Java--☀️面试官:LinkedList真的比ArrayList添加元素快?❤️本文通过Open JDK JMH带你揭开真

欢迎进来学习的小伙伴,本文将会带你揭开真相~
【学习背景】
不管你是学生,还是职场小白,还是入行Java几年的小伙伴,相信很多小伙伴在面试Java工作岗位时,发现
LinkedList和ArrayList这两者相关的问题基本是必面的~
但是当面试官问到LinkedList和ArrayList的区别时,可能很多准备得不够充分的小伙伴第一反应给出的回答仅仅是这样的:
- LinkedList底层数据结构是链表,添加和删除元素效率比ArrayList高~
- ArrayList底层数据结构是数组,查询效率比LinkedList高~
有点毛病,而且仅仅是这样回答,面试官可能不会怼你,但是肯定是不满意的哇,也可能会继续问:
面试官:哦,还有吗?
应聘者:没了~
面试官:大意了啊,你说的效率高是有通过JMH验证尾插法添加元素的效率吗?
应聘者:尾插法???
面试官:嗯,从数据结构的尾部添加数据,不过这里先不试了,回去再自己学习验证下结论吧~
应聘者:哦…[脸红emoj]…

回本正题,那么本文最主要目的就是通过JMH工具验证==LinkedList添加元素真的比ArrayList快吗?==
可能有些小伙伴会问JMH是啥?直接使用 for循环+时间戳System.currentTimeMillis() 盘它看看效率不行吗? 我想说的是你的==想法针不戳,但针滴不行啊,你可以百度看看为啥==,进入正文吧,JMH属于Oracle官方Open JDK提供的一款性能测试工具,文中会进行介绍~
当然除了这个问题,本文也会将ArrayList和LinkedList进行分析和面试总结,加深对这两者的认识,也希望能帮助到有需要的小伙伴~
@TOC
进入正文~
一、ArrayList和LinkedList
1.1 ArrayList
1.1.1 ArrayList特性
- ⭐ 继承
AbstractList抽象类,==实现List接口==,还实现了RandomAccess==快速随机访问==以及Cloneable, java.io.Serializable克隆和序列化- ⭐ 底层数据结构是==数组==,连续内存空间,使用==for循环遍历效率最高==,尾部添加和删除元素时效率也很高,==非线程安全==
- ⭐ 数组容量==动态自增==,当容量大于当前数组容量时进行扩容,==容量大小增加50%==,每次扩容都会开辟新空间,并且进行==新老数组的复制重排==
- ⭐ 【JDK1.7之前版本】扩容后容量大小比【JDK1.7及之后版本】多1个容量
JDK1.7之前版本扩容关键源码
int newCapacity = (oldCapacity * 3)/2 + 1 )
JDK1.7及之后版本扩容关键源码(PS:>>右移相当于除2的n次方,<<左移相当于乘2的n次方)
int newCapacity = oldCapacity + (oldCapacity >> 1)
1.1.2 ArrayList常用API
- ⭐增:效率
add(E e)>add(int index,E element)- ⭐删:效率
remove(int index)>remove(E e)- ⭐改:
set(int index,E element)- ⭐查:
get(int index)
1.1.3 ArrayList常见面试题(附参考答案)
(1)==ArrayList实现了RandomAccess接口,但是实际接口中什么都没做,它有什么作用吗?==
RandomAccess是Java中的一个标志接口,只要实现该接口,就拥有快速随机访问的特性。
(2)==ArrayList几个重要属性各自的含义?==
ArrayList底层主要属性有elementData对象数组、size集合大小(数组中已存储的元素个数,非数组容量大小)、DEFAULT_CAPACITY默认容量为10(new实例化时数组初始化容量大小为0,执行add添加元素时才指定初始化容量为DEFAULT_CAPACITY)~
(3)==ArrayList 属性elementData数组使用了transient修饰,作用是什么?==
- 使用
transient关键词修饰属性,表示不能被外部方法序列化ArrayList的elementData数组是动态扩容的,并非所有被分配的内存空间都存储了数据,如果采用外部序列化法实现序列化,那整个elementData都会被序列化ArrayList为了避免这些没有存储数据的内存空间被序列化,内部提供了两个私有方法writeObject以及readObject来自我完成序列化与反序列化,从而在序列化与反序列化数组时节省了空间和时间。
(4)==⭐ArrayList如何添加元素效率最高?==
ArrayList新增元素的方法常用的有两种,一种是==直接添加元素==,另外一种是==添加元素到指定位置==- 使用ArrayList的
