你对贝叶斯统计都有怎样的理解?


作者:王冲
链接:https://www.zhihu.com/question/21134457/answer/40753337
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
谢邀。
Bayesian学派说概率是一个人对于一件事的信念强度,概率是主观的。而频率派是说概率是客观的。所有能用客观概率假设能解的题,用主观概率假设也都能解,答案一样。对于两者都能解的题,主观概率假设和客观概率假设会得到同样的答案。
更严格的说法在《概率论沉思录》有证明。该书证明了假设现实中有一个客观概率,比如某物理现象出现的概率是0.5。那么,在给定足够充分的信息的情况下,主观概率都会逼近客观概率。
为什么主观概率会接近于客观概率?或者说,为什么人类可以通过头脑认识世界?
想象一下,如果主观概率不会接近于客观概率,也就意味着人脑认识不了客观世界,然后人类的一切推理、探索、发现、认识,都只是人类的幻想,这是否让人不寒而栗?
谢天谢地,我们生活在一个人脑恰好可以理解的世界里。这也是本书英文标题《probability: the logic of science》的意义,谢天谢地,我们今天的科学不是幻影。可是,为什么?客观概率是外部世界的演化,而人脑是内部世界的思考,它们凭什么恰好一致?
这是因为进化和人择原理。主观概率是在刻画人脑的思考过程。如果主观概率不逼近客观概率,也就是人脑无法通过思考获得现实的真相,人类这个物种根本就活不下来。而另外一方面,概率论的基础其实很简单,就是几条公理。看起来复杂的人类智能,其实就是基于这几条简单的公理。所以,自然演化这么一个简单的过程,能够恰好演化出一个复合概率论的神经细胞和人脑,其实没有想象中那么神奇。沿着这条路往下走,我们可以推导出很多关于人脑和进化的知识。我当时想到这一部分的时候,感到如痴如醉。我们今天已经有很多关于人类智能的零散的知识,我真希望自己能活着看到人工智能实现的那一天。
在上面的讨论中,我不加证明的声称"主观概率是在刻画人脑的思考过程“,有证据吗?
有的。《概率论沉思录》基于主观概率假设和几个其他的假设(这几个假设是从大部分人的思考过程中抽象出来的),用严格的逻辑推理证明概率论的几大公理。也就是说,概率论的几大公理可以完全由人脑思考过程的几个特点推理出来。概率论是今天这个样子,且只能是今天这个样子。
在后续的章节中,作者举了大量的例子,用严格的数学计算来解释我们日常生活中的种种推理,比如福尔摩斯破案,比如为什么人类社会中存在意见极化的现象(一个新的关于转基因的实验出来,为什么反对者只是更加反对,支持者变得更加支持。)。这些推理初看起来都是人的不理性,也就是不遵从概率论来推理,但是仔细分析之后,就会发现看起来最不理性的现象,其实还是可以用概率论解释的。
另外说一句,这些现象是不能用客观概率来刻画的。只能用主观概率假设,整个推理过程才有意义。
我们应该在中学教育中传授逻辑和Bayesian概率论。逻辑给予我们清晰思考的基础,但是日常生活中的思考,因为信息不充分性,其实更接近于Bayesian概率论,同样清晰、严谨,但允许在信息不充分的情况下进行推理。这或许能够帮助我们创造一个更好的社会。
最近我自己在学习一些关于机器学习的东西,目前学到了贝叶斯统计这一块,我觉得很感兴趣,于是便找了一些资料看了看,在自己琢磨一段时间后,写了一篇博客,原文地址:机器学习(一) —— 浅谈贝叶斯和MCMC。正好题主也说了希望从哲学角度解释一下,我自认为文章写得还算深入浅出,能给大家带来帮助。
为了有打广告之嫌疑,我还是内文章内主要的内容在这里重新编辑一遍,省去全文中MCMC和sklearn的部分,有兴趣的可以自行前往。
浅谈贝叶斯
不论是学习概率统计还是机器学习的过程中,贝叶斯总是是绕不过去的一道坎,大部分人在学习的时候都是在强行地背公式和套用方法,没有真正去理解其牛逼的思想内涵。我看了一下自己学校里一些涉及到贝叶斯统计的课程,content里的第一条都是 Philosophy of Bayesian statistics。
历史背景
什么事都要从头说起,贝叶斯全名为托马斯·贝叶斯(Thomas Bayes,1701-1761),是一位与牛顿同时代的牧师,是一位业余数学家,平时就思考些有关上帝的事情,当然,统计学家都认为概率这个东西就是上帝在掷骰子。当时贝叶斯发现了古典统计学当中的一些缺点,从而提出了自己的“贝叶斯统计学”,但贝叶斯统计当中由于引入了一个主观因素(先验概率,下文会介绍),一点都不被当时的人认可。直到20世纪中期,也就是快200年后了,统计学家在古典统计学中遇到了瓶颈,伴随着计算机技术的发展,当统计学家使用贝叶斯统计理论时发现能解决很多之前不能解决的问题,从而贝叶斯统计学一下子火了起来,两个统计学派从此争论不休。
什么是概率?
