Pandas数据处理——渐进式学习1、Pandas入门基础


![]()
Pandas数据处理——渐进式学习
目录
前言
这个女娃娃是否有一种初恋的感觉呢,但是她很明显不是一个真正意义存在的图片,我们需要很复杂的推算以及各种炼丹模型生成的AI图片,我自己认为难度系数很高,我仅仅用了64个文字形容词就生成了她,很有初恋的感觉,符合审美观,对于计算机来说她是一组数字,可是这个数字是怎么推断出来的就是很复杂了,我们在模型训练中可以看到基本上到处都存在着Pandas处理,在最基础的OpenCV中也会有很多的Pandas处理,所以我OpenCV写到一般就开始写这个专栏了,因为我发现没有Pandas处理基本上想好好的操作图片数组真的是相当的麻烦,可以在很多AI大佬的文章中发现都有这个Pandas文章,每个人的写法都不同,但是都是适合自己理解的方案,我是用于教学的,故而我相信我的文章更适合新晋的程序员们学习,期望能节约大家的事件从而更好的将精力放到真正去实现某种功能上去。本专栏会更很多,只要我测试出新的用法就会添加,持续更新迭代,可以当做【Pandas字典】来使用,期待您的三连支持与帮助。
Pandas介绍
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。
Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas 的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。对于 R 用户,DataFrame 提供了比 R 语言 data.frame 更丰富的功能。Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
Pandas 就像一把万能瑞士军刀,下面仅列出了它的部分优势 :
- 处理浮点与非浮点数据里的缺失数据,表示为 NaN;
- 大小可变:插入或删除 DataFrame 等多维对象的列;