add(E e)方法直接添加元素,默认将元素添加到数组尾部,在没有发生扩容的情况下,不会有数组的复制重排过程,效率最高- 使用
add(int index,E element)添加元素到指定位置,index等于0,表示在头部添加元素,会导致在该位置后的所有元素都需要进行复制排列,时间复杂度O(n)-线性复杂度,效率很低- 因此
ArrayList在初始化时指定合适的数组容量大小,直接添加元素到数组尾部,那么ArrayList添加元素的效率反而比LinkedList高
(5)==⭐ArrayList使用哪种方式遍历查找效率最高?==
ArrayList使用for循环遍历查找效率最高,因为ArrayList底层数据结构为数组,数组是一块连续内存的空间,并且ArrayList实现了RandomAccess接口标志,意味着ArrayList拥有快速随机访问特性,对于元素的查找,时间复杂度为O(1)-常数复杂度,效率最高。
(6)==⭐ArrayList在foreach循环或迭代器遍历中,调用自身的remove(E e)方法删除元素,会导致什么问题?==
- 会抛
ConcurrentModificationException异常,原因是==集合修改次数==modCount和==迭代器期望修改次数==expectedModCount不一致foreach循环相当于迭代器,在迭代器遍历中,使用ArrayList自身的remove(E e)方法删除元素,内部会进行modCount++,但并不会进行迭代器的expectedModCount++,因此导致进入下一趟遍历调用迭代器的next()方法中,内部比对两者不一致抛出ConcurrentModificationException异常- ==目前开发规范都是禁止在迭代器中使用集合自身的
remove/add方法==,如果要在循环中删除元素,应该使用迭代器的remove删除,也可以使用for循环进行remove删除元素,不过需要角标减1(i--)
(7)==⭐ArrayList初始化容量大小足够的情况下,相比于LinkedList在头部、中间、尾部添加的效率如何?==
- 头部:
ArrayList底层结构是==数组==,数组是一块连续的内存空间,添加元素到数组头部时,需要对头部以后的==所有数据进行复制重排,效率最低,时间复杂度为O(n)==LinkedList底层结构是==链表==,通过addFirst(E e)方法添加元素到头部时,效率也最高,时间复杂度为O(1)-常数复杂度,不过多了新节点创建和指针变换的过程LinkedList也可以通过add(index, E element)方法,指定index等于0时,也表示添加元素到头部时,不过此过程会先通过==二分法查找==找到指定位置的节点元素,而头部刚好处于前半部分的第一个,找到该节点就返回,再进行后续新节点创建和指针变换,不过这种方式添加元素的==综合时间复杂度为O(logN)-对数复杂度==- 中间:
ArrayList添加元素到数组中间,==往后的所有数据需要都进行复制重排,时间复杂度为O(n)==;LinkedList添加元素到中间,==二分法查找发挥的作用最低==,不论从前往后,还是从后往前,链表被循环遍历的次数都是最多的,效率最低,综合==时间复杂度为O(n)==- 结尾:
ArrayList添加元素尾部,不需要进行复制重排数组数据,==效率最高==,时间复杂度为O(1)LinkedList添加元素到尾部,==不需要查找元素,效率也是最高的==,但是==多了==新节点对象创建以及==变换指针指向对象的过程==,==效率比ArrayList低一些==,时间复杂度为O(1)
(8)==⭐ArrayList为什么是非线程安全的?==
- 因为
ArrayList添加元素时,主要会进行这两步操作,一是==判断数组容量是否满足大小==,二是==在数组对应位置赋值==,这2步操作在多线程访问时都存在安全隐患~- 第1个隐患是,判断数组容量是否满足大小的
ensureCapacityInternal(size+1)方法中,可能多个线程会读取到相同的size值,如果第1个线程传入size+1进行判断容量时,刚好满足容量大小,就不会进行扩容,同理,其他线程也不会进行扩容,这样就会导致进行下一步其他线程在数组对应位置赋值时,抛出数组下标越界ArrayIndexOutOfBoundsException异常- 第2个隐患是,在数组对应位置赋值
elementData [size++] = e; 实际上会被分解成两步进行,先赋值elementData [size] = e;再进行size=size+1;可能第1个线程刚赋值完,还没进行size+1,其他线程又对同一位置进行赋值,导致前面线程添加的元素值被覆盖。
1.2 LinkedList
1.2.1 LinkedList特性
- ⭐继承
