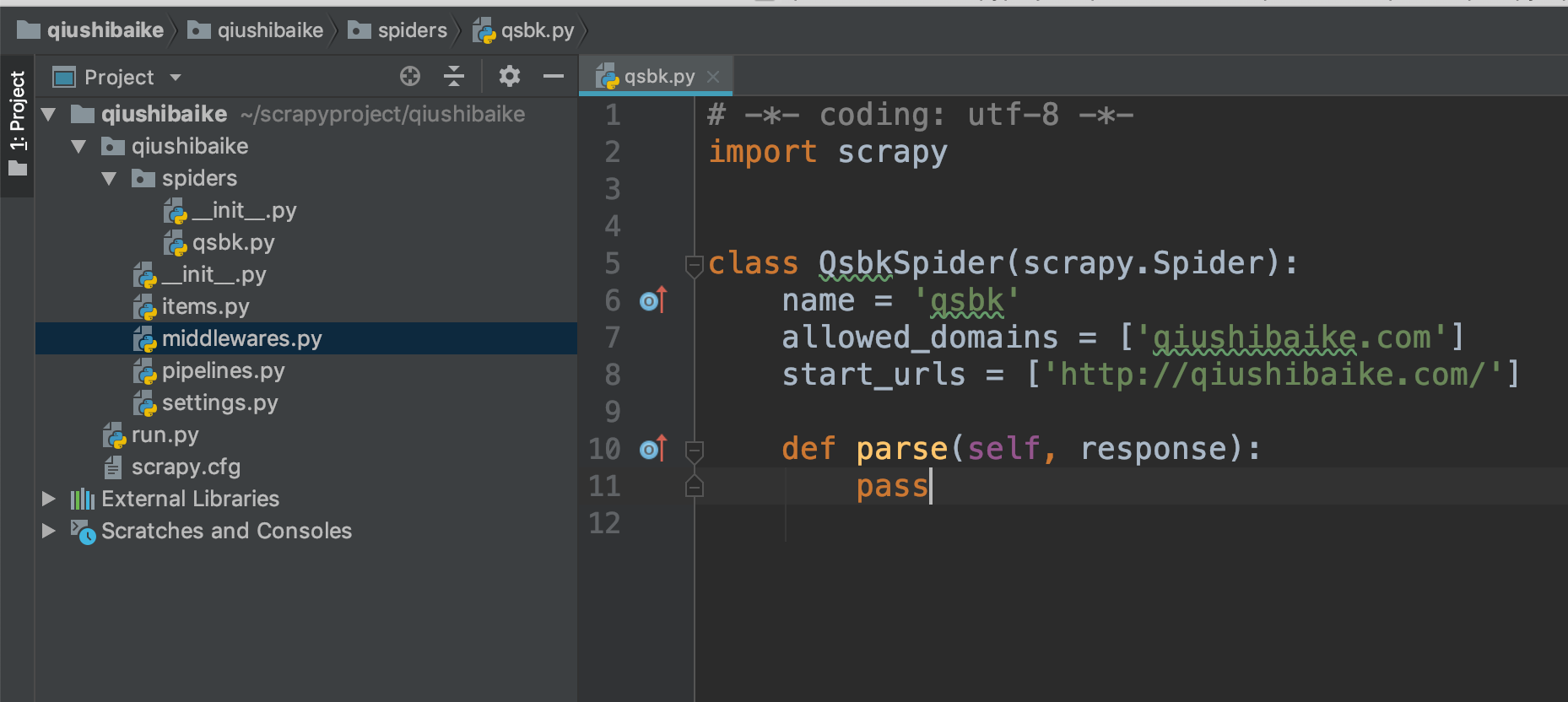
(注意:run.py是我后期自己添加的一个爬虫入口文件)
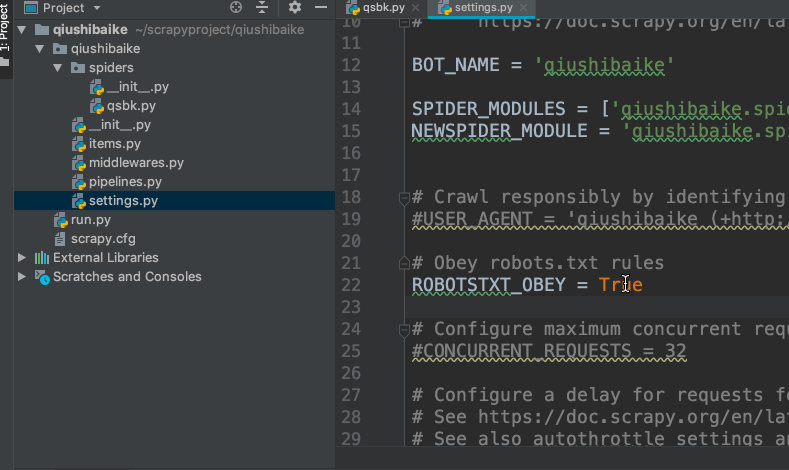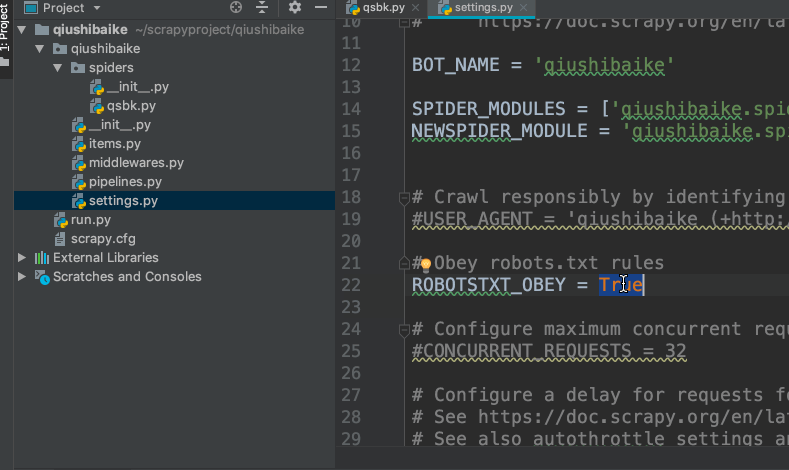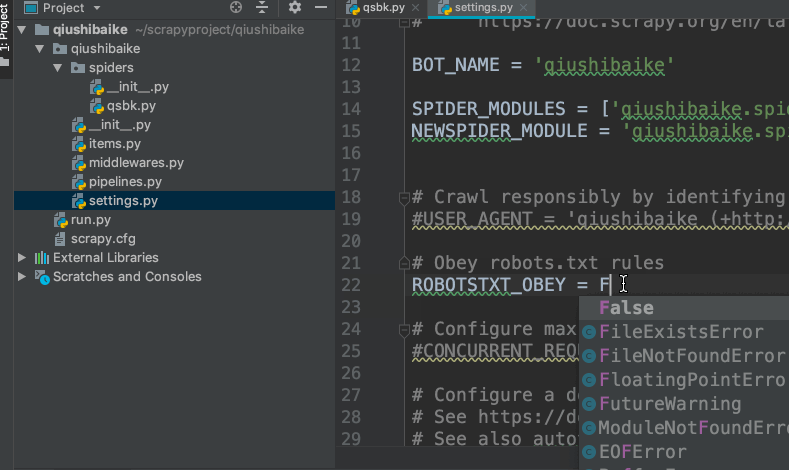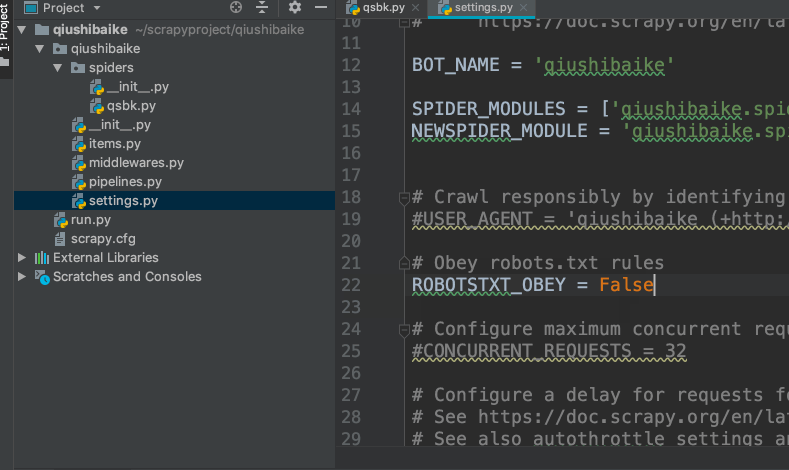
修改settings.py文件
无视robots协议,将
ROBOTSTXT_OBEY = True
改为
ROBOTSTXT_OBEY = False
修改spider.py
我们先来看看我们访问的网页源码对不对。
把qsbk.py 改为
# -*- coding: utf-8 -*-
import scrapy
class QsbkSpider(scrapy.Spider):
name = 'qsbk'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']#种子url,列表类型表示支持多个
def parse(self, response):
print(response.text)#输出源码
创建入口文件运行
在项目的根目录下创建一个run.py 来运行我们的工程
run.py的内容如下