- 自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐;
- 强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
- 把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
- 基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
- 直观地合并(merge)、**连接(join)**数据集;
- 灵活地重塑(reshape)、**透视(pivot)**数据集;
- 轴支持结构化标签:一个刻度支持多个标签;
- 成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存 / 加载数据;
- 时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
这些功能主要是为了解决其它编程语言、科研环境的痛点。处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。
其它说明:
- Pandas 速度很快。Pandas 的很多底层算法都用 Cython 优化过。然而,为了保持通用性,必然要牺牲一些性能,如果专注某一功能,完全可以开发出比 Pandas 更快的专用工具。
- Pandas 是 statsmodels 的依赖项,因此,Pandas 也是 Python 中统计计算生态系统的重要组成部分。
- Pandas 已广泛应用于金融领域。
数据结构
| 维数 | 名称 | 描述 |
|---|---|---|
| 1 | Series | 带标签的一维同构数组 |
| 2 | DataFrame | 带标签的,大小可变的,二维异构表格 |
为什么有多个数据结构?
Pandas 数据结构就像是低维数据的容器。比如,DataFrame 是 Series 的容器,Series 则是标量的容器。使用这种方式,可以在容器中以字典的形式插入或删除对象。
此外,通用 API 函数的默认操作要顾及时间序列与截面数据集的方向。多维数组存储二维或三维数据时,编写函数要注意数据集的方向,这对用户来说是一种负担;如果不考虑 C 或 Fortran 中连续性对性能的影响,一般情况下,不同的轴在程序里其实没有什么区别。Pandas 里,轴的概念主要是为了给数据赋予更直观的语义,即用“更恰当”的方式表示数据集的方向。这样做可以让用户编写数据转换函数时,少费点脑子。
处理 DataFrame 等表格数据时,index(行)或 columns(列)比 axis 0 和 axis 1 更直观。用这种方式迭代 DataFrame 的列,代码更易读易懂:
for col in df.columns:
series = df[col]大小可变与数据复制
Pandas 所有数据结构的值都是可变的,但数据结构的大小并非都是可变的,比如,Series 的长度不可改变,但 DataFrame 里就可以插入列。
Pandas 里,绝大多数方法都不改变原始的输入数据,而是复制数据,生成新的对象。 一般来说,原始输入数据不变更稳妥。
Pandas 入门
环境包
这里我们主要需求是两个包:
import pandas as pd
import numpy as nppip下载方式:
pip install pandas
pip install numpy
生成对象·一维Series
用值列表生成 Series 时,Pandas 默认自动生成整数索引:
import pandas as pd
import numpy as np
# np.nan 是 not a number 中文翻译不是一个数字
s = pd.Series([9, 5, 2, np.nan, 7, 6])
print(s)
print("*" * 20)
print(type(s))
这里输出的时候能直接看到下标值,很直接。
![]()
