HashMap源码解读(下篇)

前言
上一篇博主对HashMap中的属性和Put方法进行了逐句解读,链接如下:
本篇将解读HashMap的resize()方法,构造方法,以及拓展一些HashMap中的特性。
一、Put方法核心流程
1 若HashMap还未初始化,先进行哈希表的初始化操作(默认初始化为16个桶)
2.对传入的Key值做hash,得出要存放该元素的桶编号
- a.若没有发生碰撞,即头节点为空,将该节点直接存放到桶中作为头节点
- b.若发生碰撞
(1) 此时桶中的链表已经树化,将节点构造为树节点后加入红黑树
(2) 链表还未树化,将节点作为链表的最后一个节点入链表
3.若哈希表中存在key值相同的元素,替换为最新的value值
4.若桶满了(++size是否大于threshold),调用resize()扩容哈希表。(threshold = 容量*负载因子)
二、自定义类型当作Key传入
现自定义一个Student类:
class Student {
private String name;
private int age;
}
若自定义的类型需要保存到Map的Key中,则需要同时覆写hashCode和equals,equals相同的俩对象,hashCode必须相同,反之不一定。
覆写后,Student类如下:
class Student {
private String name;
private int age;
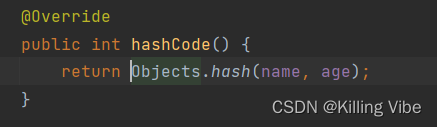
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Student) {
