做开发的你,怎么能没读过《Head First设计模式》(一)

写在前面:
- 博客主要是以书里内容为主,关于博客里的UML图,小伙伴有需要的可以联系我,生活加油 😦
-
笔记内容:这本书的设计模式不全,所以结合菜鸟教程上的笔记,还有那本著名的《设计模式_可复用面向对象软件的基础》的部分,《设计模式_可复用面向对象软件的基础》这本以后有时间刷,感觉非常不错,就是有些重,有些还是读不懂,水平有限,不适合快速学习,如果时间多,强烈建议小伙伴真的要刷一下,超级棒,需要资源可以联系我 😃
我只是怕某天死了,我的生命却一无所有。----《奇幻之旅》
嗯,看书学习之前,先了解下面向对象设计原则吧
| 名称 | 描述 |
|---|---|
| 单一职责原则(SRP:Single responsibility principle) | 单一职责原则:一个类应该只有一个发生变化的原因,应该只有一个职责 |
| 开闭原则(Open Close Principle) | 开闭原则的意思是:对扩展开放,对修改关闭。 |
| 里氏代换原则(Liskov Substitution Principle) | 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。 |
| 依赖倒转原则(Dependence Inversion Principle) | 这个原则是开闭原则的基础,具体内容:针对接口编程,依赖于抽象而不依赖于具体。 |
| 接口隔离原则(Interface Segregation Principle) | 这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。 |
| 迪米特法则,又称最少知道原则(Demeter Principle) | 最少知道原则是指:一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。 |
| 合成复用原则(Composite Reuse Principle) | 合成复用原则是指:尽量使用合成/聚合的方式,而不是使用继承。 |
里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
嗯,学设计模式,多态的概念是必须要掌握的,我们在看下多态吧:
特定的多态分为过载多态(overloading)和强制多态(coercion) .
| 多态类型 | 描述 | 实例 |
|---|---|---|
强制多态 |
编译程序通过语义操作,把操作对象的类型强行加以变换,以符合函数或操作符的要求。程序设计语言中基本类型的大多数操作符,在发生不同类型的数据进行混合运算时,编译程序一般都会进行强制多态。程序员也可以显示地进行强制多态的操作(Casting) 。 | 三元运算符返回类型总是最大的那个,强制类型转化符 |
过载(overloading)多态 |
同一个名(操作符、函数名)在不同的上下文中有不同的类型`。程序设计语言中基本类型的大多数操作符都是过载多态的。 | 通过不同的方法签名实现方法重载 |
通用的多态又分为参数多态(parametric)和包含多态(inclusion) ;
| 多态类型 | 描述 | 实例 |
|---|---|---|
参数多态 |
采用参数化模板,通过给出不同的类型参数,使得一个结构有多种类型 | 对应中java中的泛型的概念public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable |
包含多态 |
同样的操作可用于一个类型及其子类型。(注意是子类型,不是子类。)包含多态一般需要进行运行时的类型检查。 | 定义接口引用,运行时动态绑定实现类实例 |
两者的区别是:
- 前者对工作的类型不加限制,允许对不同类型的值执行相同的代码;
- 后者只对有限数量的类型有效,而且对不同类型的值可能要执行不同的代码。
嗯,学设计模式之前,先大概整体了解下吧,如果想在项目中使用,这些应该都要熟悉。
| 设计模式名称 | 简要说明 | 速记关键字 |
|---|---|---|
| Abstract Factory 抽象工厂模式 | 提供一个接口,可以创建一系列相关或相互依赖的对象而无需指定它们具体的类 | 生产成系列对象 |
| Builder 构建器模式 | 将一个复杂类的表示与其构造相分离,使得相同的构建过程能够得出不同的表示 | 复杂对象构造 |
| Factory Method 工厂方法模式 | 定义一个创建对象的接口,但由子类决定需要实例化哪一个类。工厂方法使得子类实例化的过程推迟 | 动态生产对象 |
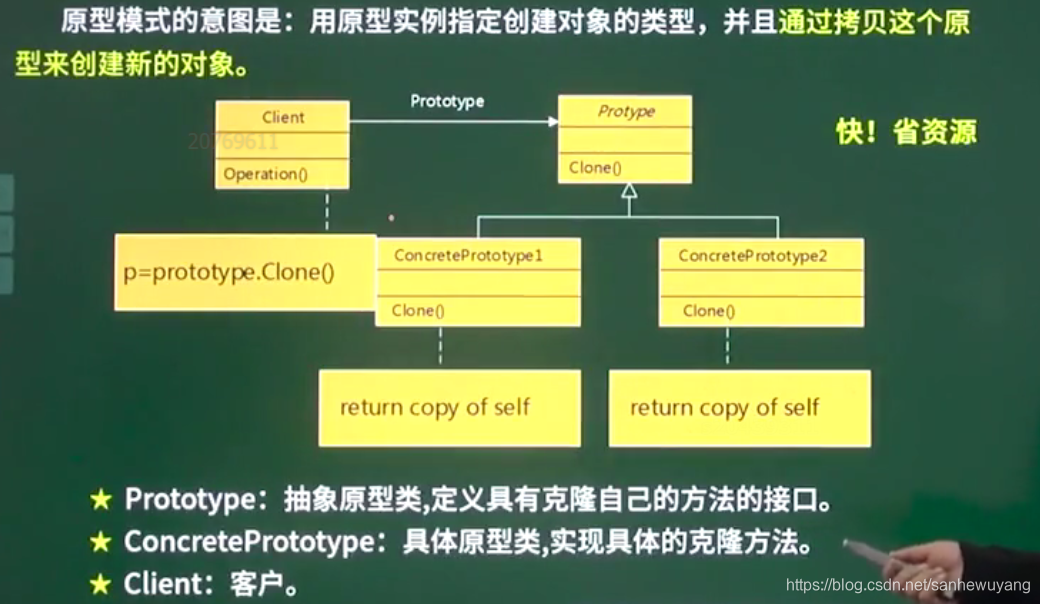
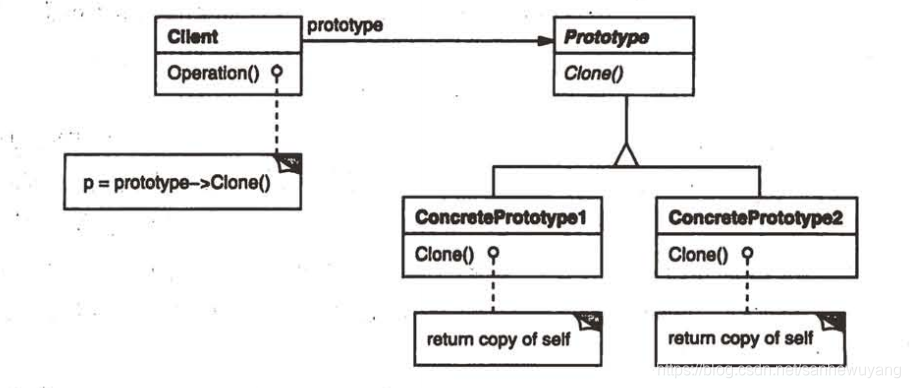