# -*- coding: utf-8 -*-
# @Time : 2018/10/31 11:54 PM
# @Author : cxa
# @File : run.py.py
# @Software: PyCharm
from scrapy.cmdline import execute
execute(['scrapy','crawl','qsbk'])
运行以后我们发现一堆红色的信息,这些都是scrapy 的日志内容,我们注意找是否有黑色字体的内容,一般print出来的内容是黑色字体和含有error的信息,以此了解我们的爬虫哪个地方出错了,
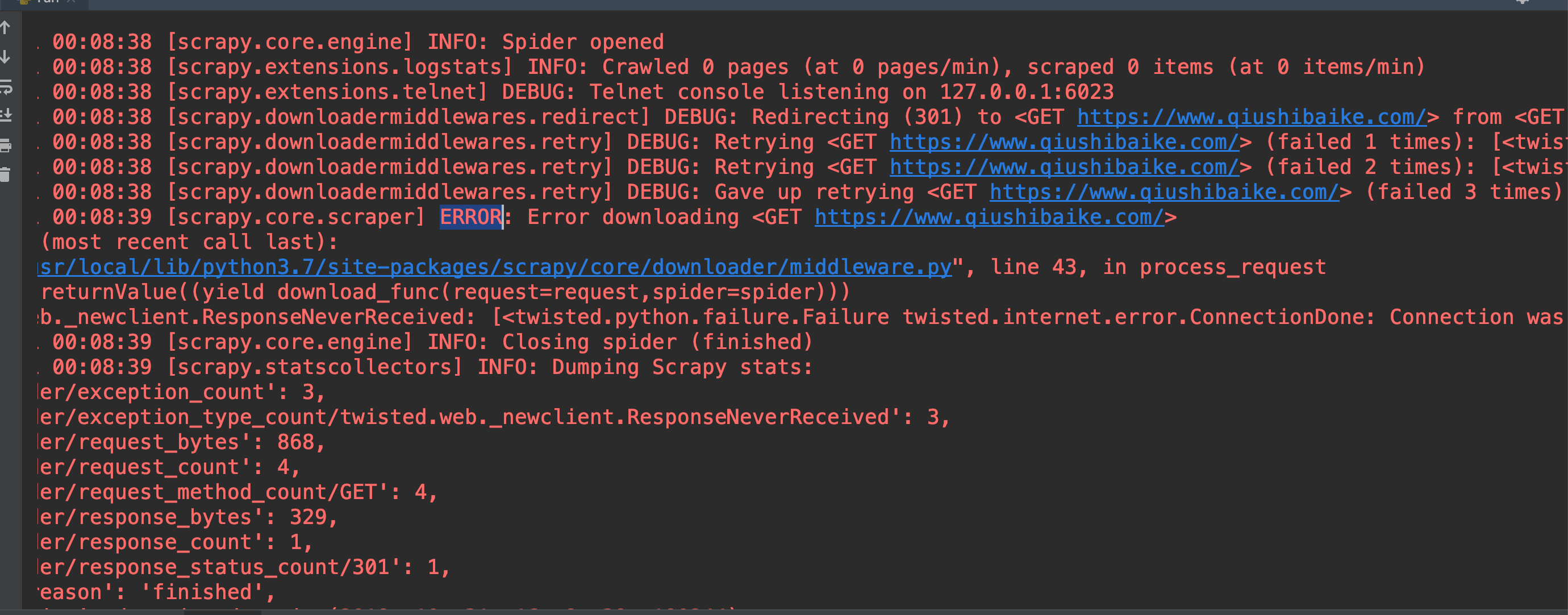
我们找到了error关键字,可以得知我们的爬虫出错了
2018-11-01 00:08:38 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.qiushibaike.com/> (failed 1 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionDone: Connection was closed cleanly.>]
2018-11-01 00:08:38 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.qiushibaike.com/> (failed 2 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionDone: Connection was closed cleanly.>]