AbstractSequentialList抽象类,实现了List接口,还实现了Deque双向队列以及克隆Cloneable和序列化java.io.Serializable- ⭐底层数据结构是双向链表,在头部和尾部添加、删除元素效率比较高,非线程安全
- ⭐JDK1.7后
Entry<E> header属性被替换为Node<E> first和Node<E> last首尾节点属性
替换3点优势:
first/last属性能更清晰地表达链表的链头和链尾概念first/last方式可以在初始化LinkedList的时候节省new一个Entryfirst/last方式最重要的性能优化是链头和链尾的插入删除操作更加快捷了。
1.2.2 LinkedList常用API
- ⭐增:效率
add(E e) =addLast(E e) =addFirst(E e) >add(int index,E element)- ⭐删:效率
removeFirst() =removeLast()>remove(int index) >remove(Object o)- ⭐改:
set(int index,E element)- ⭐查:
get(int index)
1.2.3 LinkedList常见面试题(附参考答案)
(1)==LinkedList为什么不能实现RandomAccess接口?==
- 因为
LinkedList底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现RandomAccess接口
(2)==LinkedList几个重要属性各自的含义?==
LinkedList底层主要属性有size集合大小(链表长度)、first链表头部节点、last链表尾部节点,并且也都使用transient修饰,表示不能外部序列化与反序列化,内部自己实现了序列化与反序列化。
(3)==LinkedList默认添加元素是怎么实现的?==
LinkedList添加元素的方法主要有==直接添加==和==指定位置添加==- 直接添加元素有
add(E e)方法和addAll(Collection c)方法,指定位置添加元素有addFirst(E e)、addLast(E e)、add(int index,E element)、addAll(int index,Collection c)方法- ==直接添加==元素默认添加到链表的尾部,不需要先查找节点,直接通过尾部节点,创建新节点和变换指针指向新节点
- ==指定位置==添加元素,如果是添加元素到链表头部或尾部,都不需要先查找节点,直接通过头部或尾部节点,创建新节点和变换指针指向新节点,但是如果是
add(int index,E element)添加元素到非首尾位置,会先使用二分查找到该位置对应的节点,再通过该节点,创建新节点和变换指针指向新节点
(4)==LinkedList使用哪种方式遍历效率最高?==
LinkedList底层数据结构是双向链表的,使用foreach循环或iterator迭代器遍历效率最高,通过迭代器的hasNext()、next()快速遍历元素- 需要注意的是尽量避免使用
for循环遍历LinkedList,因为每一次循环,都会使用二分查找先找到指定位置的节点,再通过该节点新建节点以及变换指针,效率极其低下。
(5)==LinkedList使用Iterator迭代器遍历时,进行remove(E e)操作,迭代器的指针会发生什么变化?==
LinkedList使用迭代器遍历,内部自己实现的是ListIterator接口,主要有lastReturned最后返回节点、next下一节点、nextIndex下一指针以及expectedModCount期望修改次数4个重要属性,其中nextIndex下一指针从0开始LinkedList迭代器遍历时,每进行一趟遍历,都会经过hasNext()、next()操作,并且在next()方法中,进行了nextIndex++操作- 当进行到某一趟遍历,调用
remove()进行操作元素,会通过lastReturned进行解链,并且将next = lastReturned和nextIndex--操作,也就是迭代器的下一指针会减一
(6)==LinkedList默认位置添加元素和指定位置添加元素分别怎么实现,哪种性能更高?==
LinkedList默认位置添加元素通过add(E e)方法实现,默认位置是添加元素到尾部,时间复杂度是O(1)-常数复杂度,效率最高。LinkedList指定位置添加元素通过addLast(E e)、addFirst(E e)方法添加元素到尾部和头部,add(E e)方法默认位置是添加元素到尾部,时间复杂度是O(1)-常数复杂度,效率最高。LinkedList还有一种指定位置添加元素通过add(int index, E element)方法实现,这种方式添加元素前,需要先通过二分查找找到指定位置的元素,再通过该元素进行==新节点创建以及指针变换==,综合时间复杂度是O(logN),如果添加元素的位置刚好在中间,二分查找发挥的作用最小,效率比较低~