| Prototype 原型模式 | 用原型实例指定创建对象的类型,并且通过接贝这个原型来创建新的对象 | 克隆对象 |
| singleton 单例模式 | 保证一个类只有一个实例,并提供一个访问它的全局访问点 | 单实例 |
| 设计模式名称 | 简要说明 | 速记关键字 |
|---|---|---|
| Adapter 适配器模式 | 将一个类的接口转换成用户希望得到的另一种接口。它使原本不相容的接口得以协同工作 | 转换接口 |
| Bridge 桥接模式 | 将类的抽象部分和它的实现部分分离开来,使它们可以独立地变化 | 继承树拆分 |
| Composite组合模式 | 将对象组合成树型结构以表示“整体-部分”的层次结构,使得用户对单个对象和组合对象的使用具有一致性 | 树形目录结构 |
| Decorator装饰模式 | 动态地给一个对象添加一些额外的职责。它提供了用子类扩展功能的一个灵活的替代,比派生一个子类更加灵活 | 附加职责 |
| Facade外观模式 | 定义一个高层接口,为子系统中的一组接口提供一个一致的外观,从而简化了该子系统的使用 | 对外统一接口 |
| Flyweight 享元模式 | 提供支持大量细粒度对象共享的有效方法 | 文章共享文字对象 |
| 设计模式名称 | 简要说明 | 速记关键字 |
|---|---|---|
| Chain of Responsibility 职责链模式 | 通过给多个对象处理请求的机会,减少请求的发送者与接收者之间的耦合。将接收对象链接起来,在链中传递请求,直到有一个对象处理这个请求 | 传递职责 |
| Command 命令模式 | 将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化,将请求排队或记录请求日志,支持可撒销的操作 | 日志记录,可撒销 |
| Interpreter 解释器模式 | 给定一种语言,定义它的文法表示,并定义一个解释器,该解释器用来根据文法表示来解释语言中的句子 | 虚拟机的机制?? |
| Iterator 迭代器模式 | 提供一种方法来顺序访问一个聚合对象中的各个元素,而不需要暴露该对象的内部表示 | 数据库数据集 |
| Mediator 中介者模式 | 用一个中介对象来封装一系列的对象交互。它使各对象不需要显式地相互调用,从而达到低耦合,还可以独立地改变对象间的交互 | 不直接引用 |
| Memento 备忘录模式 | 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,从而可以在以后将该对象恢复到原先保存的状态 | 可恢复 |
| Observer 观察者模式 | 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新 | 联动 |
| State 状态模式 | 允许一个对象在其内部状态改变时改变它的行为 | 状态变成类 |
| Strategy 策略模式 | 定义一系列算法,把它们一个个封装起来,并且使它们之间可互相替换,从而让算法可以独立于使用它的用户而变化 | 多方案切换 |
| TemplateMethod 模板方法模式 | 定义一个操作中的算法骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重新定义算法的某些特定步骤 | 文档模板填空 |
| Visitor 访问者模式 | 表示一个作用于某对象结构中的各元素的操作,使得在不改变各元素的类的前提下定义作用于这些元素的新操作 | 数据与操作分离 |
下面我们就开动啦…嘻嘻,好激动,嗯,笔记不是按照书里的记得,后面根据模式类型调整啦,第一书里原本是策略模式啦…嗯
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
意图:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。主要解决:在运行期建立和删除原型。何时使用: 1、当一个系统应该独立于它的产品创建,构成和表示时。 2、当要实例化的类是在运行时刻指定时,例如,通过动态装载。 3、为了避免创建一个与产品类层次平行的工厂类层次时。 4、当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。如何解决:利用已有的一个原型对象,快速地生成和原型对象一样的实例。关键代码: 1、实现克隆操作,在 JAVA 继承 Cloneable,重写 clone(),在 .NET 中可以使用 Object 类的 MemberwiseClone() 方法来实现对象的浅拷贝或通过序列化的方式来实现深拷贝。 2、原型模式同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,它同样要求这些"易变类"拥有稳定的接口。
