阿里大厂面试:2亿条数据需要缓存,如何设计这个存储方案?

【摘要】
对于2亿条数据需要缓存,使用单机肯定是不可能了,至少是分布式存储。
而分布式存储我们可以选择的选项有很多,今天我们单独来讨论下redis的解决方案。
使用redis如何落地。
在阿里p7工程案例和场...
对于2亿条数据需要缓存,使用单机肯定是不可能了,至少是分布式存储。
而分布式存储我们可以选择的选项有很多,今天我们单独来讨论下redis的解决方案。
使用redis如何落地。
在阿里p7工程案例和场景设计中,这一类的确是必问题,我们一般有三种解决方案:
第一种: 哈希取余算法
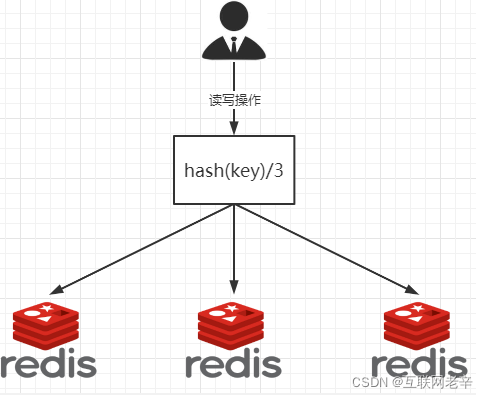
2亿条记录假设2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
比如0,就是最左的,1是中间的,2是最右边的。
这种方案是最常用的,也是最通用的
优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动&#
文章来源: zmedu.blog.csdn.net,作者:互联网老辛,版权归原作者所有,如需转载,请联系作者。
原文链接:zmedu.blog.csdn.net/article/details/123718461
【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)