什么是概率这个问题似乎人人都觉得自己知道,却有很难说明白。比如说我问你 掷一枚硬币为正面的概率为多少?,大部分人第一反应就是50%的几率为正。不好意思,首先这个答案就不正确,只有当材质均匀时硬币为正面的几率才是50%(所以不要觉得打麻将的时候那个骰子每面的几率是相等的,万一被做了手脚呢)。好,那现在假设硬币的材质是均匀的,那么为什么正面的几率就是50%呢?有人会说是因为我掷了1000次硬币,大概有492次是正面,508次是反面,所以近似认为是50%,说得很好(掷了1000次我也是服你)。
掷硬币的例子说明了古典统计学的思想,就是概率是基于大量实验的,也就是 大数定理。那么现在再问你,有些事件,例如:明天下雨的概率是30%;A地会发生地震的概率是5%;一个人得心脏病的概率是40%…… 这些概率怎么解释呢?难道是A地真的100次的机会里,地震了5次吗?肯定不是这样,所以古典统计学就无法解释了。再回到掷硬币的例子中,如果你没有机会掷1000次这么多次,而是只掷了3次,可这3次又都是正面,那该怎么办?难道这个正面的概率就是100%了吗?这也是古典统计学的弊端。
举个例子:生病的几率
一种癌症,得了这个癌症的人被检测出为阳性的几率为90%,未得这种癌症的人被检测出阴性的几率为90%,而人群中得这种癌症的几率为1%,一个人被检测出阳性,问这个人得癌症的几率为多少?
猛地一看,被检查出阳性,而且得癌症的话阳性的概率是90%,那想必这个人应该是难以幸免了。那我们接下来就算算看。
我们用  表示事件 “测出为阳性”, 用 表示“得癌症”, 表示“未得癌症”。根据题目,我们知道如下信息:
表示事件 “测出为阳性”, 用 表示“得癌症”, 表示“未得癌症”。根据题目,我们知道如下信息:
那么我们现在想得到人群中检测为阳性且得癌症的几率 :
这里 表示的是联合概率,得癌症且检测出阳性的概率是人群中得癌症的概率乘上得癌症时测出是阳性的几率,是0.009。同理可得未得癌症且检测出阳性的概率:
这个概率是什么意思呢?其实是指如果人群中有1000个人,检测出阳性并且得癌症的人有9个,检测出阳性但未得癌症的人有99个。可以看出,检测出阳性并不可怕,不得癌症的是绝大多数的,这跟我们一开始的直觉判断是不同的!可直到现在,我们并没有得到所谓的“在检测出阳性的前提下得癌症的 概率 ”,怎么得到呢?很简单,就是看被测出为阳性的这108(9+99)人里,9人和99人分别占的比例就是我们要的,也就是说我们只需要添加一个归一化因子(normalization)就可以了。所以阳性得癌症的概率 为:, 阳性未得癌症的概率 为: 。 这里 , 中间多了这一竖线 成为了条件概率,而这个概率就是贝叶斯统计中的 后验概率!而人群中患癌症与否的概率 就是 先验概率!我们知道了先验概率,根据观测值(observation),也可称为test evidence:是否为阳性,来判断得癌症的后验概率,这就是基本的贝叶斯思想,我们现在就能得出本题的后验概率的公式为:
由此就能得到如下的贝叶斯公式的一般形式。
贝叶斯公式
我们把上面例题中的 变成样本(sample) , 把 变成参数(parameter) , 我们便得到我们的贝叶斯公式:
可以看出上面这个例子中, 事件的分布是离散的,所以在分母用的是求和符号 。那如果我们的参数的分布是连续的呢?没错,那就要用积分,于是我们终于得到了真正的 贝叶斯公式 :
其中指的是参数的概率分布, 指的是先验概率,指的是后验概率, 指的是我们观测到的样本的分布,也就是似然函数(likelihood),记住 竖线左边的才是我们需要的。其中积分求的区间 指的是参数 所有可能取到的值的域,所以可以看出后验概率 是在知道 的前提下在 域内的一个关于 的概率密度分布,每一个 都有一个对应的可能性(也就是概率)。
理解贝叶斯公式