应用实例: 1、细胞分裂。 2、JAVA 中的 Object clone() 方法。优点: 1、性能提高。 2、逃避构造函数的约束。缺点: 1、配备克隆方法需要对类的功能进行通盘考虑,这对于全新的类不是很难,但对于已有的类不一定很容易,特别当一个类引用不支持串行化的间接对象,或者引用含有循环结构的时候。 2、必须实现Cloneable接口。
使用场景: 1、资源优化场景。 2、类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。 3、性能和安全要求的场景。 4、通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。 5、一个对象多个修改者的场景。 6、一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。 7、在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
注意事项:与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现 Cloneable,重写,深拷贝是通过实现 Serializable 读取二进制流。

public abstract class Shape implements Cloneable {
private String id;
protected String type;
abstract void draw();
public String getType(){
return type;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
@Override
public Object clone() {
Object clone = null;
try {
clone = super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return clone;
}
}
public class Rectangle extends Shape {
public Rectangle(){
type = "Rectangle";
}
@Override
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}
}
public class Square extends Shape {
public Square(){
type = "Square";
}
@Override
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
public class Circle extends Shape {
public Circle(){
type = "Circle";
}
@Override
public void draw() {
System.out.println("Inside Circle::draw() method.");
}
}
import java.util.Hashtable;
public class ShapeCache {
private static Hashtable<String, Shape> shapeMap
= new Hashtable<String, Shape>();
public static Shape getShape(String shapeId) {
Shape cachedShape = shapeMap.get(shapeId);
return (Shape) cachedShape.clone();
}
// 对每种形状都运行数据库查询,并创建该形状
// shapeMap.put(shapeKey, shape);
// 例如,我们要添加三种形状
public static void loadCache() {
Circle circle = new Circle();
circle.setId("1");
shapeMap.put(circle.getId(),circle);
Square square = new Square();
square.setId("2");
shapeMap.put(square.getId(),square);
Rectangle rectangle = new Rectangle();
rectangle.setId("3");
shapeMap.put(rectangle.getId(),rectangle);