(7)==List集合迭代器遍历使用Iterator和ListIterator有什么不同?==
- 都是迭代器,都可以用来遍历对应的实现类
Iterator允许遍历所有实现Iterator接口的实现类,而ListIterator只能遍历List集合- 两者都有
hasNext()、next()、remove()方法正向操作列表,ListIterator还可以进行逆向操作列表和往集合中添加元素
二、JMH测试ArrayList和LinkedList性能
2.1 JMH是什么?
官方介绍

简单介绍
JMH全称Java Microbenchmark Harness(Java微基准套件),是Oracle 官方Open JDK提供的一款==Java微基准性能测试工具==,主要是基于==方法层面的基准测试==,纳秒级精确度~
2.2 JMH应用场景?
【典型应用】
- 精确验证某个方法执行时间
- 测试接口不同实现的吞吐量
- 等等…
日常开发及优化Java代码时,当定位到热点方法,想进一步==优化热点方法的性能时==,可以通过JHM==精确验证某个方法执行时间==,根据测试结果不断进行优化~
2.3 JMH测试ArrayList和LinkedList(揭开真相)
应用场景不在于有多少,在于你用不用得到,这里我们就利用JMH==精确验证某个方法执行时间==,来验证本文的主题==LinkedList添加元素真的比ArrayList快?==
大致思路:
分别实现
LinkedList和ArrayList默认添加元素==即尾部添加元素==的方法~
利用JMH分别对两个方法进行基准测试,根据测试结果进行分析性能~
2.3.1 代码实现
(1)添加依赖
需要依赖==jmh-core==和==jmh-generator-annprocess==两个架包,可以去Maven官网下载~
Maven工程直接在pom.xml中添加依赖如下:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.26</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.26</version>
<scope>provided</scope>
</dependency>
(2)添加元素方法
package com.justin.java;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.Throughput) //基准测试类型:吞吐量(单位时间内调用了多少次)
@OutputTimeUnit(TimeUnit.MILLISECONDS) //基准测试结果的时间类型:毫秒
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) //预热:2 轮,每次1秒
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) //度量:测试5轮,每轮1秒
@Fork(1) //Fork出1个线程来测试
@State(Scope.Thread) // 每个测试线程分配1个实例
public class ArrayAndLinkedJmhTest {
private List<Object> arrayList;
private List<Object> linkedList;
@Param({"10", "100", "1000"})
private int count; //分别测试不同个数的添加元素
@Setup(Level.Trial)
public void init() {
arrayList = new ArrayList<>();
linkedList = new LinkedList<>();
}
public static void main(String[] args) throws RunnerException {
//启动基准测试
Options opt = new OptionsBuilder()
.include(ArrayAndLinkedJmhTest.class.getSimpleName()) //要导入的测试类
.output("C:\\Users\\Administrator\\Desktop\\ArrayAndLinkedJmhTest.log") //输出测试结果的文件
.build();
//执行测试
new Runner(opt).run();
}
@Benchmark
public void arrayListAddTest() {
for (int i = 0; i < count; i++) {
arrayList.add("Justin");
}
}
@Benchmark
public void linkedListAddTest() {