这里我们如果遍历的话就看不到对应的下标了。
import pandas as pd
import numpy as np
# np.nan 是 not a number 中文翻译不是一个数字
s = pd.Series([9, 5, 2, np.nan, 7, 6])
for item in s:
print(item)
遍历效果:

![]()
查看索引
import pandas as pd
import numpy as np
# np.nan 是 not a number 中文翻译不是一个数字
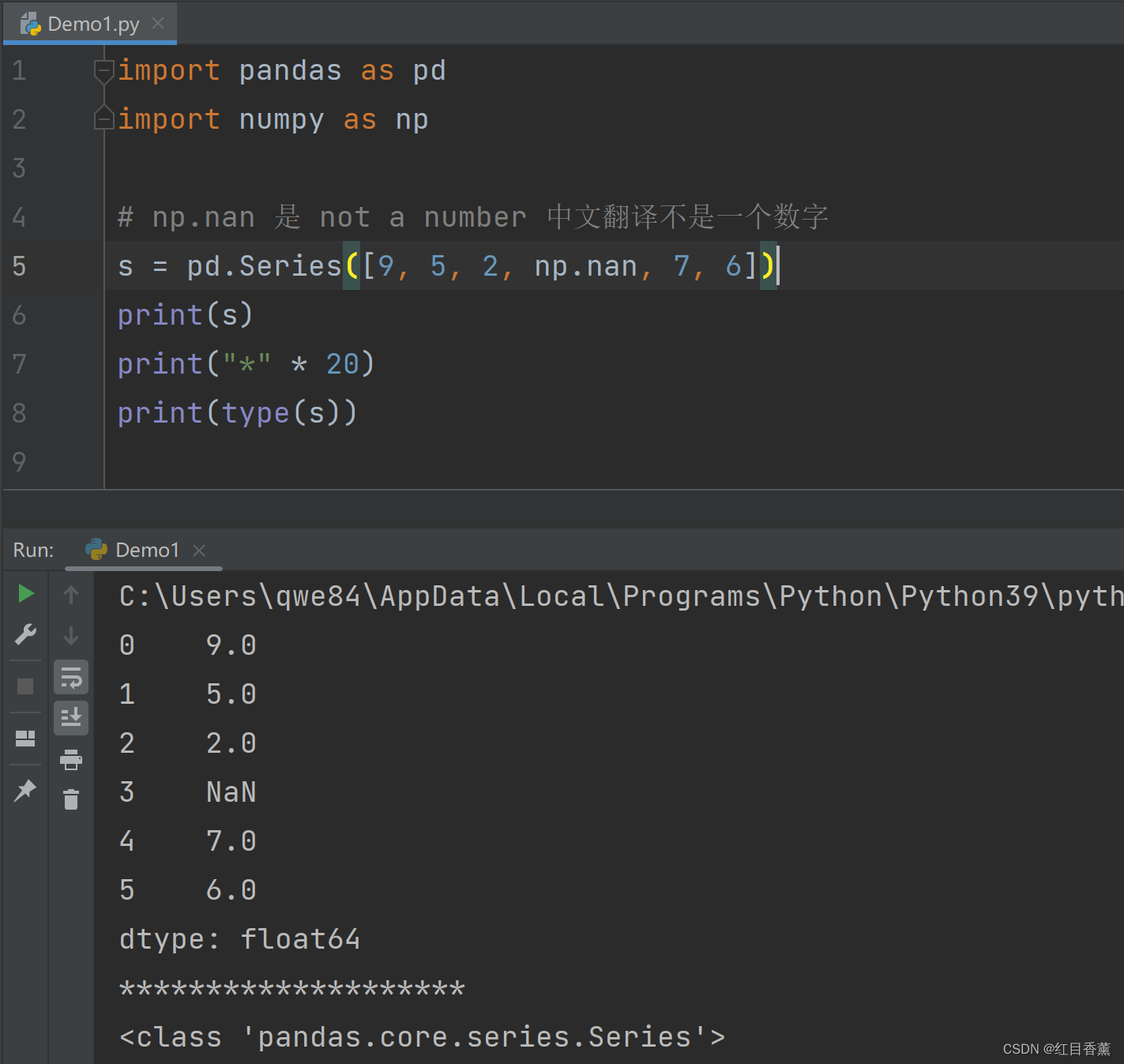
s = pd.Series([9, 5, 2, np.nan, 7, 6])
print(s.index)
可以看到生成结果是【range范围的0,6,也就是下标0~5,共计6个。】
![]()
生成对象·二维DateFrame
import pandas as pd
import numpy as np
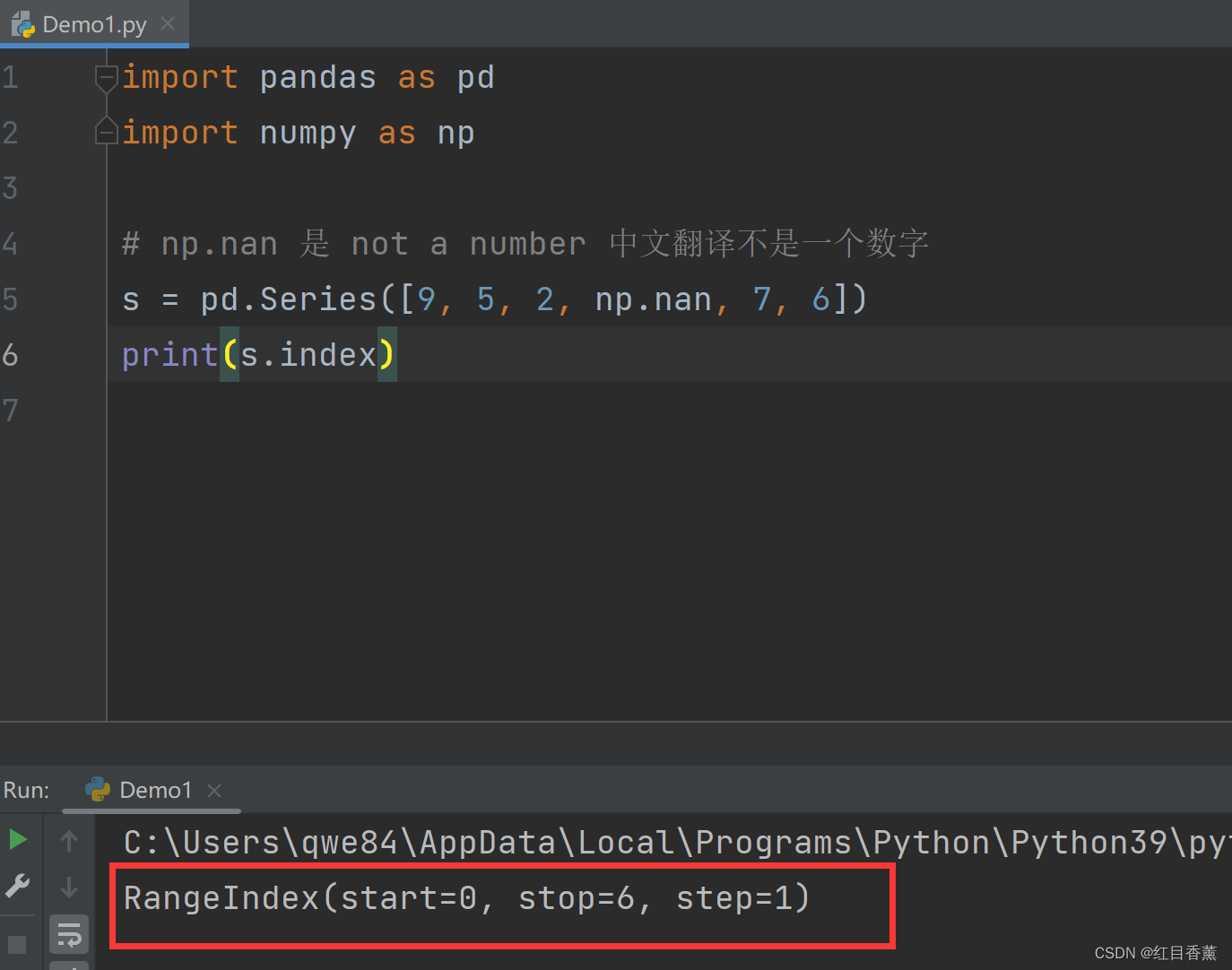
dates = pd.date_range('20230213', periods=6)
# 通过numpy生成一个6行4列的二维数组,行用index声明行标题,列用columns声明列标题
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=["1", "2", "3", "4"])
print(df)
二维效果:
![]()
生成对象·一维Series生成二维DateFrame
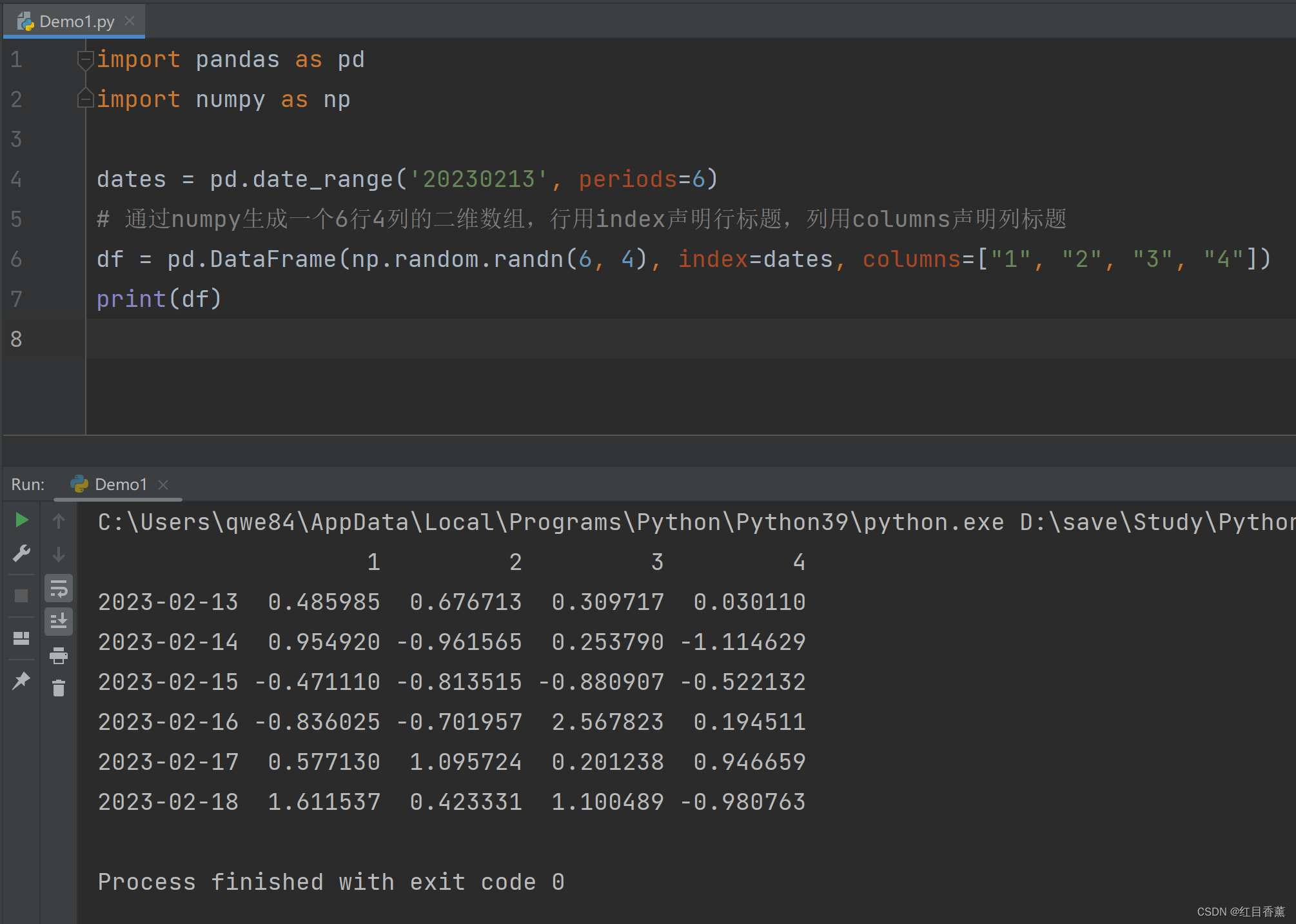
import pandas as pd
import numpy as np
df2 = pd.DataFrame({'A': np.random.randint(1, 5),
'B': pd.Timestamp('20230213'),