}
}
public class PrototypePatternDemo {
public static void main(String[] args) {
ShapeCache.loadCache();
Shape clonedShape = (Shape) ShapeCache.getShape("1");
System.out.println("Shape : " + clonedShape.getType());
Shape clonedShape2 = (Shape) ShapeCache.getShape("2");
System.out.println("Shape : " + clonedShape2.getType());
Shape clonedShape3 = (Shape) ShapeCache.getShape("3");
System.out.println("Shape : " + clonedShape3.getType());
}
}
执行程序,输出结果:
Shape : Circle
Shape : Square
Shape : Rectangle
Prototype有许多和Abstract Factory和Builder 一样的效果:它对客户隐藏了具体的产品类,因此减少了客户知道的名字的数目。此外,这些模式使客户无需改变即可使用与特定应用相关的类。下面列出Prototype模式的另外一些优点。
1)
运行时刻增加和删除产品Prototype允许只通过客户注册原型实例就可以将一个新的具体产品类并入系统。它比其他创建型模式更为灵活,因为客户可以在运行时刻建立和删除原型
2)改变值以指定新对象高度动态的系统允许你通过对象复合定义新的行为-例如,通过为一个对象变量指定值-并且不定义新的类。你通过实例化已有类并且将这些实例注册为客户对象的原型,就可以有效定义新类别的对象。客户可以将职责代理给原型,从而表现出新的行为。这种设计使得用户无需编程即可定义新“类”。实际上,克隆一个原型类似于实例化一个类。Prototype模式可以极大的减少系统所需要的类的数目。
3)改变结构以指定新对象许多应用由部件和子部件来创建对象。例如电路设计编辑器就是由子电路来构造电路的。。为方便起见,这样的应用通常允许你实例化复杂的、用户定义的结构,比方说,一次又一次的重复使用一个特定的子电路。Prototype模式也支持这一点。我们仅需将这个子电路作为一个原型增加到可用的电路元素选择板中。只要复合电路对象将Clone实现为一个深拷贝(deep copy ),具有不同结构的电路就可以是原型了。
4)减少子类的构造Factory Method ( 3.3)经常产生一个与产品类层次平行的Creator类层次。Prototype模式使得你克隆一个原型而不是请求一个工厂方法去产生一个新的对象。因此你根本不需要Creator类层次。
5)用类动态配置应用一些运行时刻环境允许你动态将类装载到应用中。Prototype的主要缺陷是每一个Prototype的子类都必须实现Clone操作,这可能很困难。例如,当所考虑的类已经存在时就难以新增Clone操作。当内部包括一些不支持拷贝或有循环引用的对象时,实现克隆可能也会很困难的。
主要解决:一个全局使用的类频繁地创建与销毁。何时使用:当您想控制实例数目,节省系统资源的时候。如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。关键代码:公有的方法获取实例, 私有的构造方法,私有的成员变量。应用实例:
1 、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
2 、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
3 、要求生产唯一序列号。
4 、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
5 、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
优点:在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。避免对资源的多重占用(比如写文件操作)。
缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
饿汉式单例关键在于singleton作为类变量并且直接得到了初始化,即类中所有的变量都会被初始化 singleton作为类变量在初始化的过程中会被收集进<clinit>()方法中,该方法能够百分之百的保证同步,但是因为不是懒加载,singleton被加载后可能很长一段时间不被使用,即实例所开辟的空间会存在很长时间.
