Python可视化数据分析07、Pandas_CSV文件读写


![]()
Python可视化数据分析07、Pandas_CSV文件读写
📋前言📋
💝博客:【】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
💝Python初始环境地址:【】💝
环境需求
环境:win10
开发工具:PyCharm Community Edition 2021.2
数据库:MySQL5.6
目录
Python可视化数据分析07、Pandas_CSV文件读写
CSV文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV文件操作
在Pandas模块中,使用to_csv()函数将DataFrame对象写入到CSV文件。
to_csv()函数的参数说明如下:
path_or_buf:字符串或文件句柄,默认无文件路径或对象,如果没有提供,结果将返回为字符串。可以是URL,可用URL类型包括http、ftp、s3和文件。
sep:指定分隔符。如果不指定参数,则会尝试使用逗号分隔。
CSV写入
import pandas as pd
df = pd.DataFrame({"id": [1, 2, 3], "name": ["雷静", "小凤", "春梦"], "age": ["21", "22", "20"]})
print(df)
# 写入到csv文件
df.to_csv("test.csv", index=False, sep=",", encoding="gbk") # 使用gbk在用excel的时候能显示中文

import pandas as pd
df = pd.DataFrame({"id": [1, 2, 3], "name": ["雷静", "小凤", "春梦"], "age": ["21", "22", "20"]})
print(df)
# 写入到csv文件
df.to_csv("test.csv", index=False, sep=",", encoding="utf-8") # 使用gbk在用excel的时候能显示中文

![]()
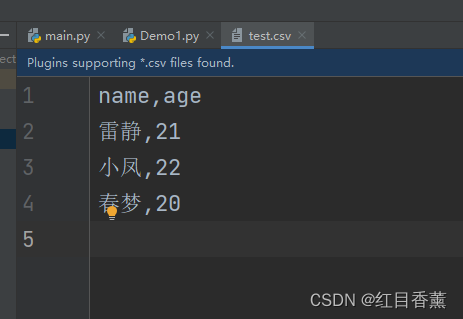
![]()
CSV读取
import pandas as pd
df = pd.read_csv("test.csv", encoding="utf-8")
print(df)
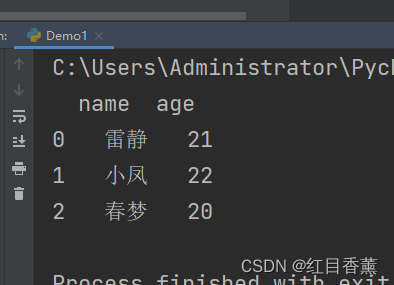
![]()
import pandas as pd
df = pd.read_csv("test.csv", encoding="gbk")
# 基础信息
print(df.info)
# 查看列名
print(df.columns)
# 查看各列数据类型
print(df.dtypes)
# 查看下标
print(df.index)
# 数据浏览前2条
print(df.head(2))
# 查看name到age列
print(df.loc[:, "name":"age"])
# 基本统计
print("最大年龄:", df.age.max())
print("平均年龄:", df.age.mean())
# 查询
print(df[df.name == "春梦"])
# 排序·True正序False倒序
print(df.sort_values(by=["age"], ascending=False))
# 在第二列【下标是1】添加列
df.insert(1, "sex", "女")
print(df)
# 在最后添加列
df["introduce"] = "巾帼"
print(df)
# 删除某行
df = df.drop(1)
print(df)
# 替换
value = pd.Series([1, "女", "雷静静", 20, "大眼姑娘"], index=["id", "sex", "name", "age", "introduce"])
df.loc[0] = value
value = pd.Series([4, "女", "小龙女", 18, "冰山美人"], index=["id", "sex", "name", "age", "introduce"])
df.loc[3] = value
print(df)
# 条数
print(len(df))
<bound method DataFrame.info of id name age
0 1 雷静 21
1 2 小凤 22
2 3 春梦 20>
Index(['id', 'name', 'age'], dtype='object')
id int64
name object
age int64
dtype: object
RangeIndex(start=0, stop=3, step=1)
id name age
0 1 雷静 21
1 2 小凤 22
name age
0 雷静 21
1 小凤 22
2 春梦 20
最大年龄: 22
平均年龄: 21.0
id name age
2 3 春梦 20
id name age
1 2 小凤 22
0 1 雷静 21
2 3 春梦 20
id sex name age
0 1 女 雷静 21
1 2 女 小凤 22
2 3 女 春梦 20
id sex name age introduce
0 1 女 雷静 21 巾帼
1 2 女 小凤 22 巾帼
2 3 女 春梦 20 巾帼
id sex name age introduce
0 1 女 雷静 21 巾帼
2 3 女 春梦 20 巾帼
id sex name age introduce
0 1 女 雷静静 20 大眼姑娘
2 3 女 春梦 20 巾帼
3 4 女 小龙女 18 冰山美人
3Process finished with exit code 0
- 点赞
- 收藏
- 关注作者
评论(0)