Student stu = (Student) obj;
return this.age == stu.age && this.name.equals(stu.name);
}
return false;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
注意:代码中返回的是Object的工具类Objects,传入的属性值相同返回相同的hash值。
三、HashMap的构造方法
3.1 无参构造器如下:

当new一个HashMap的时候,若没有指定HashMap大小,默认调用无参构造器,可是此时内部数组还没有初始化,代码中只是简单的把负载因子初始化了,只有当第一次调用put方法时才初始化内部哈希桶数组(懒加载模式)。 第一次使用(添加)时才初始化相应的内存。
3.2 有参构造器如下:
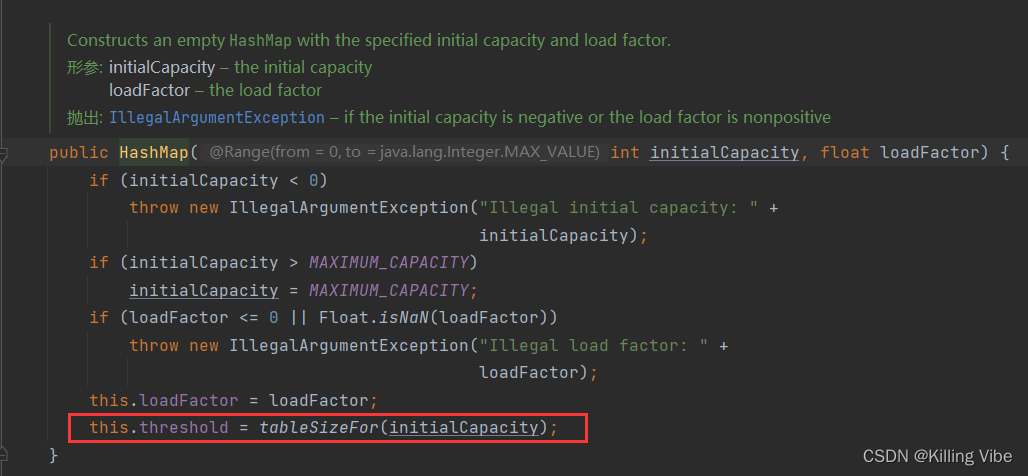
如图红色框框,代码检查传入的参数是否2的n次幂,若不是调整为最接近 的数。
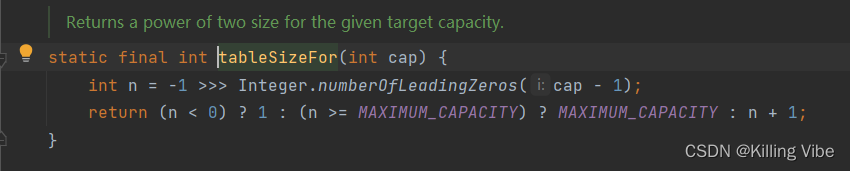
例如:传入31,实际上初始化后threshold为32。
三、resize方法
源码如下:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
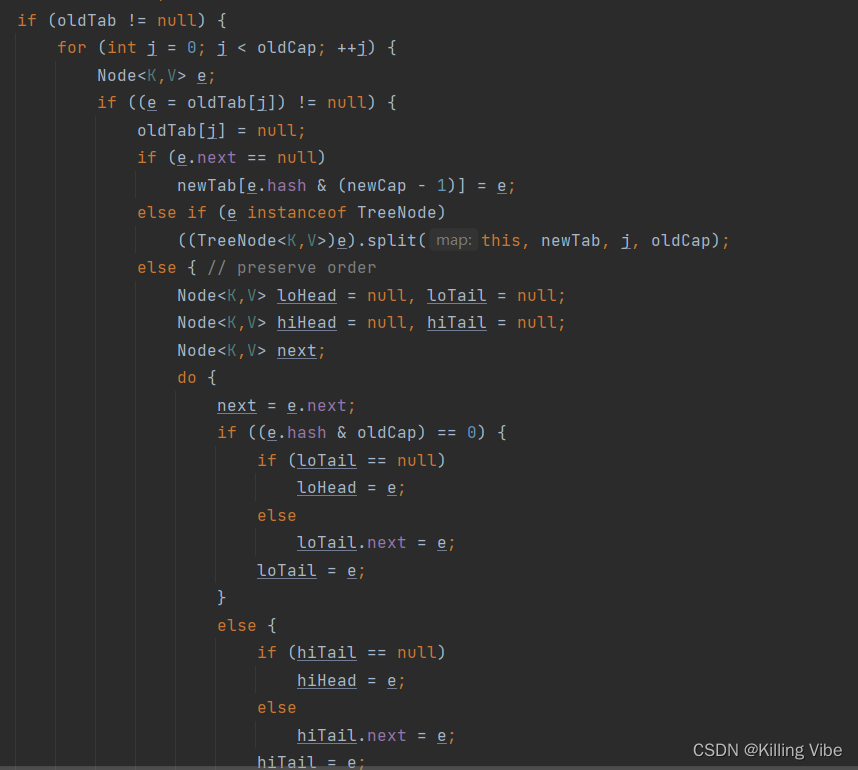
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
