您需要了解的有关主成分分析 (PCA) 的所有信息

随着机器学习和人工智能领域的进步,了解这些技术背后的基本原理变得至关重要。这篇关于主成分分析的博客将帮助您理解降维背后的概念以及如何使用它来处理高维数据。
要深入了解人工智能和机器学习,您可以注册 Edureka 的实时 机器学习工程师硕士课程,提供 24/7 支持和终身访问。
需要主成分分析 (PCA)
当用于训练机器的数据集大而简洁时,机器学习通常会产生奇迹。通常拥有大量数据可以让我们构建更好的预测模型,因为我们有更多数据来训练机器。但是,使用大型数据集有其自身的缺陷。最大的陷阱是维度诅咒。
事实证明,在大维数据集中,可能存在大量的特征不一致或数据集中的大量冗余特征,这只会增加计算时间并使数据处理和EDA更加复杂。
为了摆脱 维数的诅咒,一个称为降维的过程被引入。降维技术可用于仅过滤训练所需的有限数量的重要特征,这就是 PCA 的用武之地。
什么是主成分分析 (PCA)?
主成分分析 (PCA) 是一种降维技术,可让您识别数据集中的相关性和模式,以便将其转换为维度明显更低的数据集,而不会丢失任何重要信息。
PCA 背后的主要思想是找出数据集中各种特征之间的模式和相关性。在发现不同变量之间的强相关性后,最终决定减少数据的维度,以便仍然保留重要数据。
这样的过程很 对于解决涉及使用高维数据集的复杂数据驱动问题至关重要。PCA 可以通过一系列步骤来实现。让我们讨论整个端到端的过程。
PCA的逐步计算
使用 PCA 执行降维需要遵循以下步骤:
让我们详细讨论每个步骤:
第 1 步:数据标准化
如果您熟悉数据分析和处理,就会知道错过标准化可能会导致结果有偏差。标准化就是对数据进行缩放,使所有变量及其值都在一个相似的范围内。
考虑一个例子,假设我们的数据集中有 2 个变量,一个的值在 10-100 之间,另一个的值在 1000-5000 之间。在这种情况下,很明显,使用这些预测变量计算的输出会产生偏差,因为范围越大的变量对结果的影响就越明显。
因此,将数据标准化到一个可比较的范围内是非常重要的。标准化是通过从平均值中减去数据中的每个值并将其除以数据集中的总体偏差来进行的。

执行此步骤后,数据中的所有变量都会在标准和可比较的范围内进行缩放。
步骤 2:计算协方差矩阵
如前所述,PCA 有助于识别数据集中特征之间的相关性和依赖性。协方差矩阵表示数据集中不同变量之间的相关性。识别重度因变量至关重要,因为它们包含有偏差和冗余的信息,这会降低模型的整体性能。
在数学上,协方差矩阵是 ap × p 矩阵,其中 p 表示数据集的维度。矩阵中的每个条目代表相应变量的协方差。
考虑我们有一个包含变量 a 和 b 的二维数据集的情况,协方差矩阵是一个 2×2 矩阵,如下所示:
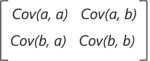
在上面的矩阵中:
- Cov(a, a) 表示变量与自身的协方差,也就是变量'a'的方差
- Cov(a, b) 表示变量“a”相对于变量“b”的协方差。由于协方差是可交换的,Cov(a, b) = Cov(b, a)
以下是协方差矩阵的关键要点:
简单的数学,不是吗?现在让我们继续看 PCA 的下一步。
步骤 3:计算特征向量和特征值
特征向量和特征值是必须从协方差矩阵计算出来的数学结构,以确定数据集的主成分。
但首先,让我们更多地了解主成分
什么是主成分?
简单地说,主成分是从初始变量集获得的新变量集。主成分的计算方式使得新获得的变量高度显着且彼此独立。主成分压缩并拥有分散在初始变量中的大部分有用信息。
如果您的数据集有 5 个维度,则计算 5 个主成分,这样,第一个主成分存储可能的最大信息,第二个存储剩余的最大信息,依此类推,您就明白了。
现在,特征向量在这整个过程中处于什么位置?