2018-11-01 00:08:38 [scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET https://www.qiushibaike.com/> (failed 3 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionDone: Connection was closed cleanly.>]
2018-11-01 00:08:39 [scrapy.core.scraper] ERROR: Error downloading <GET https://www.qiushibaike.com/>
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/scrapy/core/downloader/middleware.py", line 43, in process_request
defer.returnValue((yield download_func(request=request,spider=spider)))
twisted.web._newclient.ResponseNeverReceived: [<twisted.python.failure.Failure twisted.internet.error.ConnectionDone: Connection was closed \
按照提示可以知道链接被关闭访问失败了,这种情况下我们就被反爬了,常见的应对措施是修改headers头,下面我们就通过修改中间件来修改headers。
修改中间件加入headers信息
首先修改middlewares.py
class UserAgentMiddleware(object):
def __init__(self, user_agent_list):
self.user_agent = user_agent_list
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
# 获取配置文件中的MY_USER_AGENT字段
middleware = cls(crawler.settings.get('MY_USER_AGENT'))
return middleware
def process_request(self, request, spider):
# 随机选择一个user-agent
request.headers['user-agent'] = random.choice(self.user_agent)
然后在settings启用我们的中间件和设定MY_USER_AGENT的值:
MY_USER_AGENT = ["Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36",
"Mozilla/5.0+(Windows+NT+5.1)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/28.0.1500.95+Safari/537.36+SE+2.X+MetaSr+1.0",