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private static final Singleton singleton1 = new Singleton();
public static Singleton getInstance1(){
return singleton1;
}
懒汉式单例模式,可以保证懒加载,但是线程不安全, 当有两个线程访问时,不能保证单例的唯一性
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private static Singleton singleton =null;
public static Singleton getInstance(){
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
懒汉式+同步方法单例模式,即能保证懒加载,又可以保证singleton实例的唯一性,但是synchronizeed关键字的排他性导致getInstance0()方法只能在同一时间被一个线程访问。性能低下。
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private static Singleton singleton =null;
public static synchronized Singleton getInstance0(){
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
双重校验锁单例(Double-Check)+Volatile对懒汉-同步方法的改进,当有两个线程发现singleton为null时,只有一个线程可以进入到同步代码块里。即满足了懒加载,又保证了线程的唯一性,不加volition的缺点,有时候可能会报NPE,(JVM运行指令重排序),有可能实例对象的变量未完成实例化其他线程去获取到singleton变量。未完成初始化的实例调用其方法会抛出空指针异常。
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private static volatile Singleton singleton2 = null;
public static Singleton getInstance4() {
if (singleton2 == null){
synchronized (Singleton.class){
if (singleton2 ==null){
singleton2 = new Singleton();
}
}
}
return singleton2;
}
静态内部类的单例模式在Singleton类初始化并不会创建Singleton实例,在静态内部类中定义了singleton实例。 当给静态内部类被主动创建时则会创建Singleton静态变量,是最好的单例模式之一,;类似于静态工厂,将类的创建延迟到静态内部类,外部类的初始化不会实例化静态内部类的静态变量。
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private static class Singtetons{
private static Singleton SINGLETON = new Singleton();
/* static {
final Singleton SINGLETON = new Singleton();
}*/
}
public static Singleton getInstance2(){
return Singtetons.SINGLETON;
}
基于枚举类线程安全枚举类型不允许被继承,同样线程安全的,且只能被实例化一次。