这个公式应该在概率论书中就有提到,反正当时我也只是死记硬背住,然后遇到题目就套用。甚至在国外读书时学了一门统计推断的课讲了贝叶斯,大部分时间我还是在套用公式,直到后来结合了一些专门讲解贝叶斯的课程和资料才有了一些真正的理解。要想理解这个公式,首先要知道这个竖线 的两侧一会是 ,一会是 到底指的是什么,或者说似然函数和参数概率分布到底指的是什么。
似然函数
首先来看似然函数 ,似然函数听起来很陌生,其实就是我们在概率论当中看到的各种概率分布 ,那为什么后面要加个参数 呢?我们知道,掷硬币这个事件是服从伯努利分布的 , 次的伯努利实验就是我们熟知的二项分布 , 这里的 就是一个参数,原来我们在做实验之前,这个参数就已经存在了(可以理解为上帝已经定好了),我们抽样出很多的样本 是为了找出这个参数,我们上面所说的掷硬币的例子,由于我们掷了1000次有492次是正面,根据求期望的公式 (492就是我们的期望)可以得出参数为 ,所以我们才认为正面的概率是近似50%的。
现在我们知道了,其实我们观测到样本的分布是在以某个参数为前提下得出来的,所以我们记为 ,只是我们并不知道这个参数是多少。所以 参数估计 成为了统计学里很大的一个课题,古典统计学中常用的方法有两种:矩方法(momnet) 和 最大似然估计(maximum likelihood estimate, mle) ,我们常用的像上面掷硬币例子中求均值的方法,本质就是矩估计方法,这是基于大数定理的。而统计学中更广泛的是使用最大似然估计的方法,原理其实很简单,在这简单说一下:假设我们有个样本 , 它们每一个变量都对应一个似然函数:
我们现在把这些似然函数乘起来:
我们只要找到令这个函数最大的 值,便是我们想要的参数值(具体计算参考[2]中p184)。
后验分布(Posterior distribution)
现在到了贝叶斯的时间了。以前我们想知道一个参数,要通过大量的观测值才能得出,而且是只能得出一个参数值。而现在运用了贝叶斯统计思想,这个后验概率分布其实是一系列参数值的概率分布,再说简单点就是我们得到了许多个参数及其对应的可能性,我们只需要从中选取我们想要的值就可以了:有时我们想要概率最大的那个参数,那这就是 后验众数估计(posterior mode estimator);有时我们想知道参数分布的中位数,那这就是 后验中位数估计(posterior median estimator);有时我们想知道的是这个参数分布的均值,那就是 后验期望估计。这三种估计没有谁好谁坏,只是提供了三种方法得出参数,看需要来选择。现在这样看来得到的参数是不是更具有说服力?
置信区间和可信区间
在这里我想提一下 置信区间(confidence interval, CI) 和 可信区间(credibility interval,CI),我觉得这是刚学贝叶斯时候非常容易弄混的概念。
再举个例子:一个班级男生的身高可能服从某种正态分布 ,然后我们把全班男生的身高给记录下来,用高中就学过的求均值和方差的公式就可以算出来这两个参数,要知道我们真正想知道的是这个参数 ,当然样本越多,得出的结果就接近真实值(其实并没有人知道什么是真实值,可能只有上帝知道)。等我们算出了均值和方差,我们这时候一般会构建一个95%或者90%的置信区间,这个置信区间是对于 样本来说的,我只算出了一个 和 一个 参数值的情况下,95%的置信区间意味着在这个区间里的样本是可以相信是服从以为参数的正态分布的,一定要记住置信区间的概念中是指 一个参数值 的情况下!
而我们也会对我们得到的后验概率分布构造一个90%或95%的区间,称之为可信区间。这个可信区间是对于 参数来说的,我们的到了 很多的参数值,取其中概率更大一些的90%或95%,便成了可信区间。
先验分布(Prior distribution)
说完了后验分布,现在就来说说先验分布。先验分布就是你在取得实验观测值以前对一个参数概率分布的 主观判断,这也就是为什么贝叶斯统计学一直不被认可的原因,统计学或者数学都是客观的,怎么能加入主观因素呢?但事实证明这样的效果会非常好!