"Mozilla/5.0+(Windows+NT+6.1;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/50.0.2657.3+Safari/537.36"]
DOWNLOADER_MIDDLEWARES = {
'qiushibaike.middlewares.UserAgentMiddleware': 543,
}
然后我们再次运行,run.py文件。
再次运行
我们成功获取了源码,
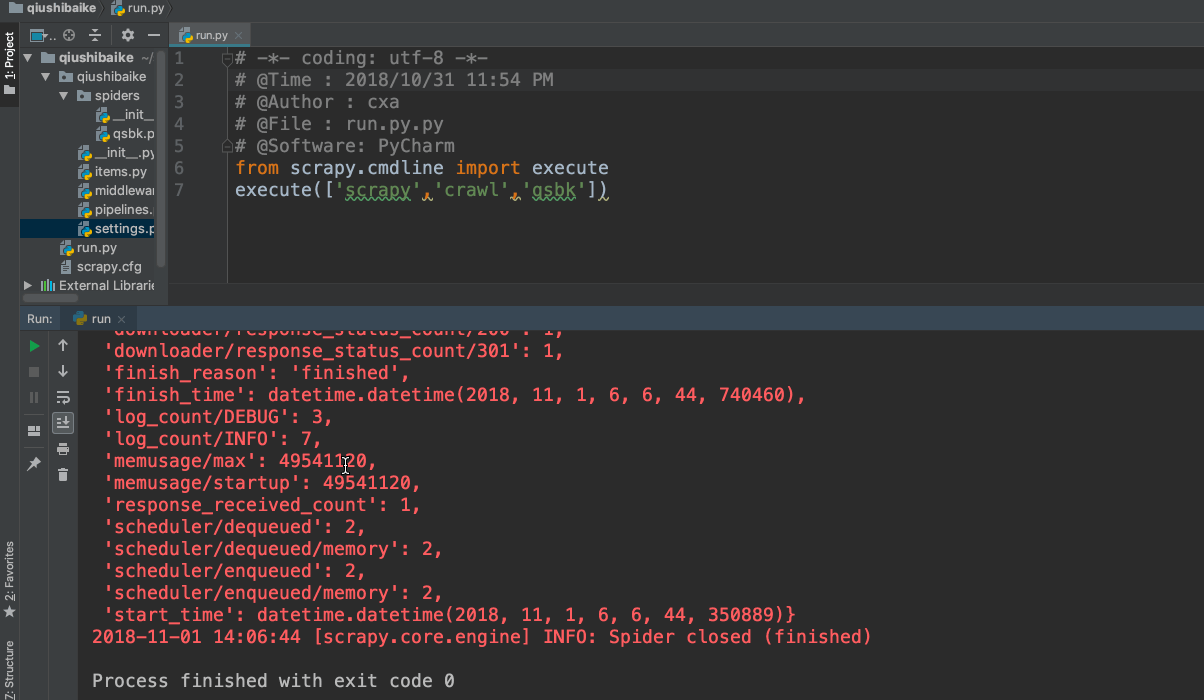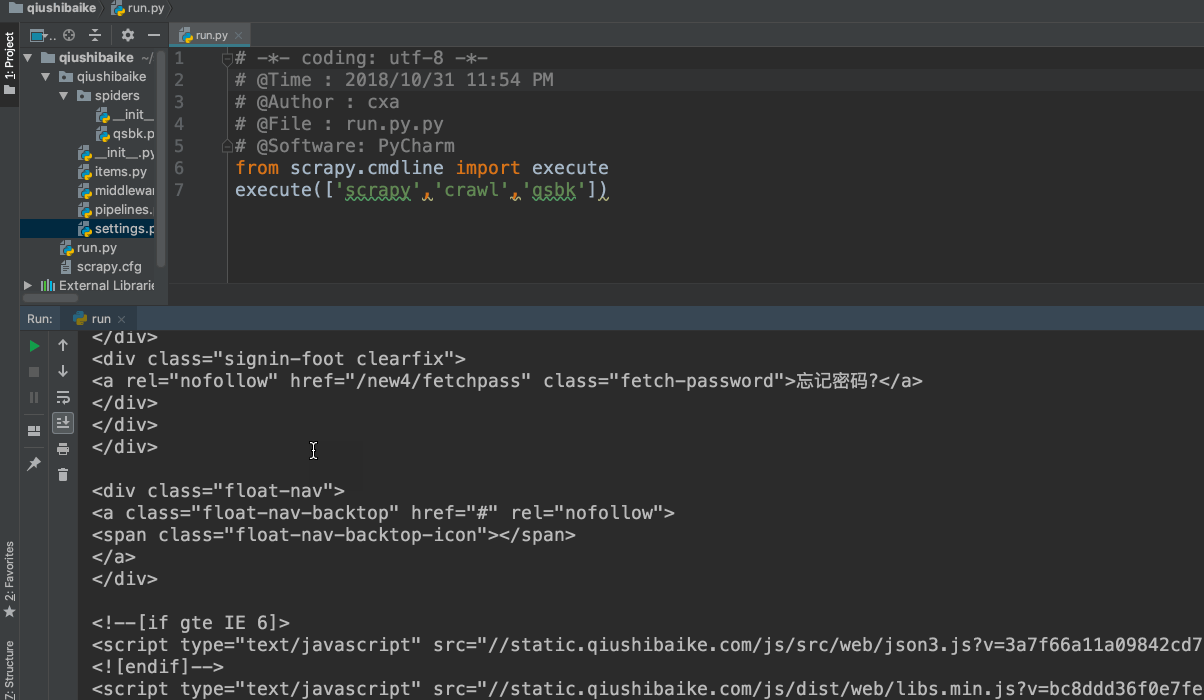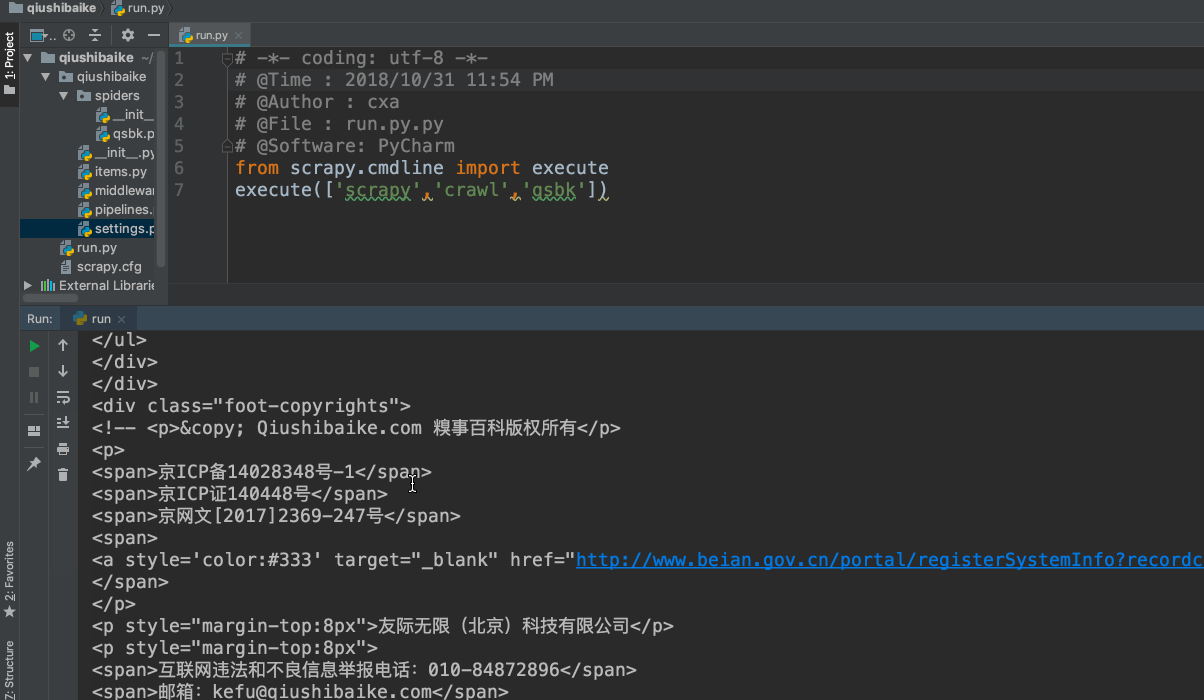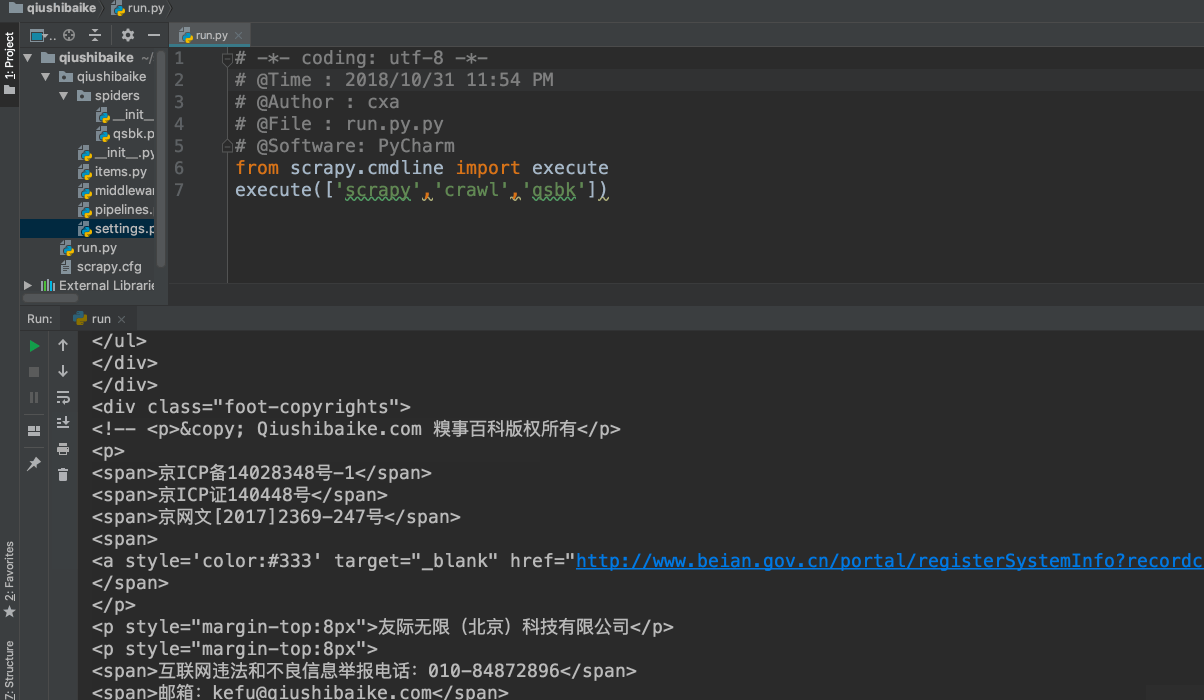
。然后我们就需要进行解析内容了。
解析网页中所需要的内容
因为这10页的结构是类似的我们就拿第一页为例:
在这里我们使用的解析方法为xpath,通过xpath可以解析出我们需要的内容,
打开谷歌浏览器的开发者工具,首先通过Elements模块获取当前页所有内容的大概区域我们可以写这样的一个xpath。
"//div[@id='content-left']"
然后我们发现一页25个内容,然后再去在每个内容里进行查找当前的标题和内容。
在qsbk.py文件的parse方法里加入这段内容