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
public class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
private enum Singtetons {
SINGTETONS; //实例必须第一行,默认 public final static修饰
private Singleton singleton;
Singtetons() { //构造器。默认私有
this.singleton = new Singleton();
}
public static Singleton getInstance() {
return SINGTETONS.singleton;
}
}
public static Singleton getInstance3(){
return Singtetons.getInstance();
}
Singleton模式有许多优点:
1)
对唯一实例的受控访问因为Singleton类封装它的唯一实例,所以它可以严格的控制
2)缩小名空间Singleton模式是对全局变量的一种改进。它避免了那些存储唯一实例的全局变量污染名空间。
3)允许对操作和表示的精化Singleton类可以有子类,而且用这个扩展类的实例来配置一个应用是很容易的。你可以用你所需要的类的实例在运行时刻配置应用。
4)允许可变数目的实例这个模式使得你易于改变你的想法,并允许Singleton类的多个,实例。此外,你可以用相同的方法来控制应用所使用的实例的数目。只有允许访问Singleton实例的操作需要改变。
5)比类操作更灵活另一种封装单件功能的方式是使用类操作(即C++中的静态成员函数或者是Smallak中的类方法),但这两种语言技术都难以改变设计以允许一个类有多个实例。此外, C++中的静态成员函数不是虚函数,因此子类不能多态的重定义它们。

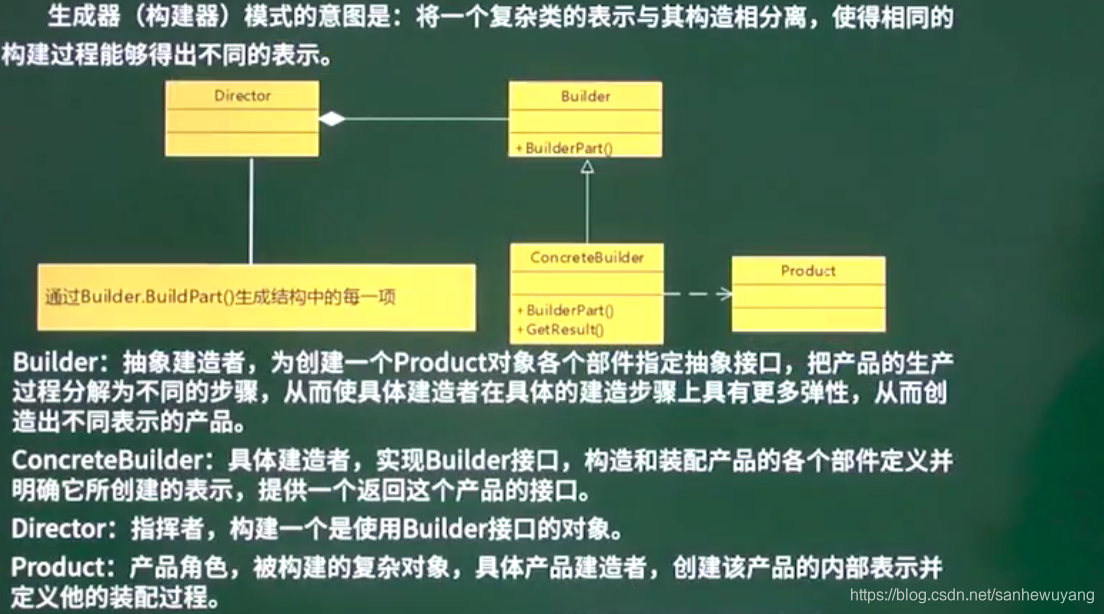
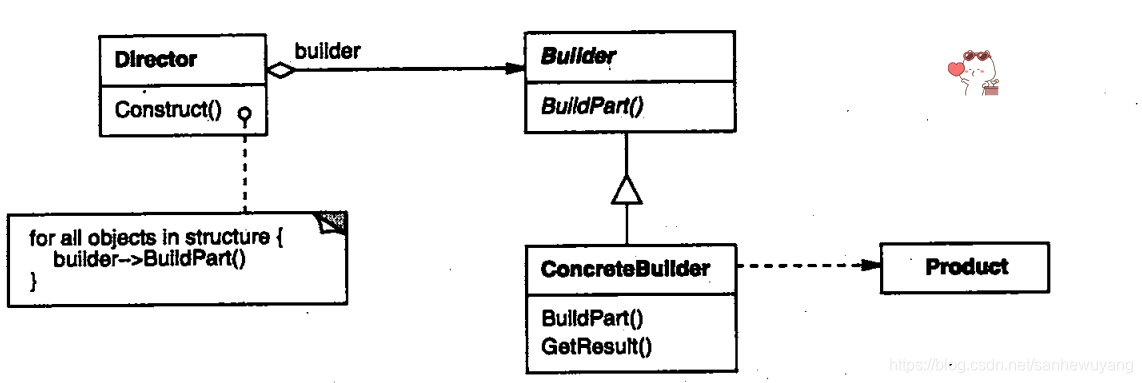
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
意图:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。主要解决:主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。何时使用:一些基本部件不会变,而其组合经常变化的时候。如何解决:将变与不变分离开。应用实例:
- 、去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的,生成出所谓的"套餐"。
- 、JAVA 中的 StringBuilder。
- 、构建一个Excel表格,不通数据可能有不同的构建逻辑。形成不同的表格
优点: 1、建造者独立,易扩展。 2、便于控制细节风险。缺点: 1、产品必须有共同点,范围有限制。 2、如内部变化复杂,会有很多的建造类。使用场景: 1、需要生成的对象具有复杂的内部结构。 2、需要生成的对象内部属性本身相互依赖。注意事项:与工厂模式的区别是:建造者模式更加关注与零件装配的顺序。
我们假设一个快餐店的商业案例,其中,一个典型的套餐可以是一个汉堡(Burger)和一杯冷饮(Cold drink)。汉堡(Burger)可以是素食汉堡(Veg Burger)或鸡肉汉堡(Chicken Burger),它们是包在纸盒中。冷饮(Cold drink)可以是可口可乐(coke)或百事可乐(pepsi),它们是装在瓶子中。
我们将创建一个表示食物条目(比如汉堡和冷饮)的 Item 接口和实现 Item 接口的实体类,以及一个表示食物包装的 Packing 接口和实现 Packing 接口的实体类,汉堡是包在纸盒中,冷饮是装在瓶子中。