for (int i = 0; i < count; i++) {
linkedList.add("Justin");
}
}
}
注解说明
| 注解 | 说明 |
|---|---|
@BenchmarkMode(Mode.AverageTime) |
基准测试类型: AverageTime表示平均时间 |
@OutputTimeUnit(TimeUnit.NANOSECONDS) |
基准测试结果的时间类型:NANOSECONDS表示微秒 |
@Warmup(iterations = 5) |
预热:iterations指定预热迭代几轮 |
@Measurement(iterations = 10) |
度量:iterations 指定迭代几轮 |
@Fork(2) |
Fork出2个线程来测试 |
@State(Scope.Thread) |
每个测试线程分配1个实例 |
@Param({"10", "100", "1000"}) |
指定某项参数的多种情况,数值根据实际给定 |
@Setup(Level.Trial) |
初始化方法,在全部Benchmark运行之前进行 |
@BenchmarkMode |
用在方法上,表示该方法要进行基准测试,类似JUnit的@Test |
@TearDown(Level.Trial) |
结束方法,在全部Benchmark运行之后进行 |
更多官方Sample:
OpenJDK Samples
GitHub OpenJDK Samples
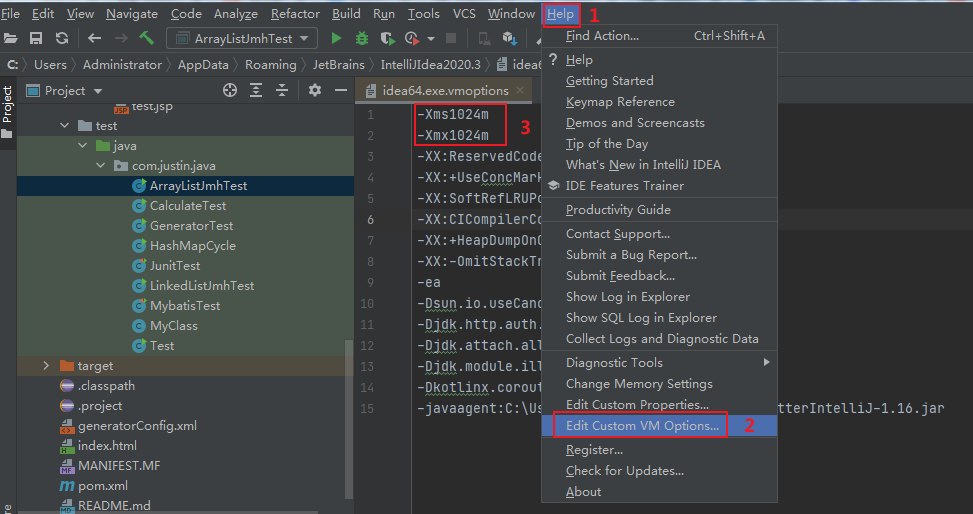
由于添加元素消耗的内存比较大,idea执行基准测试过程中可能会出现内存泄露的报错:==java.lang.OutOfMemoryError: Java heap space==
加大JVM的内存参数值即可,例如idea中调整方式:
Help -> Edit Custom VM Options…
2.3.2 结果分析
==分析输出的结果文件ArrayAndLinkedJmhTest.log,输出的内容很多,只要前面没有error都不用管,直接拉到最后看Score结果~==
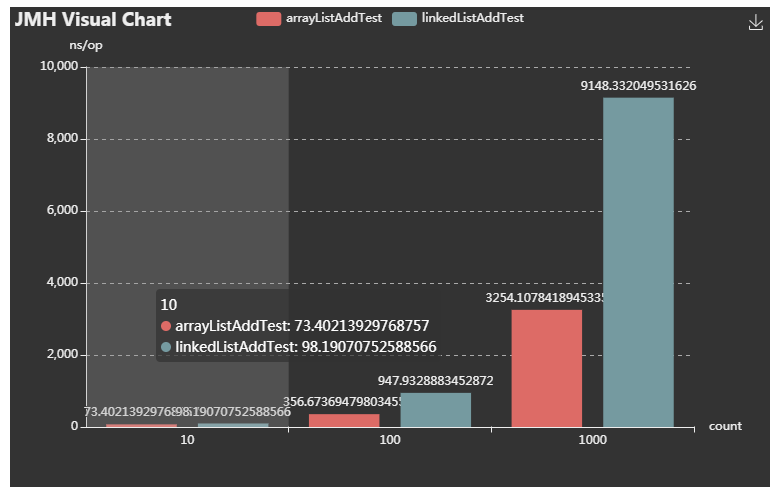
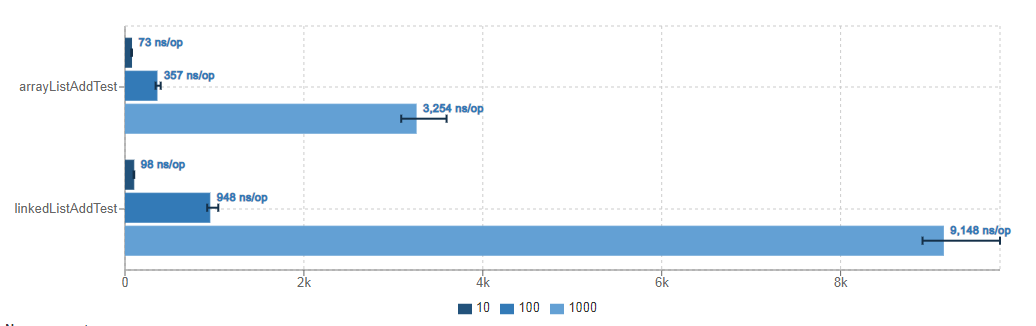
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 74.287 ± 1.629 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 371.329 ± 23.952 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 3118.537 ± 38.943 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 95.773 ± 1.261 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 907.471 ± 13.856 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 8901.777 ± 108.044 ns/op
示例中我们使用注解的是@BenchmarkMode(Mode.AverageTime)和OutputTimeUnit(TimeUnit.NANOSECONDS),因此测试的结果是ns/ops(每次调用需要多少微秒),每次调用添加相同的元素,平均时间越高,表明效率越低~
对应的结果指标是Score,可以看到ArrayList添加元素从少到多,效率都吊打LinkedList~
不过,细心的同学可能发现了,ArrayList之所以吊打LinkedList这么猛,是因为代码中ArrayList指定了合适的初始化容量大小
List<Object> arrayList = new ArrayList<>(count);
加上添加元素默认是在尾部进行,可谓是==如虎添翼==,ArrayList底层数据结构是数组,数组是一块连续的内存空间,从数组尾部添加数据时,不需要进行任何数组数据的复制重排,效率最高,时间复杂度为O(1)
ArrayList默认添加元素的关键源码
//关键源码1
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
...
//关键源码2
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
...
//关键源码3
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