content_left_node=response.xpath("//div[@id='content-left']") #确定发布区的节点区域
div_node_list=content_left_node.xpath("./div")
for div_node in div_node_list:
title_node=div_node.xpath(".//div[@class='author clearfix']/a[contains(@onclick,'web-list-author-text')]/h2/text()")
content_node=div_node.xpath(".//div[@class='content']/span[1]")
content=content_node.xpath('string(.)')
print("发布者",title_node.extract_first().strip())
print("发布内容",content.extract_first().strip())
修改scrapy的日志显示等级方便查看
前面运行过程中我们发现scrapy的日志信息非常的多,不容易找到我们想要的内容,这个时候我们可以通过修改settings.py文件通过修改log的等级,只显示指定类型的log,打开settings.py我们加上下面的一句来设定log的等级为error
也就是只有错误的时候才显示scrapy的log信息。
LOG_LEVEL = "ERROR"
然后再次运行,看到了我们我们需要的内容发布者和发布内容。
得到了这些我们现在只是打印了下,下面我们就来说如何存储
保存结果到mongodb
mongodb是一个key-value型的数据库,使用起来简单,数据结构是键值对类型,在存储过程中如果表不存在就会创建一个新的表。
下面我们开始来存储我们的数据。
构造数据
因为我们需要接收一个键值对类型的数据,一般用dict,所以我们将代码改成如下形式。qsbk.py文件新增内容:
item = {}
item['name'] = name
item['info'] = info
yield item
上面我们构造出了我们需要存储的数据,然后通过yield传递到存储部分,
下一步我们就要开始创建mongo连接的部分了。
创建mongo连接文件
把pipelines.py 文件改为
import pymongo
from scrapy.conf import settings
class MongoPipeline(object):
def __init__(self):
# 链接数据库
self.client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['MONGO_PORT'])
if settings.get('MINGO_USER'):
self.client.admin.authenticate(settings['MINGO_USER'], settings['MONGO_PSW'])
self.db = self.client[settings['MONGO_DB']] # 获得数据库