然后我们创建一个 Meal 类,带有 Item 的 ArrayList 和一个通过结合 Item 来创建不同类型的 Meal 对象的 MealBuilder。BuilderPatternDemo 类使用 MealBuilder 来创建一个 Meal。
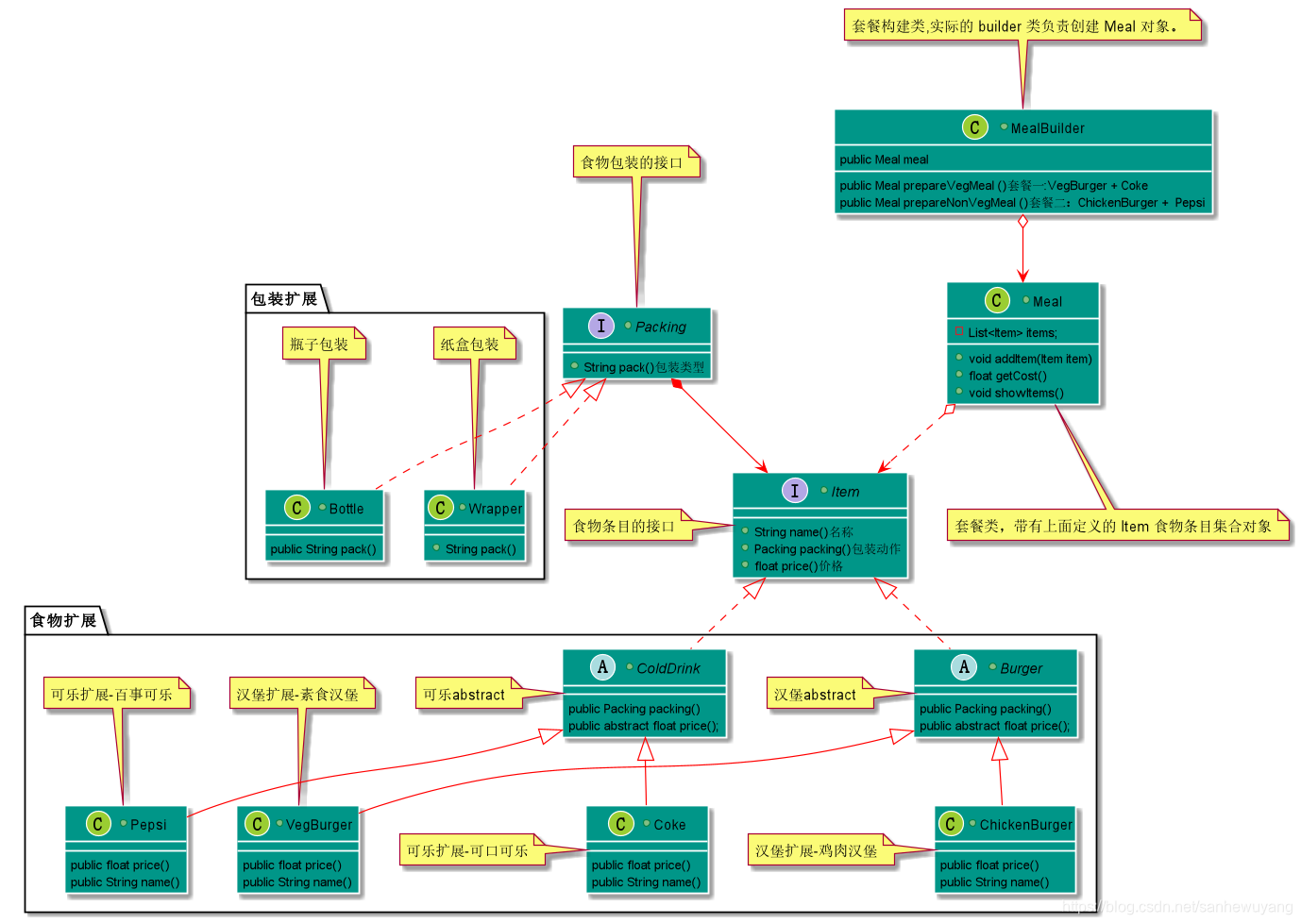
//食物条目的接口
public interface Item {
public String name();
//包装
public Packing packing();
//价格
public float price();
}
//食物包装的接口
public interface Packing {
public String pack();
}
//纸盒包装
public class Wrapper implements Packing {
@Override
public String pack() {
return "纸盒包装";
}
}
//瓶子包装
public class Bottle implements Packing {
@Override
public String pack() {
return "瓶子包装";
}
}
//汉堡
public abstract class Burger implements Item {
@Override
public Packing packing() {
return new Wrapper();
}
@Override
public abstract float price();
}
//可乐
public abstract class ColdDrink implements Item {
@Override
public Packing packing() {
return new Bottle();
}
@Override
public abstract float price();
}
//汉堡扩展-素食汉堡
public class VegBurger extends Burger {
@Override
public float price() {
return 25.0f;
}
@Override
public String name() {
return "素食汉堡";
}
}
//汉堡扩展-鸡肉汉堡
public class ChickenBurger extends Burger {
@Override
public float price() {
return 50.5f;
}
@Override
public String name() {
return "鸡肉汉堡";
}
}
//可乐扩展-可口可乐
public class Coke extends ColdDrink {
@Override
public float price() {
return 30.0f;
}
@Override
public String name() {
return "可口可乐";
}
}
//可乐扩展-百事可乐
public class Pepsi extends ColdDrink {
@Override
public float price() {
return 35.0f;
}
@Override
public String name() {
return "百事可乐";
}
}
import java.util.ArrayList;
import java.util.List;
//套餐类
public class Meal {
private List<Item> items = new ArrayList<Item>();
public void addItem(Item item){