...
//关键源码4
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
虽然LinkedList添加元素到尾部,也不需要查找元素,效率也是最高的,但是多了新节点对象创建以及变换指针指向对象的过程,时间复杂度为O(1)~
LinkedList默认添加元素源码
public boolean add(E e) {
linkLast(e);
return true;
}
...
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
==OK,那么问题来了,ArrayList默认初始化容量,添加元素的效率还能吊打LinkedList吗?==
我们来测试一下,首先修改测试代码中arrayListAddTest方法,去掉指定count~
List<Object> arrayList = new ArrayList<>();
ArrayList默认初始化容量添加元素,前面指定最大添加元素是1000数量级,测出的效率可能不是很明显,我这里再加个10000级别的(跑的好慢,差不多半个小时~)`~
@Param({"10", "100", "1000","10000"})
private int count; //指定添加元素的不同个数,便于分析结果
重新跑一次,看测试结果~
ArrayList默认容量大小的测试结果:
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 59.312 ± 1.726 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 560.263 ± 25.140 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 5144.459 ± 156.745 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 10000 avgt 20 49326.440 ± 1810.873 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 100.151 ± 2.699 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 976.157 ± 55.646 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 9472.496 ± 314.018 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10000 avgt 20 91279.112 ± 2883.922 ns/op
比对前面的ArrayList指定合适容量大小的测试结果:
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 74.287 ± 1.629 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 371.329 ± 23.952 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 3118.537 ± 38.943 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 95.773 ± 1.261 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 907.471 ± 13.856 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 8901.777 ± 108.044 ns/op
可以看到ArrayList使用默认容量大小进行添加元素时,虽然ArrayList多了数组扩容的过程,但是由于在尾部添加元素,效率还是比LinkedList添加元素效率高,只不过没有指定合适初始化容量大小时差距那么明显~
==那么在什么情况下LinkedList才比ArrayList添加元素效率高?==
答案是:==头部添加元素~==
ArrayList在数据结构头部添加元素比LinkedList效率低很多~
ArrayList越往数组前面添加元素,效率越低,头部添加数据,会导致后面的全部数组元素都要进行复制重排,效率最低~
LinkedList直接在头部或尾部,不需要进行二分查找,直接创建新节点元素及变换指针,效率最高~
不过需要注意的是LinkedList指定位置添加元素时,会先通过二分查找(中间划分,从前往后或从后往前遍历查找)查找到该位置的元素,当指定的位置元素刚好是中间时,二分查找发挥的作用最小,效率比较低~~
