PaddleHub一键OCR中文识别(超轻量8.1M模型,火爆)——本地实现

【摘要】 参考资料:PaddleHub一键OCR中文识别(超轻量8.1M模型,火爆)关于本地执行的报错解决记录:报错1:无法下载模型,执行加载模型代码时报错,具体报错忘记截图了,造成此错误的主要原因是安装Paddlehub时的一个警告# 加载移动端预训练模型ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")# 服务端可以加载大模型,效果更好 # oc...
关于本地执行的报错解决记录:
报错1:无法下载模型,执行加载模型代码时报错,具体报错忘记截图了,造成此错误的主要原因是安装Paddlehub时的一个警告
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
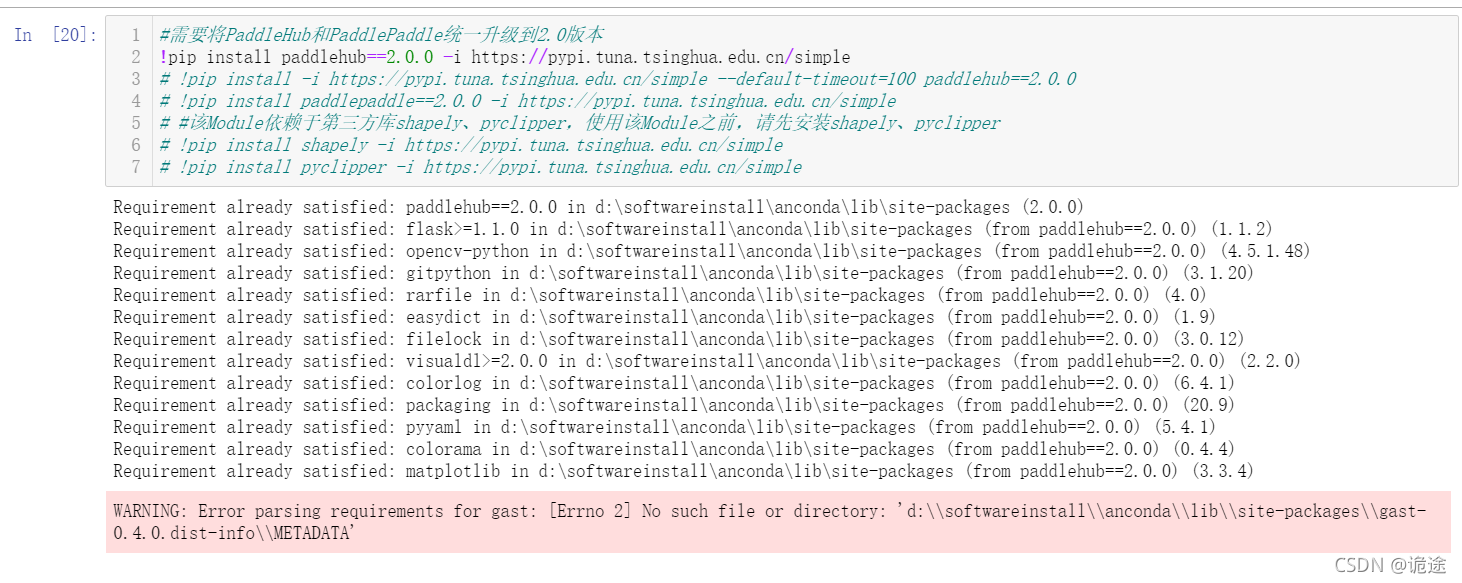
解决办法:这里没发现什么好的解决办法,创建虚拟环境,隔离的也不彻底,卸载anaconda重装,重装之前清除所有python&paddle相关文件夹,这里重复了十几次吧才解决,这里要注意下,paddlepaddle部分依赖包会和tensflow冲突
报错2:报错信息如下
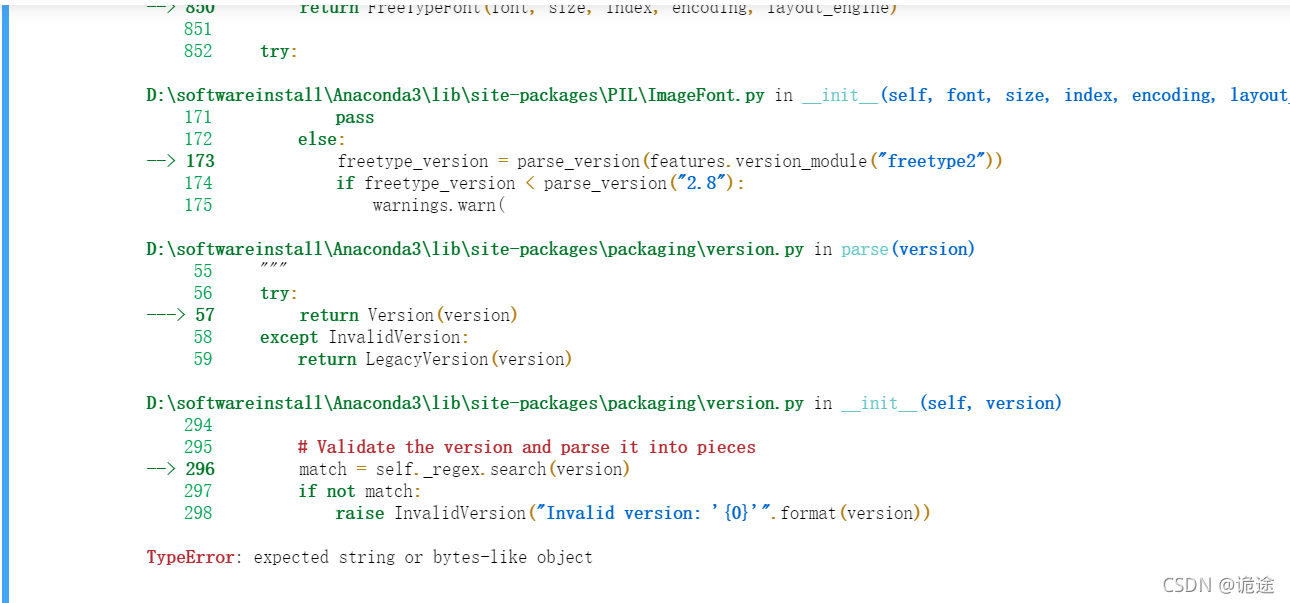
经过一系列排查,造成这一报错的主要原因是参数
visualization=True, # 是否将识别结果保存为图片文件;
这里主要时PIL依赖的问题,最后更新了pillow库解决,这里不解决不影响ocr的使用,只是没有识别后图片生成而已,去掉此参数,正常文本识别还是可以照常使用

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)