'C': pd.Series(np.random.randint(1, 5), index=list(range(4)), dtype='float32'),
'D': np.array([2] * 4, dtype='int32'),
'E': pd.Categorical(["admin", "zhangSan", "liSi", "wangWu"]),
'F': 'fell'})
print(df2)
生成效果:
![]()
这数据类型是可以自己来定义的,都是无所谓的。
查看索引
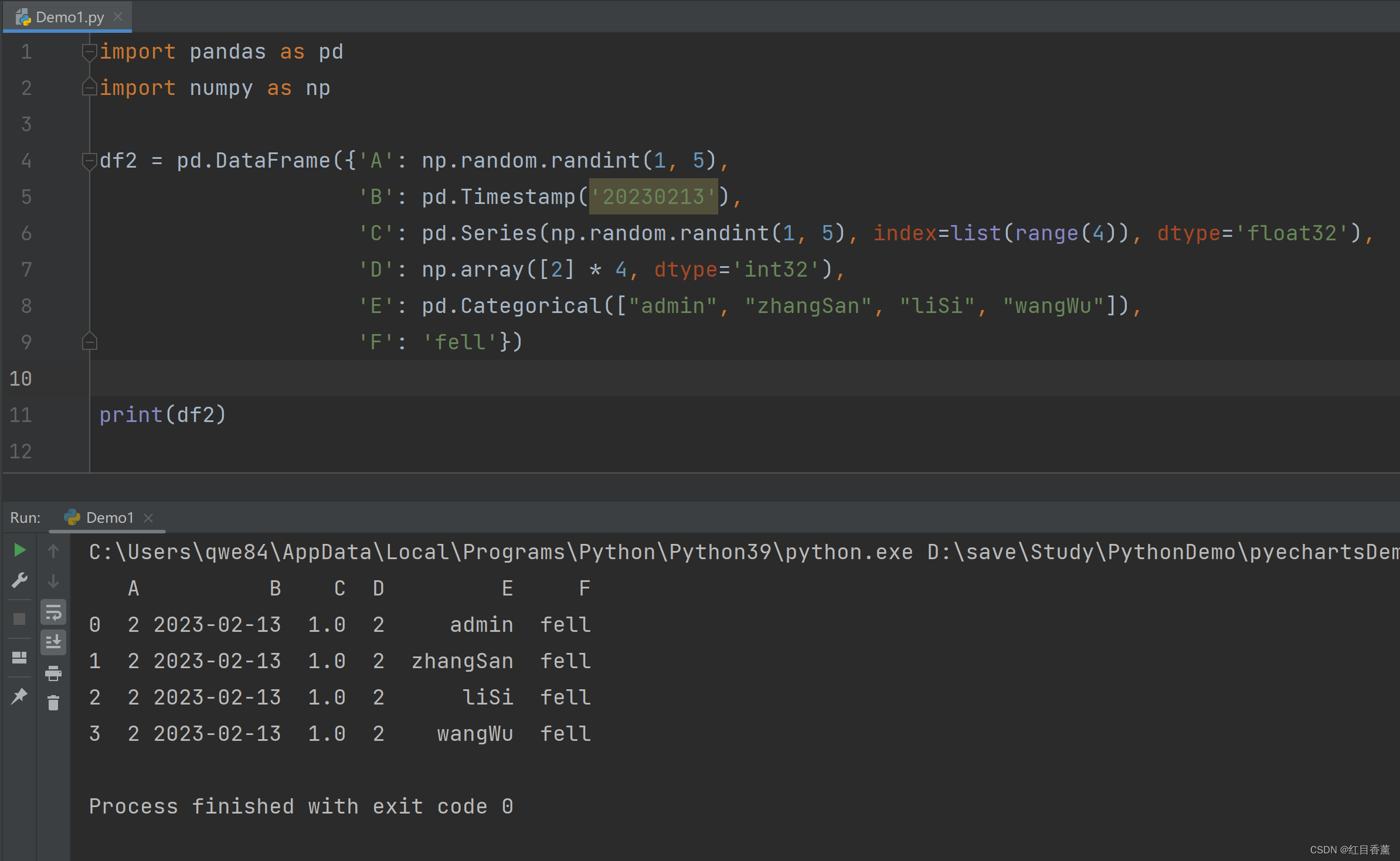
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df.index)

![]()
查看列名
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
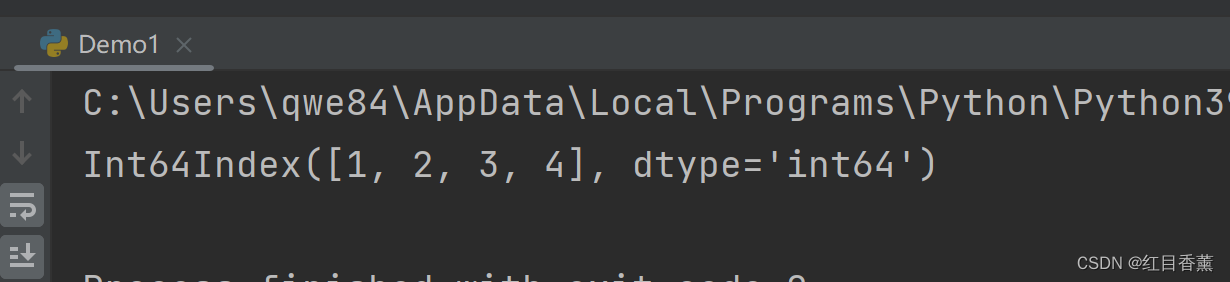
print(df.columns)
列名直接输出的数组
![]()
head查看 DataFrame 头部数据
head是头部,我们可以用这个函数来查看二维数组的头部行数
import pandas as pd
import numpy as np
df2 = pd.DataFrame({'A': np.random.randint(1, 5),
'B': pd.Timestamp('20230213'),
'C': pd.Series(np.random.randint(1, 5), index=list(range(4)), dtype='float32'),
'D': np.array([2] * 4, dtype='int32'),
'E': pd.Categorical(["admin", "zhangSan", "liSi", "wangWu"]),
'F': 'fell'})
print(df2.head(2))