本文JHM测试主要验证==默认添加元素(尾部添加元素)==,至于头部及中间添加元素的效率对比,具体可以自行添加方法,通过JMH验证下~
2.3.3 结果分析(图形)
前面JMH输出的普通结果文件,虽然拉到能直接看到结果,不过有点不太直观,这里我们将 main方法的输出文件部分进行改造一下,重新执行输出json结果文件~
public static void main(String[] args) throws RunnerException {
//1、启动基准测试:输出json结果文件(用于查看可视化图)
Options opt = new OptionsBuilder()
.include(ArrayAndLinkedJmhTest.class.getSimpleName()) //要导入的测试类
.result("C:\\Users\\Administrator\\Desktop\\ArrayAndLinkedJmhTest.json") //输出测试结果的json文件
.resultFormat(ResultFormatType.JSON)//格式化json文件
.build();
//2、执行测试
new Runner(opt).run();
}
执行过程中可能看到ArrayAndLinkedJmhTest.json没有写入内容,不用管,==最后执行完会刷新到文件中==~
根据json结果文件利用以下推荐的图形化工具展示图形化结果~
-
JMH Visual Chart:http://deepoove.com/jmh-visual-chart/
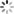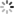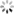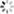
-
JMH Visualizer:https://jmh.morethan.io/
2.3.4 真相总结
==LinkedList真的比ArrayList添加元素快吗?==
通过Oracle官方Open JDK提供的Java微基准测试工具JMH进行测试,结合ArrayList和LinkedList自身的特性总结真相如下:
(1)
LinkedList添加元素不一定比ArrayList添加元素快~
(2)ArrayList底层数据结构是数组,数组是一块连续的内存空间,从数组尾部添加数据时,不需要进行任何数组数据的复制重排,效率最高,时间复杂度为O(1)~
(3)LinkedList添加元素到尾部和尾部时,都不需要查找元素,效率也是最高的,时间复杂度为O(1),不过会有新节点对象创建以及变换指针指向对象的过程~
(4)两者的添加元素的性能,通过Oracke官方Open JDK提供的JMH性能测试工具测试后发现,当ArrayList指定合适的初始化容量大小时,并且在数据结构尾部添加数据时,效率会远远大于LinkedList~
(5)但是实际开发当中,很多时候开发者编写new实例化ArrayList的代码时,都没有指定容量或者比较难预测到合适的初始化容量大小,默认初始化容量大小为0,首次添加元素默认容量会被指定为10,数组会进行==动态扩容==,每次扩容50%,因此我也使用JMH对这种默认容量的情况进行测试,不过发现即便不指定初始化容量大小,ArrayList添加元素效率还是比LinkedList添加元素效率高一些~
(6)最后再利用JMH在==头部进行添加元素==测试(本文暂时不贴具体测试过程和结果,大家自行测试看看),此时发现LinkedList添加元素的效率就比ArrayList高很多,主要原因是:
ArrayList越往数组前面添加元素,效率越低,头部添加数据,会导致后面的全部数组元素都要进行赋值重排,效率最低~
LinkedList往头部添加元素,不需要查找元素,直接进行新节点的创建以及指针变换,效率跟尾部添加一样,都是最高的,时间复杂度为O(1)~
通过正文及总结,你领悟到真相了吗?
如果领悟到了,那下次面试官再问LinkedList和ArrayList哪个快,把这篇文章丢给他看,哈哈哈!!!
附录
举一:
LinkedList真的比ArrayList添加元素快?
反三:
ArrayList和LinkedList遍历的效率如何?
String和StringBuilder字符串拼接效率如何?
HashMap那种遍历方式的效率更高?
==举一反三,你学废了?有空的小伙伴可以根据举一学到的技能,验证一下反三,肝完了,小伙伴们!!!!!==
原创不易,觉得有用的小伙伴来个一键三连(点赞+收藏+评论 )+关注支持一下,非常感谢~


- 点赞
- 收藏
- 关注作者
评论(0)