再拿掷硬币的例子来看(怎么老是拿这个举例,是有多爱钱。。。),在扔之前你会有判断正面的概率是50%,这就是所谓的先验概率,但如果是在打赌,为了让自己的描述准确点,我们可能会说正面的概率为0.5的可能性最大,0.45的几率小点,0.4的几率再小点,0.1的几率几乎没有等等,这就形成了一个先验概率分布。
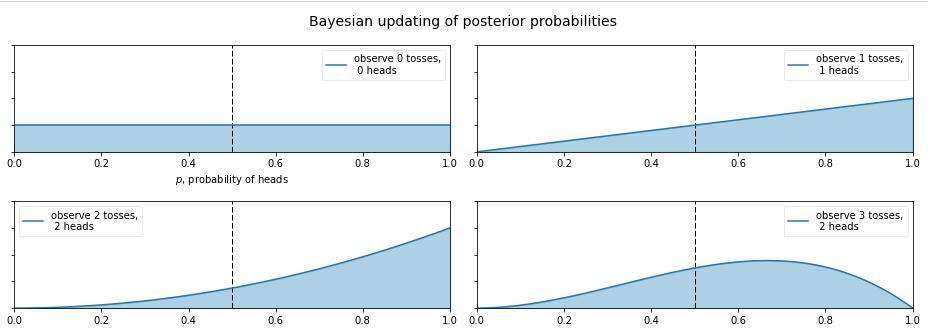
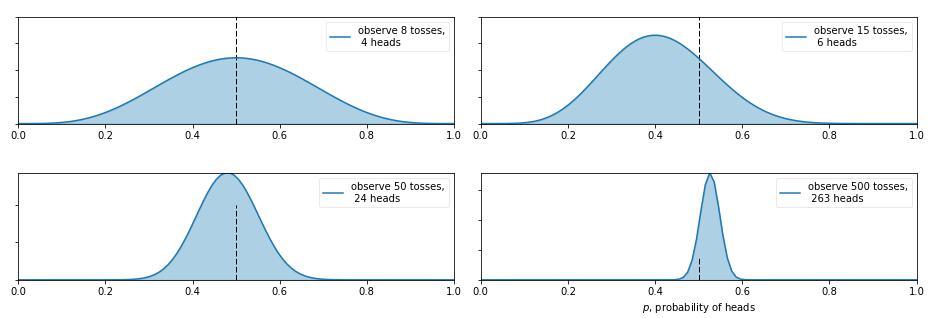
那么现在又有新的问题了,如果我告诉你这个硬币的材质是不均匀的,那正面的可能性是多少呢?这就让人犯糊涂了,我们想有主观判断也无从下手,于是我们就想说那就先认为0~1之间每一种的可能性都是相同的吧,也就是设置成0~1之间的均匀分布 作为先验分布吧,这就是贝叶斯统计学当中的 无信息先验(noninformative prior)!那么下面我们就通过不断掷硬币来看看,这个概率到是多少,贝叶斯过程如下: (图来自[3])
<img src="https://pic1.zhimg.com/50/v2-3ef5e8c52f6257d7624dcae8496dc14c_hd.jpg" data-caption="" data-rawwidth="928" data-rawheight="334" class="origin_image zh-lightbox-thumb" width="928" data-original="https://pic1.zhimg.com/v2-3ef5e8c52f6257d7624dcae8496dc14c_r.jpg">

<img src="https://pic2.zhimg.com/50/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_hd.jpg" data-caption="" data-rawwidth="937" data-rawheight="318" class="origin_image zh-lightbox-thumb" width="937" data-original="https://pic2.zhimg.com/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_r.jpg">

从图中我们可以看出,0次试验的时候就是我们的先验假设——均匀分布,然后掷了第一次是正面,于是概率分布倾向于1,第二次又是正,概率是1的可能性更大了,但 注意:这时候在0.5的概率还是有的,只不过概率很小,在0.2的概率变得更小。第三次是反面,于是概率分布被修正了一下,从为1的概率最大变成了2/3左右最大(3次试验,2次正1次反当然概率是2/3的概率最大)。再下面就是进行更多次的试验,后验概率不断根据观测值在改变,当次数很大的时候,结果趋向于0.5(哈哈,结果这还是一枚普通的硬币,不过这个事件告诉我们,直觉是不可靠的,一定亲自实验才行~)。有的人会说,这还不是在大量数据下得到了正面概率为0.5嘛,有什么好稀奇的? 注意了!画重点了!(敲黑板) 记住,不要和一个统计学家或者数学家打赌!跑题了,跑题了。。。说回来,我们上面就说到了古典概率学的弊端就是如果掷了2次都是正面,那我们就会认为正面的概率是1,而在贝叶斯统计学中,如果我们掷了2次都是正面,只能说明正面是1的可能性最大,但还是有可能为0.5, 0.6, 0.7等等的,这就是对古典统计学的一种完善和补充,于是我们也就是解释了,我们所谓的 地震的概率为5%;生病的概率为10%等等这些概率的意义了,这就是贝叶斯统计学的哲学思想。