我这里只查询了2行:

![]()
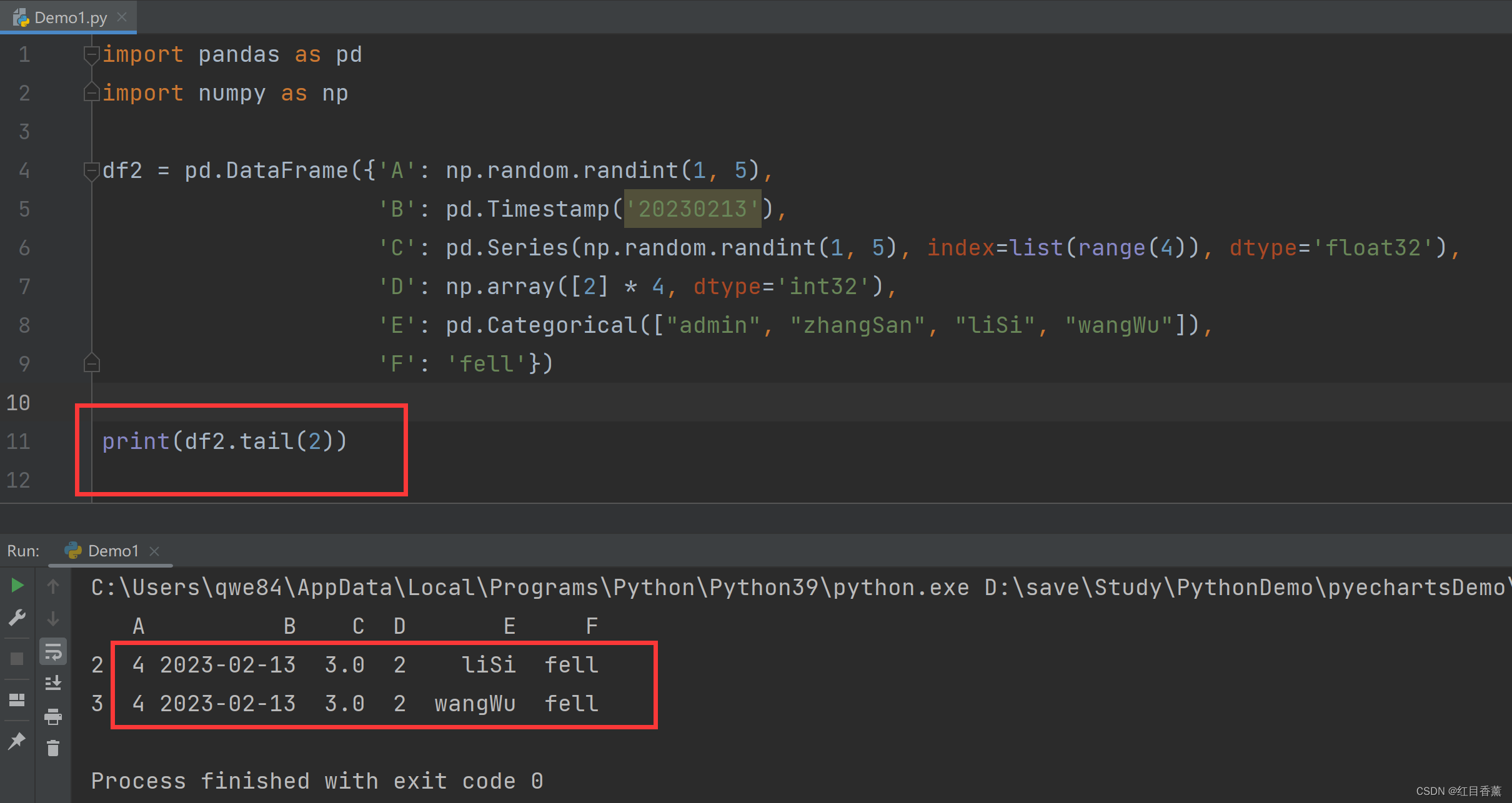
tail查看 DataFrame 尾部数据
print(df2.tail(2))一共4行,坐标2,3,就是后两行。
![]()
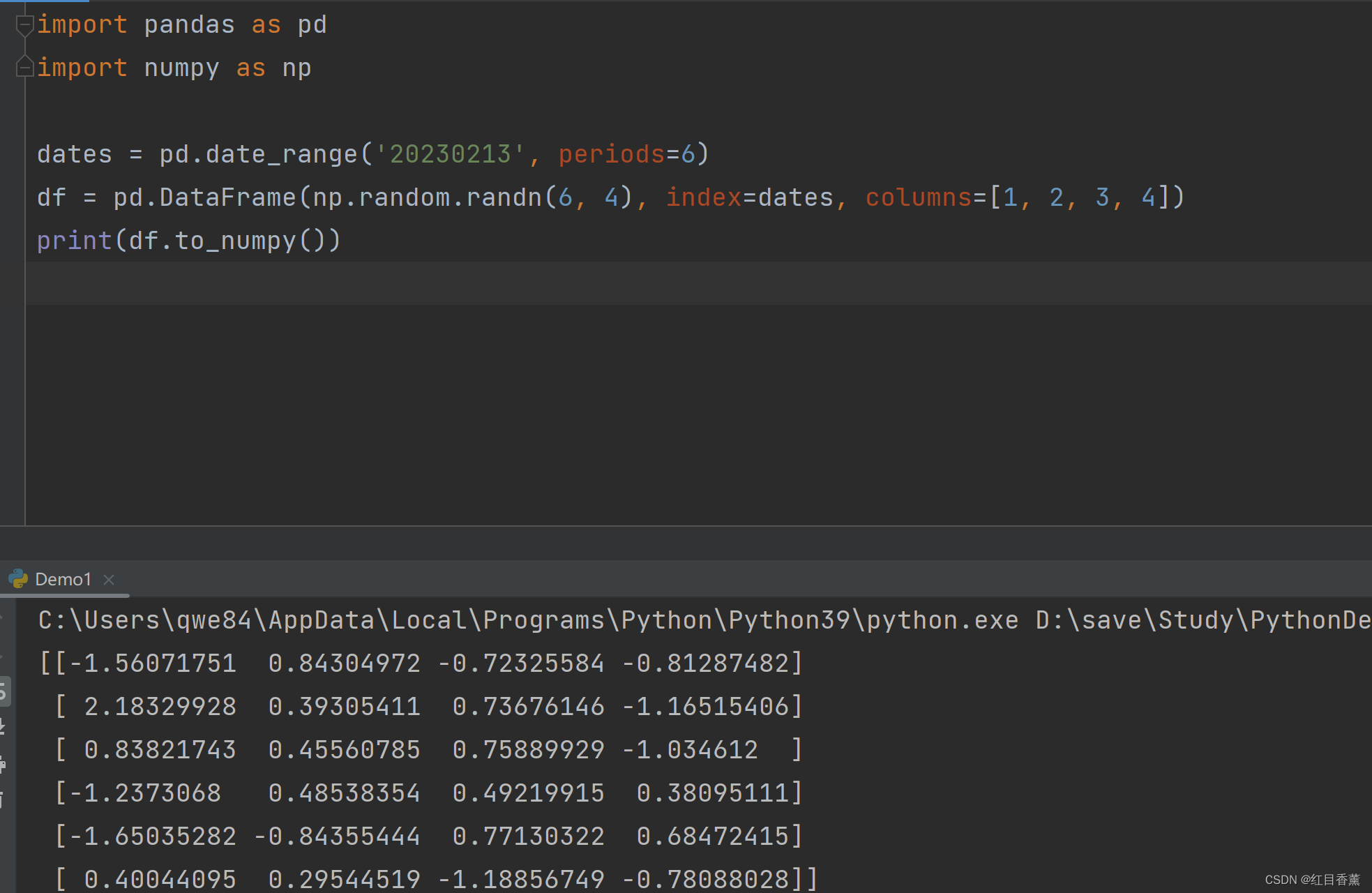
转Numpy数组
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df.to_numpy())
输出效果:
![]()
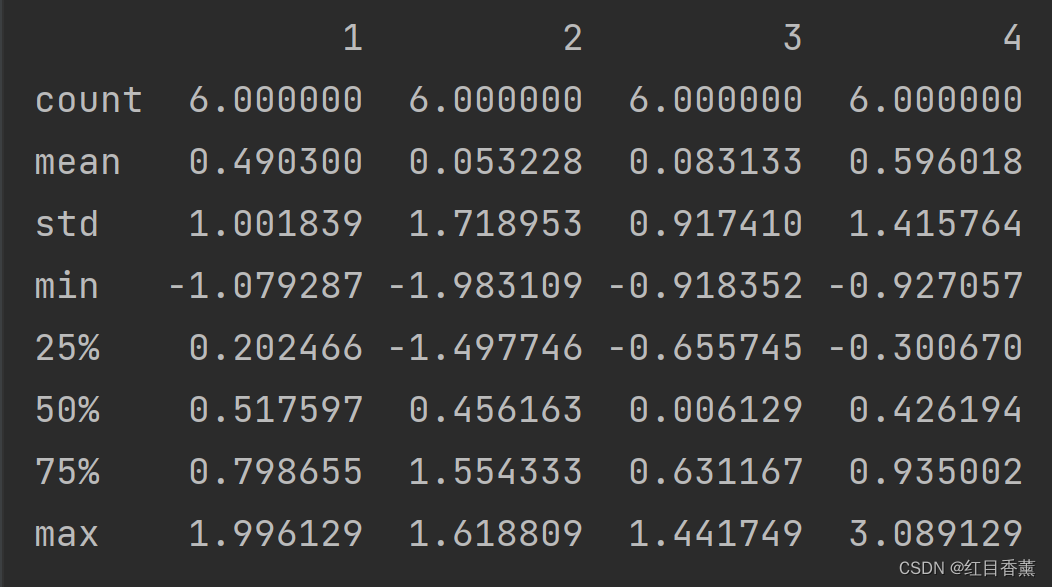
数据统计摘要describe函数
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 数据统计
print(df.describe())
统计效果:
count:非NaN数量
mean :算数平均值
std :标准差
min :数据中的最小值
max :数据中的最大值
![]()
横纵坐标转换位置
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 横纵坐标转换
print(df.T)
效果:很明显,横坐标变成了4,纵坐标变成了6
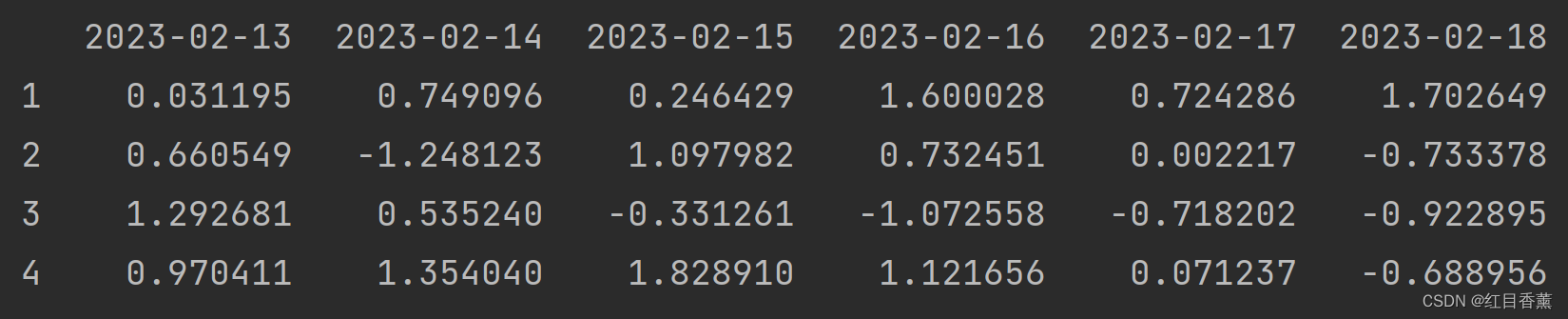
![]()
反向排列列数据
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 列反向
print(df.sort_index(axis=1, ascending=False))
效果:
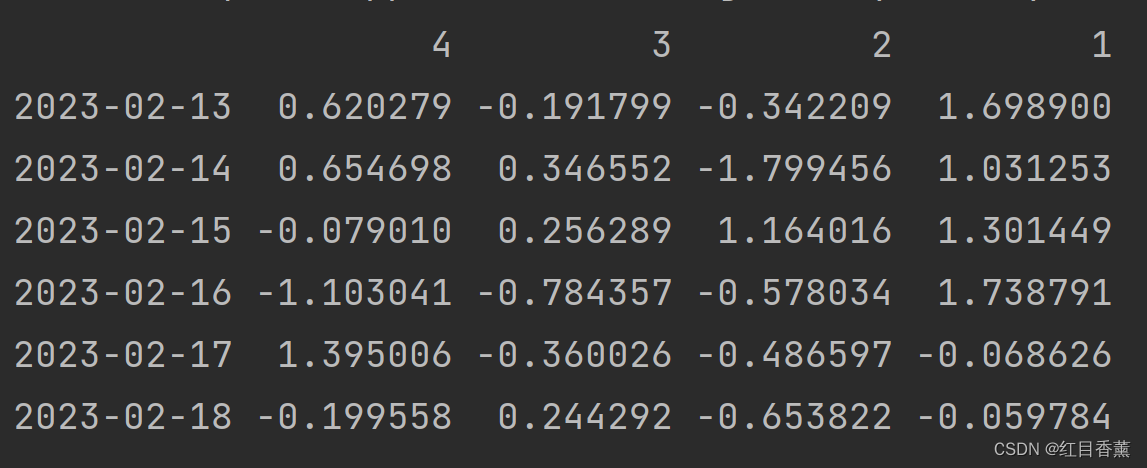
![]()
获取列数据
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 获取数据
print(df[3])
效果:
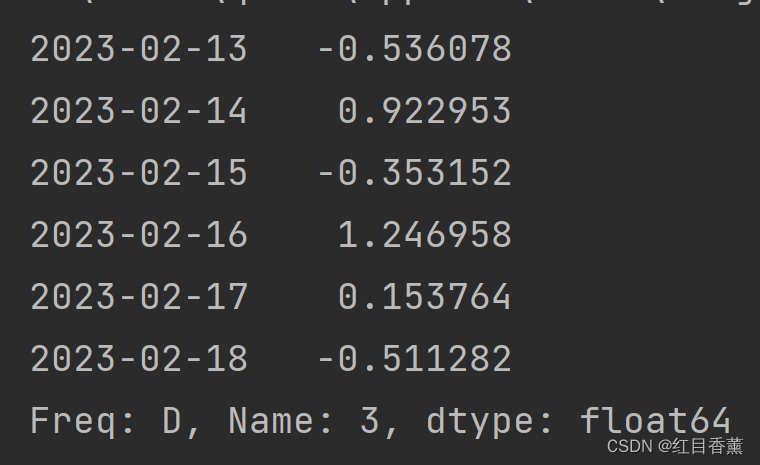
![]()
使用[]数组切片
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df)
print("-"*20)
# 用 [ ] 切片行:
print(df[2:3])
print("-"*20)
print(df['2023-02-15':'2023-02-18'])
切片效果:
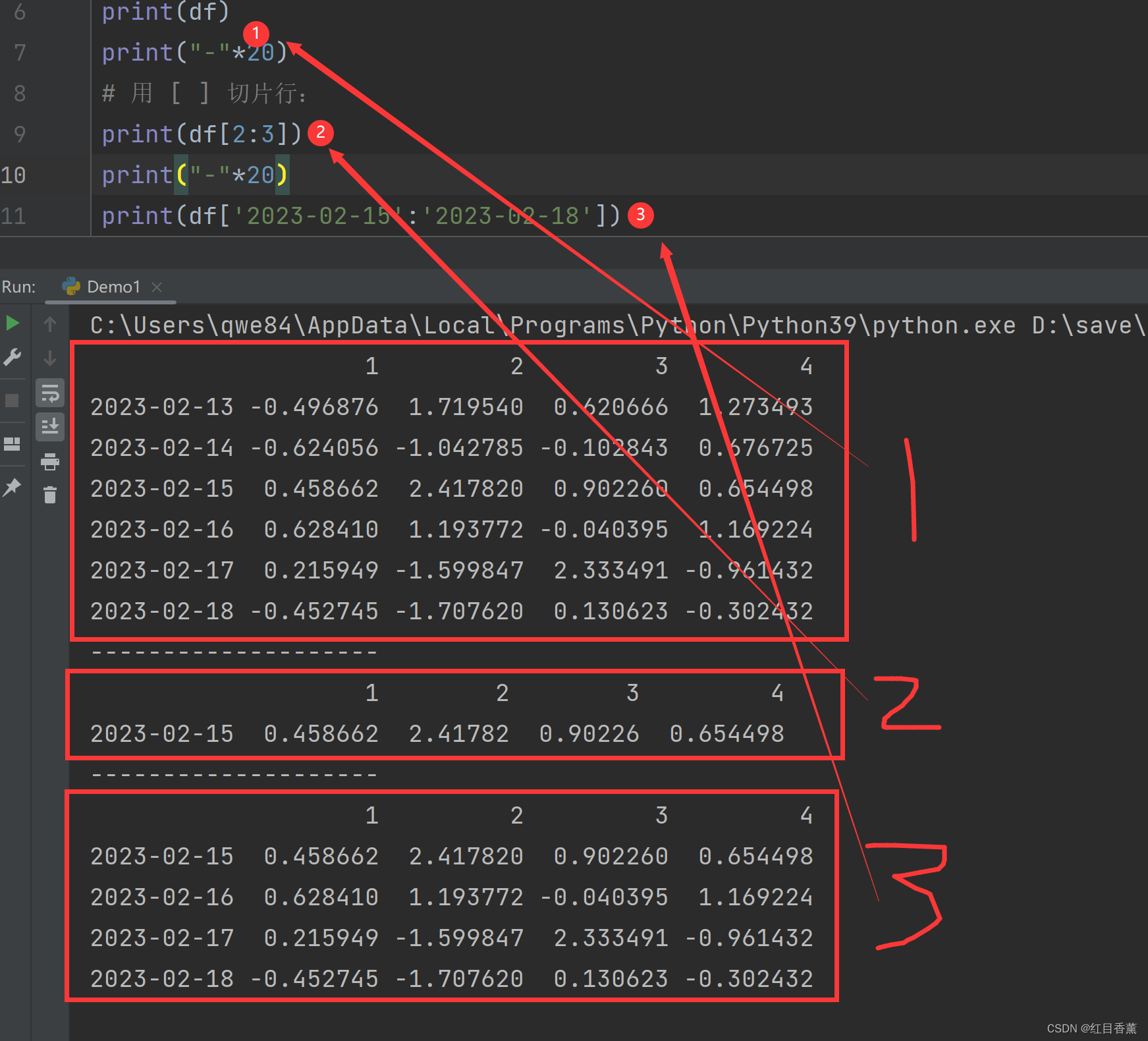
![]()
用标签提取一行数据
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 用标签提取一行数据
print(df.loc[dates[2]])
效果:
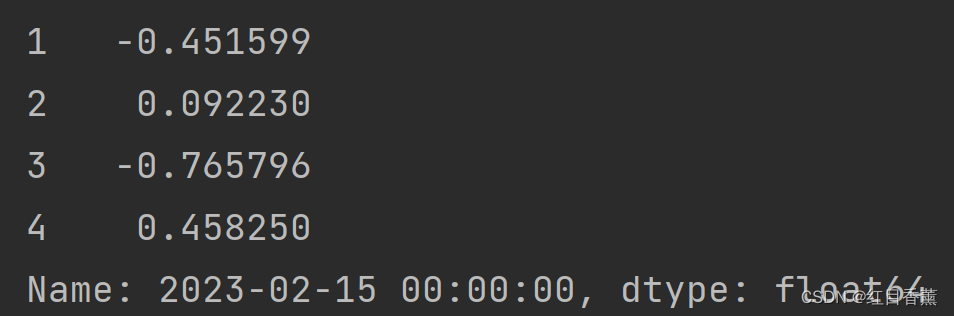
![]()
用标签选择多列数据
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 用标签提取多行数据
print(df.loc[:, [2, 4]])
效果:
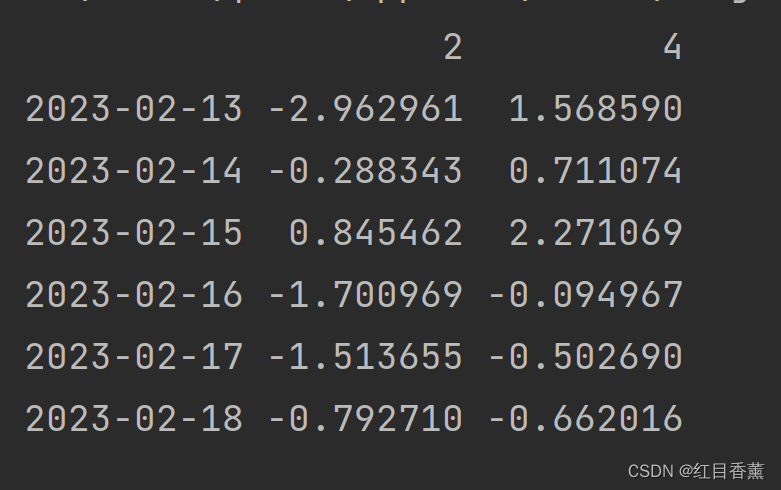
![]()
用标签切片,包含行与列结束点
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
# 行列切片
print(df.loc['2023-02-14':'2023-02-17', [1, 3]])
效果:
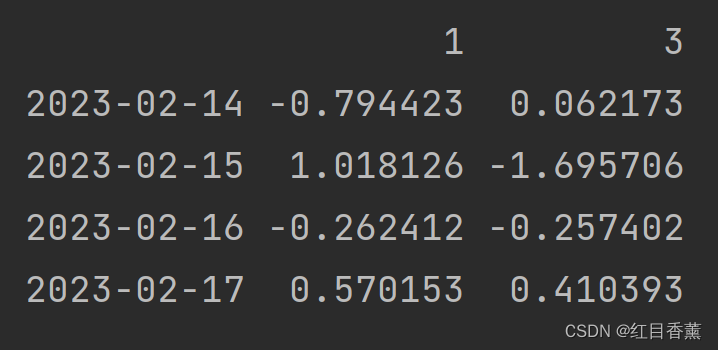
![]()
提取标量值
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df)
print("-"*20)
# 获取目标值·下标为2的行,第二列·相当于(2,2)
print(df.loc[dates[2], 2])
效果:
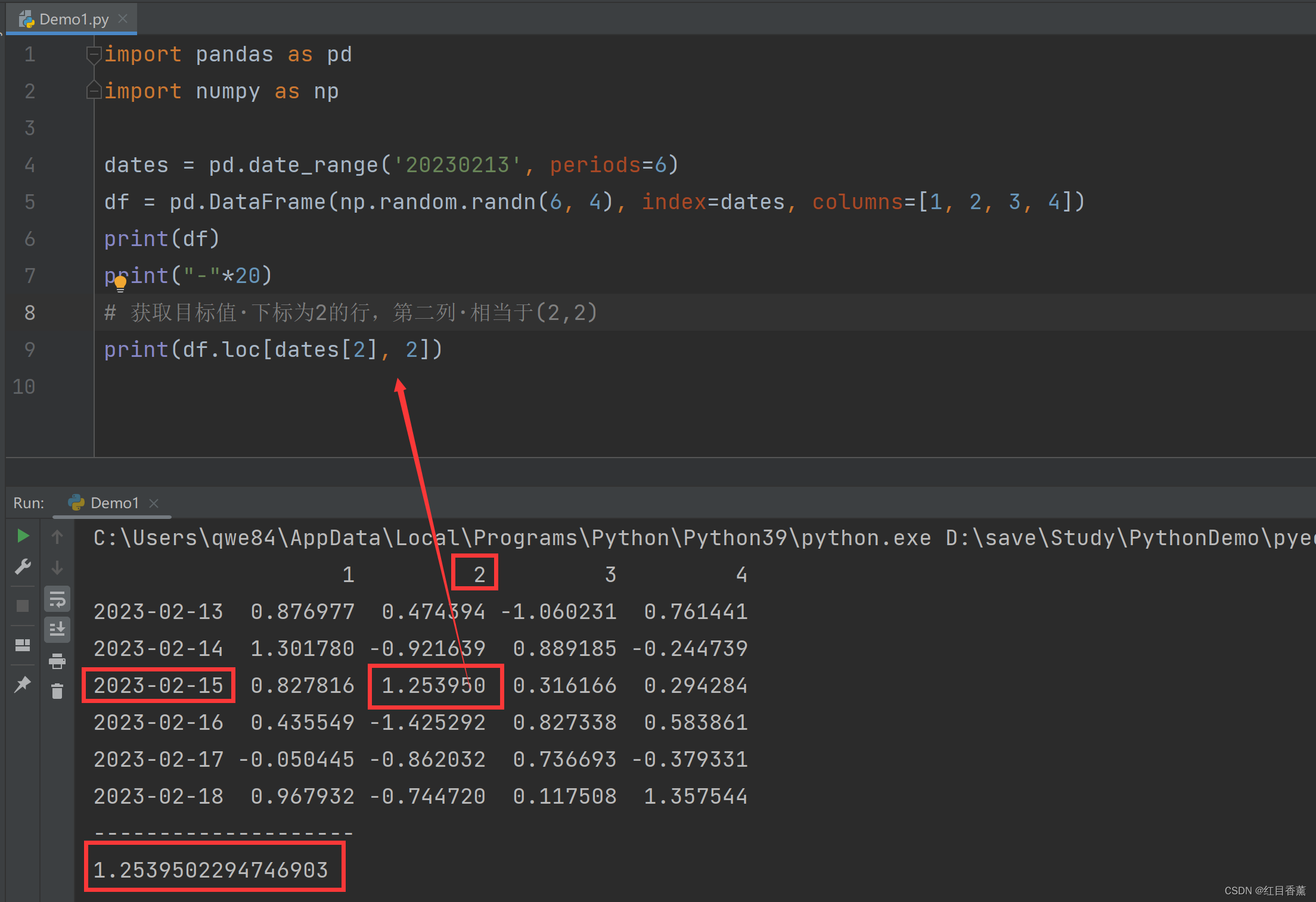
![]()
快速访问标量:效果同上
这里的不是列坐标值,而是列名
# 获取目标值·下标为2的行,第二列·相当于(2,2)
print(df.at[dates[2], 2])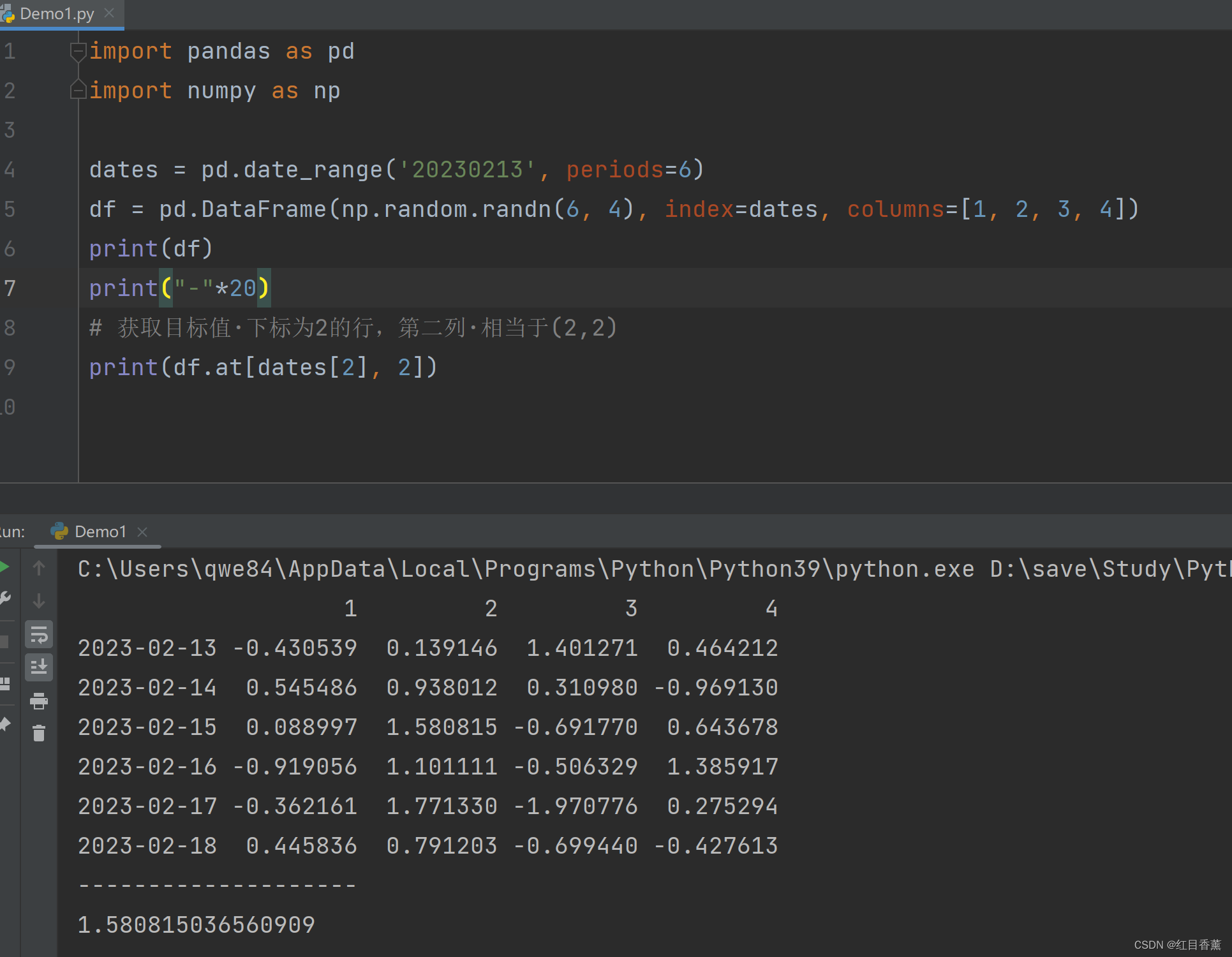
![]()
用整数位置选择:
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df)
print("-"*20)
# 横坐标3的行值
print(df.iloc[3])
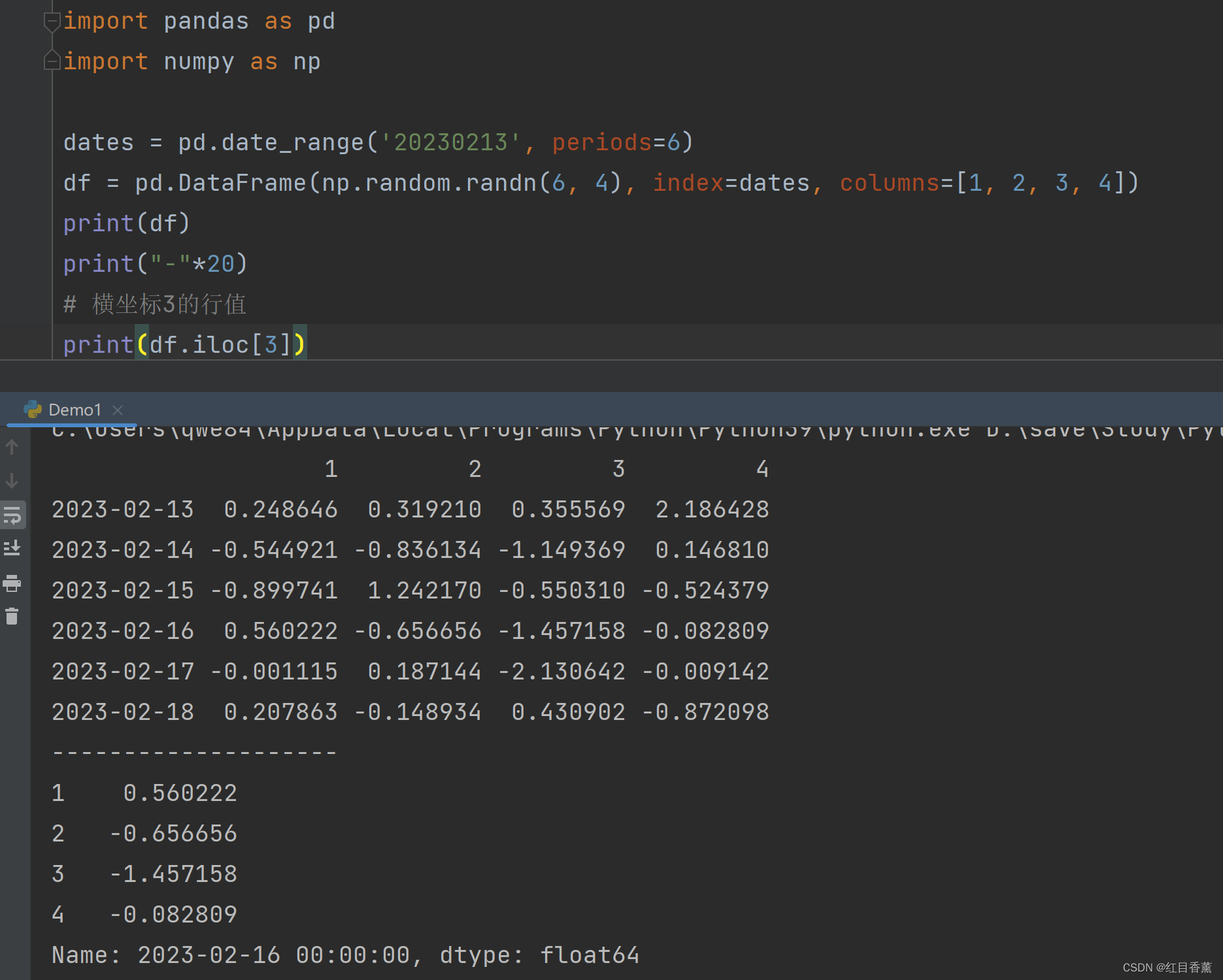
![]()
用整数切片:
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df)
print("-"*20)
# 切片
print(df.iloc[3:5, 0:2])
效果:
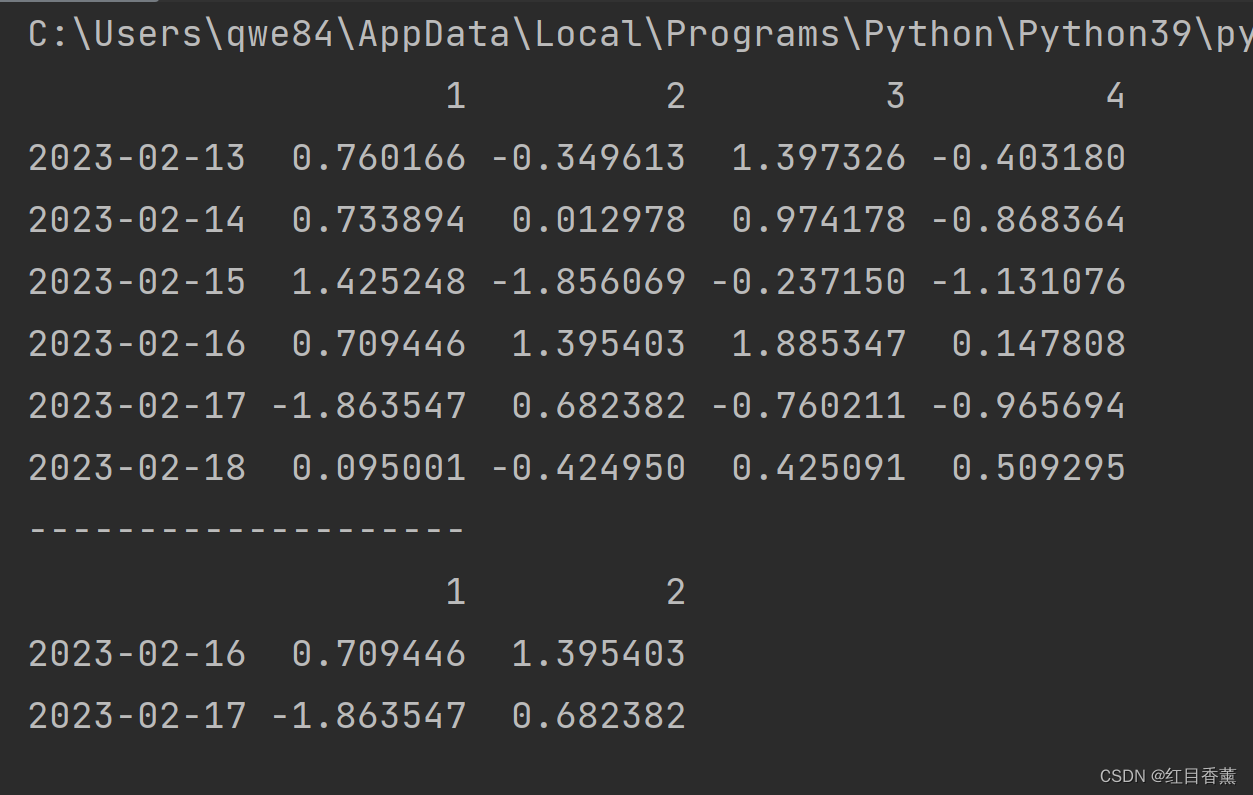
![]()
显式提取值(好用)
直接根据坐标进行处理就行,起始坐标点[0,0]
import pandas as pd
import numpy as np
dates = pd.date_range('20230213', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=[1, 2, 3, 4])
print(df)
print("-" * 20)
# 直接横纵坐标从0开始进行获取坐标值
print(df.iloc[2, 2])
效果:
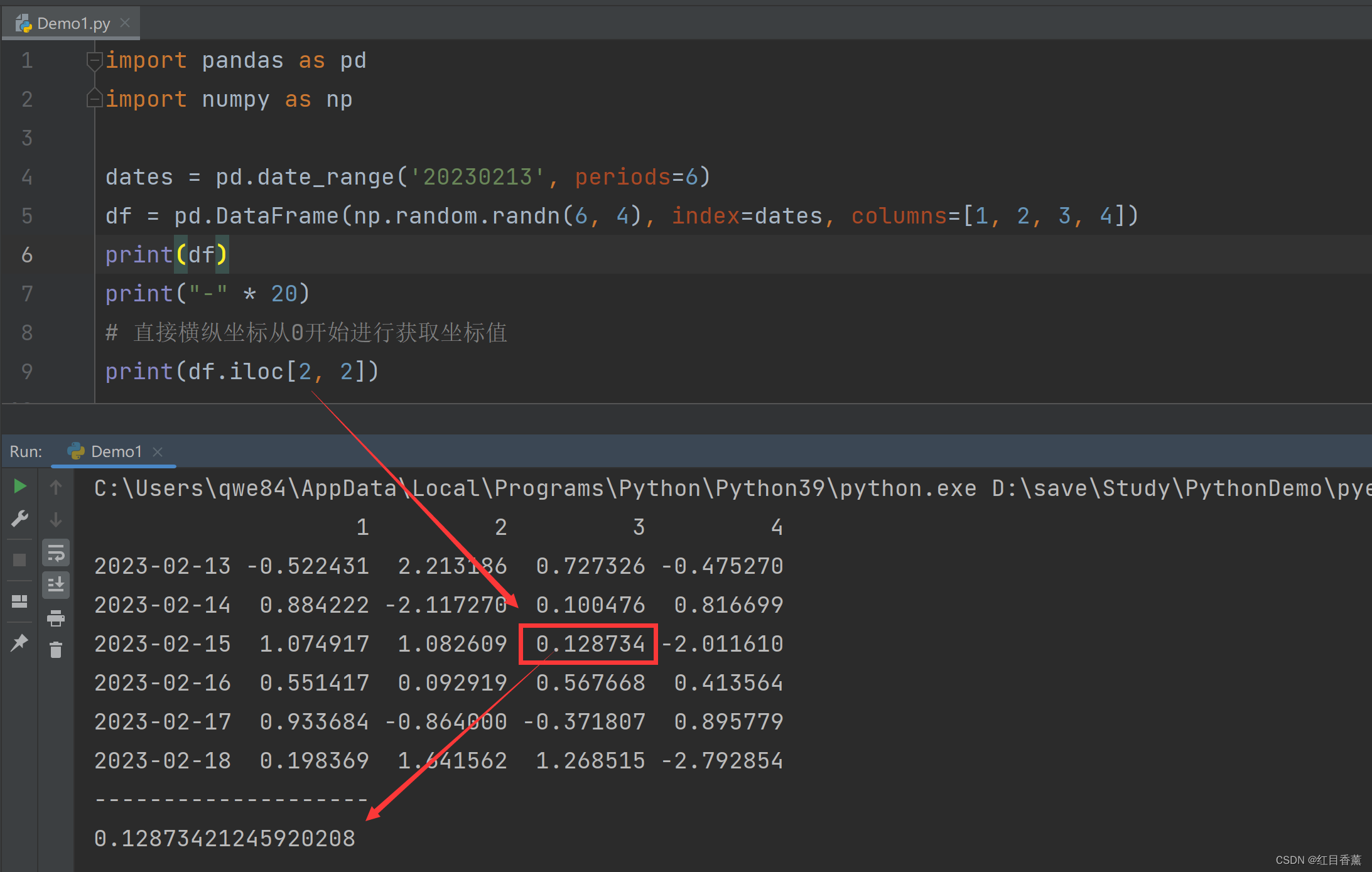
![]()
总结
到这里基本的使用就够用了,但是起始这是远远不够的,我们后面的文章才会真正的进行实际操作中用到的方法案例实操。
万事开头难,我们一点点的掌握即可。

- 点赞
- 收藏
- 关注作者
评论(0)