假设大家对特征向量和特征值有基本的了解,我们知道这两个代数公式总是成对计算的,即对于每个特征向量都有一个特征值。数据中的维度决定了您需要计算的特征向量的数量。
考虑一个二维数据集,为其计算 2 个特征向量(及其各自的特征值)。特征向量背后的想法是使用协方差矩阵来了解数据中方差最大的位置。由于数据中的更多方差表示有关数据的更多信息,特征向量用于识别和计算主成分。
另一方面,特征值只是表示各个特征向量的标量。因此,特征向量和特征值将计算数据集的主成分。
第 4 步:计算主成分
一旦我们计算了特征向量和特征值,我们所要做的就是按降序对它们进行排序,其中具有最高特征值的特征向量是最重要的,因此形成了第一主成分。因此可以去除重要性较低的主要成分以减少数据的维度。
计算的最后一步 主成分形成一个矩阵,称为特征矩阵,其中包含所有具有最大数据信息的重要数据变量。
第五步:减少数据集的维度
执行PCA的最后一步是用代表数据集最大和最重要信息的最终主成分重新排列原始数据。为了用新形成的主成分替换原始数据轴,您只需乘以原始数据的转置 得到的特征向量转置后的数据集。
这就是整个 PCA 过程背后的理论。是时候动手并使用真实数据集执行所有这些步骤了。
使用 Python 进行主成分分析
在本节中,我们将使用 Python 执行 PCA。如果您不熟悉 Python 编程语言,请阅读以下博客:
问题陈述:逐步进行主成分分析,以降低数据集的维数。
数据集描述:电影评级数据集,包含来自 700 多个用户对大约 9000 部电影(功能)的评级。
逻辑:通过查找数据中最重要的特征来执行 PCA。PCA 将按照上面定义的步骤执行。
让我们开始吧!
第 1 步:导入所需的包
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from matplotlib import*
import matplotlib.pyplot as plt
from matplotlib.cm import register_cmap
from scipy import stats
from sklearn.decomposition import PCA as sklearnPCA
import seaborn第二步:导入数据集
#Load movie names and movie ratings
movies = pd.read_csv('C:UsersNeelTempDesktopPCA DATAmovies.csv')
ratings = pd.read_csv('C:UsersNeelTempDesktopPCA DATAratings.csv')
ratings.drop(['timestamp'], axis=1, inplace=True)第 3 步:格式化数据
def replace_name(x):
return movies[movies['movieId']==x].title.values[0]
ratings.movieId = ratings.movieId.map(replace_name)
M = ratings.pivot_table(index=['userId'], columns=['movieId'], values='rating')
m = M.shape
df1 = M.replace(np.nan, 0, regex=True)第 4 步:标准化
在下面的代码行中,我们使用 sklearn 包提供的 StandardScalar() 函数来在可比较的范围内缩放数据集。如前所述,需要标准化以防止最终结果出现偏差。
X_std = StandardScaler().fit_transform(df1)步骤 5:计算协方差矩阵
如前所述,协方差矩阵表示数据集中不同特征之间的相关性。识别重度因变量至关重要,因为它们包含有偏差和冗余的信息,这会降低模型的整体性能。下面的代码片段计算数据的协方差矩阵:
mean_vec = np.mean(X_std, axis=0)
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)
print('Covariance matrix n%s' %cov_mat)
Covariance matrix
[[ 1.0013947 -0.00276421 -0.00195661 ... -0.00858289 -0.00321221
-0.01055463]
[-0.00276421 1.0013947 -0.00197311 ... 0.14004611 -0.0032393
-0.01064364]
[-0.00195661 -0.00197311 1.0013947 ... -0.00612653 -0.0022929
-0.00753398]
...
[-0.00858289 0.14004611 -0.00612653 ... 1.0013947 0.02888777
0.14005644]
[-0.00321221 -0.0032393 -0.0022929 ... 0.02888777 1.0013947
0.01676203]
[-0.01055463 -0.01064364 -0.00753398 ... 0.14005644 0.01676203
1.0013947 ]]第 6 步:计算特征向量和特征值
在这一步中计算特征向量和特征值,它们基本上计算数据集的主成分。
#Calculating eigenvectors and eigenvalues on covariance matrix
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors n%s' %eig_vecs)
print('nEigenvalues n%s' %eig_vals)
Eigenvectors
[[-1.34830861e-04+0.j 5.76715196e-04+0.j 4.83014783e-05+0.j ...