共轭先验(Conjugate prior)
共轭先验应该是每一个贝叶斯统计初学者最头疼的问题,我觉得没有“之一”。这是一个非常大的理论体系,我试着用一些简单的语言进行描述,关键是去理解其思想。
继续拿掷硬币的例子,这是一个二项试验 ,所以其似然函数为:
在我们不知道情况时就先假设其先验分布为均匀分布 ,即:
那现在根据贝叶斯公式求后验概率分布:
我们得到结果为:
这么一大串是什么呢?其实就是大名鼎鼎的贝塔分布(Beta distribution)。 简写就是 。 比如我掷了10次(n=10),5次正(x=5),5次反,那么结果就是 , 这个分布的均值就是0.5( ),很符合我们想要的结果。
现在可以说明,我们把主观揣测的先验概率定为均匀分布是合理的,因为我们在对一件事物没有了解的时候,先认为每种可能性都一样是非常说得通的。有人会认为,既然无信息先验是说得通的,而且贝叶斯公式会根据我们的观测值不断更新后验概率,那是不是我们随便给一个先验概率都可以呢?当然......不行!!这个先验概率是不能瞎猜的,是需要根据一些前人的经验和常识来判断的。比如我随便猜先验为一个分段函数:
靠,是不是很变态的一个函数...就是假设一个极端的情况,如果你把这个情况代入贝叶斯公式,结果是不会好的(当然我也不知道该怎么计算)。
这个例子中,我看到了可能的后验分布是 分布,看起来感觉有点像正态分布啊,那我们用正态分布作为先验分布可以吗?这个是可以的(所以要学会观察)。可如果我们把先验分布为正态分布代入到贝叶斯公式,那计算会非常非常麻烦,虽然结果可能是合理的。那怎么办?不用担心,因为我们有共轭先验分布!
继续拿上面这个例子,如果我们把先验分布 设为贝塔分布 ,结果是什么呢?我就不写具体的计算过程啦,直接给结果:
有没有看到,依然是贝塔分布,结果只是把之前的1换成了 (聪明的你可能已经发现,其实我们所说的均匀分布 等价于 ,两者是一样的)。
由此我们便可以称 二项分布的共轭先验分布为贝塔分布!注意!接着画重点!:共轭先验这个概念必须是基于似然函数来讨论的,否则没有意义! 好,那现在有了共轭先验,然后呢?作用呢?这应该是很多初学者的疑问。
现在我们来看,如果你知道了一个观测样本的似然函数是二项分布的,那我们把先验分布直接设为 ,于是我们就 不用计算复杂的含有积分的贝叶斯公式 便可得到后验分布 了!!!只需要记住试验次数 ,和试验成功事件次数 就可以了!互为共轭的分布还有一些,但都很复杂,用到的情况也很少,推导过程也极其复杂,有兴趣的可以自行搜索。我说的这个情况是最常见的!
,这个先验概率对结果的影响会很小,可如果我们设为 ,那么我们做10次试验就算是全是正面的,后验分布都没什么变化。参考书籍
[1]韦来生,《贝叶斯统计》,高等教育出版社,2016
[2]John A.Rice, 《数理统计与数据分析》(原书第三版), 机械工业出版社, 2016
[3]Cameron Davidson-Pilon, Probabilistic Programming and Bayesian Methods for Hackers(https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers), 2016
本文转载自异步社区
原文链接:
| https://www.epubit.com/articleDetails?id=Ne8ce37b2-19b4-4166-8291-dd872ac48f13 |

{kind=link}
{kind=link}
- 点赞
- 收藏
- 关注作者
评论(0)