源码解读如下:
1.若oldTab 为 null ,则证明还没有初始化。
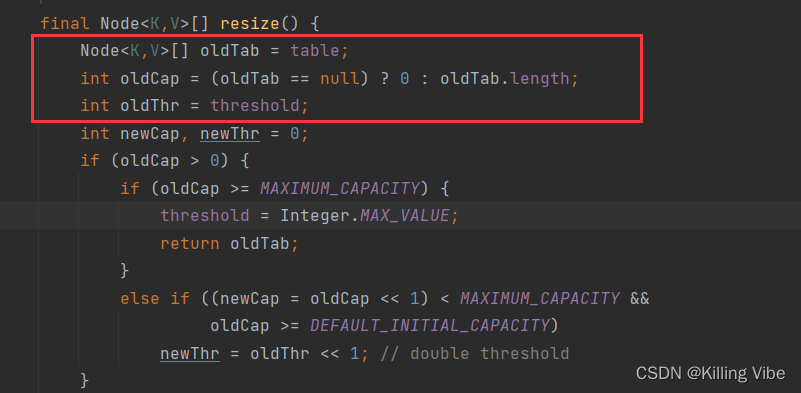 2. 当旧数组不为空的时候,新数组拓展为原数组的一倍。(扩容操作)
2. 当旧数组不为空的时候,新数组拓展为原数组的一倍。(扩容操作)
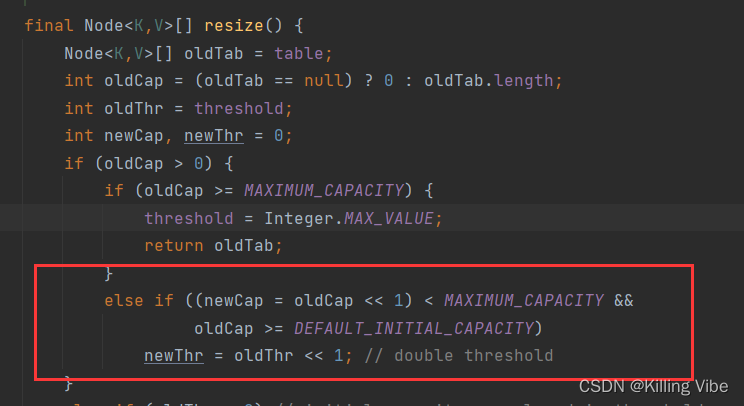
3.初始化操作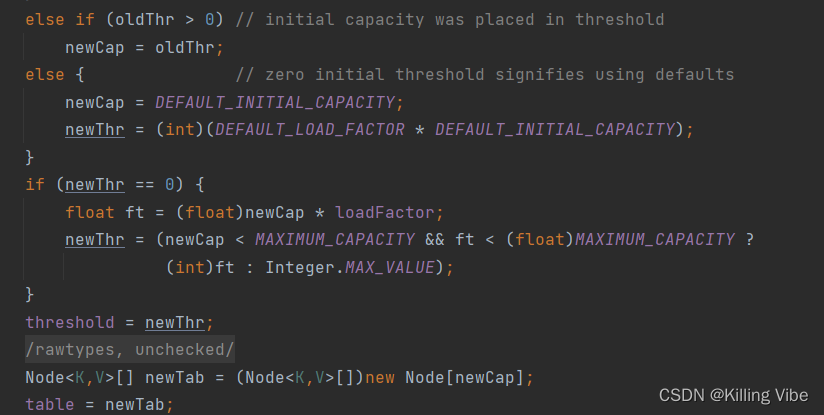
4.元素搬移操作,把链表上的元素头插到扩容后的哈希桶中。
四、Set集合和Map集合的关系(拓展)
先下结论:
Set集合的子类实际上在存储元素时就是放在了Map集合的Key中:
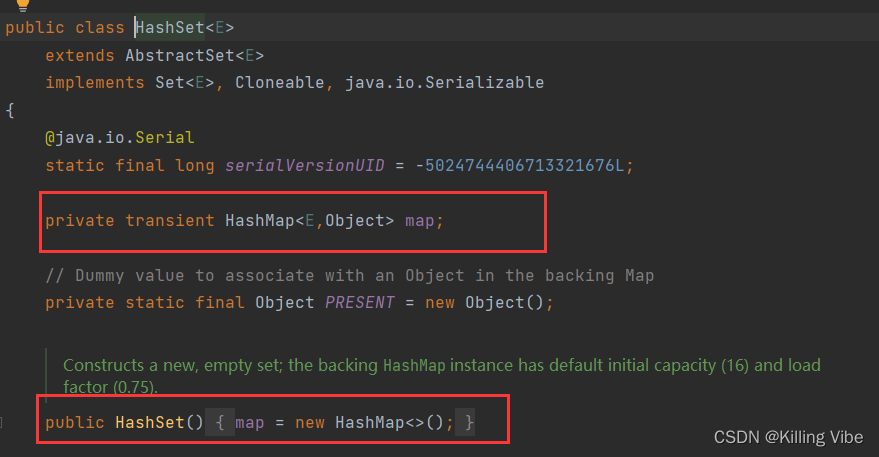
这也是为啥Set是不可重复的!!!
- HashSet其实就是使用HashMap保存的
- TreeSet其实就是使用TreeMap保存的
Set就是用的Map的子类来存储元素,Set的不可重复就是因为元素保存在了Map的Key上。
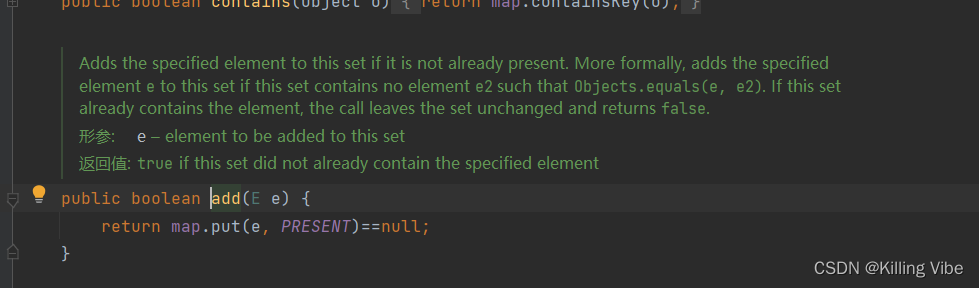
-
HashSet 可以保存null ,因为HashMap的key可以为null
-
TreeSet 不可以保存null ,因为TreeMap的key 不能为null。
总结
以上三篇就是HashMap的主要源码解读了,有帮助的话可以点个赞收藏起来慢慢学习~

- 点赞
- 收藏
- 关注作者
评论(0)