self.coll = self.db[settings['MONGO_COLL']] # 获得collection
def process_item(self, item, spider):
postItem = dict(item) # 把item转化成字典形式
self.coll.insert(postItem) # 向数据库插入一条记录
return item
然后修改settings.py,首先添加mongo的几个连接参数
MONGO_HOST = "127.0.0.1" # 主机IP
MONGO_PORT = 27017 # 端口号
MONGO_DB = "spider_data" # 库名
MONGO_COLL = "qsbk" # collection名
然后打开pipe通道
ITEM_PIPELINES = {
'qiushibaike.pipelines.MongoPipeline': 300,
}
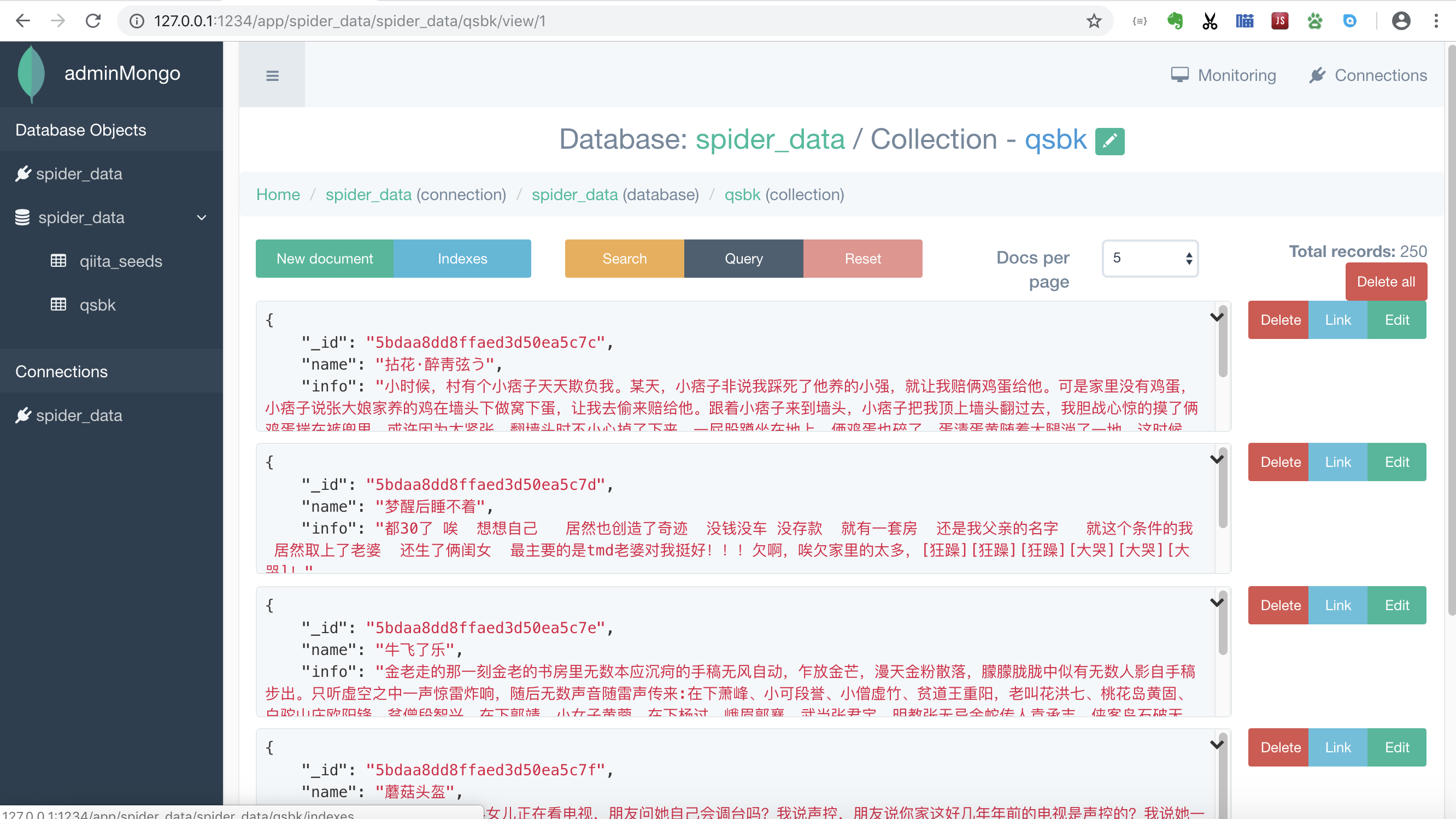
运行查看数据
我这里用的adminmongo,打开adminmogo连接数据库,可以看到我们数据已经存在了。
结语
到此为止,我们一个简单完整的scrapy小项目就完成了。 为了方便查看代码已经上传git:https://github.com/muzico425/qsbk.git
更多爬虫学习以及python技巧,请关注公众号:python学习开发。

- 点赞
- 收藏
- 关注作者
评论(0)