5.02355418e-14+0.j 6.48472777e-12+0.j 6.90776605e-13+0.j]
[ 5.61303451e-04+0.j -1.11493526e-02+0.j 8.85798170e-03+0.j ...
-2.38204858e-11+0.j -6.11345049e-11+0.j -1.39454110e-12+0.j]
[ 4.58686517e-04+0.j -2.39083484e-03+0.j 6.58309436e-04+0.j ...
-7.00290160e-12+0.j -5.53245120e-12+0.j 3.35918400e-13+0.j]
...
[ 5.22202072e-03+0.j -5.49944367e-03+0.j 5.16164779e-03+0.j ...
2.53271844e-10+0.j 9.69246536e-10+0.j 5.86126443e-11+0.j]
[ 8.97514078e-04+0.j -1.14918748e-02+0.j 9.41277803e-03+0.j ...
-3.90405498e-10+0.j -7.88691586e-10+0.j -2.80604702e-11+0.j]
[ 4.36362199e-03+0.j -7.90241494e-03+0.j -7.48537922e-03+0.j ...
-6.38353830e-10+0.j -6.47370973e-10+0.j 1.41147483e-13+0.j]]
Eigenvalues
[ 1.54166656e+03+0.j 4.23920460e+02+0.j 3.19074475e+02+0.j ...
8.84301723e-64+0.j 1.48644623e-64+0.j -3.46531190e-65+0.j]步骤 7:计算特征向量
在这一步中,我们按降序重新排列特征值。这表示按降序排列的主成分的重要性:
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
print('Eigenvalues in descending order:')
for i in eig_pairs:
print(i[0])
Eigenvalues in descending order:
1541.6665576008295
423.92045998539083
319.07447507743535
279.33035758081536
251.63844082955103
218.62439973216058
154.61586911307694
138.60396745179094
137.6669785626203
119.37014654115806
115.2795566625854
105.40594030056845
97.84201186745533
96.72012660587329
93.39647211318346
87.7491937345281
87.54664687999116
85.93371257360843
72.85051428001277
70.37154679336622
64.45310203297905
63.78603164551922
62.11260590665646
60.080661628776205
57.67255079811343
56.490104252992744
55.48183563193681
53.78161965096411
....第八步:使用PCA()函数对数据集进行降维
下面的代码片段使用 sklearn 包提供的预定义 PCA() 函数来转换数据。n_components 参数表示您想要拟合数据的主成分数:
pca = PCA(n_components=2)
pca.fit_transform(df1)
print(pca.explained_variance_ratio_)
[0.13379809 0.03977444]输出显示 PC1 和 PC2 约占数据集中方差的 14%。
第 9 步:投影主成分的方差
为了深入了解数据相对于不同数量的主成分的方差,让我们绘制一个碎石图。在统计学中,碎石图表示与每个主成分相关的方差:
pca = PCA().fit(X_std)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance')
plt.show()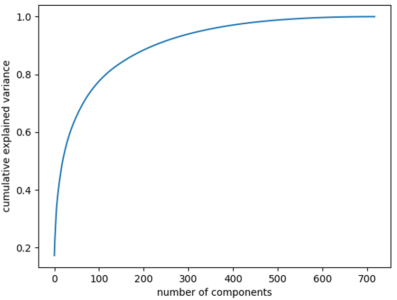
碎石图清楚地表明前 500 个主成分包含数据中的最大信息(方差)。请注意,初始数据集有大约 9000 个特征,现在可以缩小到仅 500 个。因此,您现在可以轻松地对数据进行进一步分析,因为冗余或无关紧要的变量已被排除。这就是降维的力量。
现在您已经了解了主成分分析背后的数学原理,我相信您很想了解更多信息。以下博客列表可帮助您开始了解其他统计概念:
有了这个,我们来到了这个博客的结尾。如果您对此主题有任何疑问,请在下方留言,我们会尽快回复您。
- 点赞
- 收藏
- 关注作者
评论(0)