items.add(item);
}
public float getCost(){
float cost = 0.0f;
for (Item item : items) {
cost += item.price();
}
return cost;
}
public void showItems(){
for (Item item : items) {
System.out.print("Item : "+item.name());
System.out.print(", Packing : "+item.packing().pack());
System.out.println(", Price : "+item.price());
}
}
}
public class MealBuilder {
//套餐一
public Meal prepareVegMeal (){
Meal meal = new Meal();
meal.addItem(new VegBurger());
meal.addItem(new Coke());
return meal;
}
//套餐二
public Meal prepareNonVegMeal (){
Meal meal = new Meal();
meal.addItem(new ChickenBurger());
meal.addItem(new Pepsi());
return meal;
}
}
public class BuilderPatternDemo {
public static void main(String[] args) {
MealBuilder mealBuilder = new MealBuilder();
Meal vegMeal = mealBuilder.prepareVegMeal();
System.out.println("Veg Meal");
vegMeal.showItems();
System.out.println("Total Cost: " +vegMeal.getCost());
Meal nonVegMeal = mealBuilder.prepareNonVegMeal();
System.out.println("\n\nNon-Veg Meal");
nonVegMeal.showItems();
System.out.println("Total Cost: " +nonVegMeal.getCost());
}
}
- 1)
它使你可以改变一个产品的内部表示Builder对象提供给导向器一个构造产品的抽象接口。该接口使得生成器可以隐藏这个产品的表示和内部结构。它同时也隐藏了该产品是如何装配的。因为产品是通过抽象接口构造的,你在改变该产品的内部表示时所要做的只是定义一个新的生成器。- 2)
它将构造代码和表示代码分开, Builder模式通过封装一个复杂对象的创建和表示方式提高了对象的模块性。客户不需要知道定义产品内部结构的类的所有信息;这些类是不出现在Builder接口中的。每个ConcreteBuilder包含了创建和装配一个特定产品的所有代码。这些代码只需要写一次;然后不同的Director可以复用它以在相同部件集合的基础上构作不同的Product,在前面的RTF例子中,我们可以为RTF格式以外的格式定义一个阅读器,比如一个SGMLReader,并使用相同的TextConverter生成SGMLX档的ASCIIText, TexText和TextWidget译本。- 3)
它使你可对构造过程进行更精细的控制Builder模式与一下子就生成产品的创建型模式不同,它是在导向者的控制下一步一步构造产品的。仅当该产品完成时导向者才从生成器中取回它。因此Builder接口相比其他创建型模式能更好的反映产品的构造过程。这使你可以更精细的控制构建过程,从而能更精细的控制所得产品的内部结构。
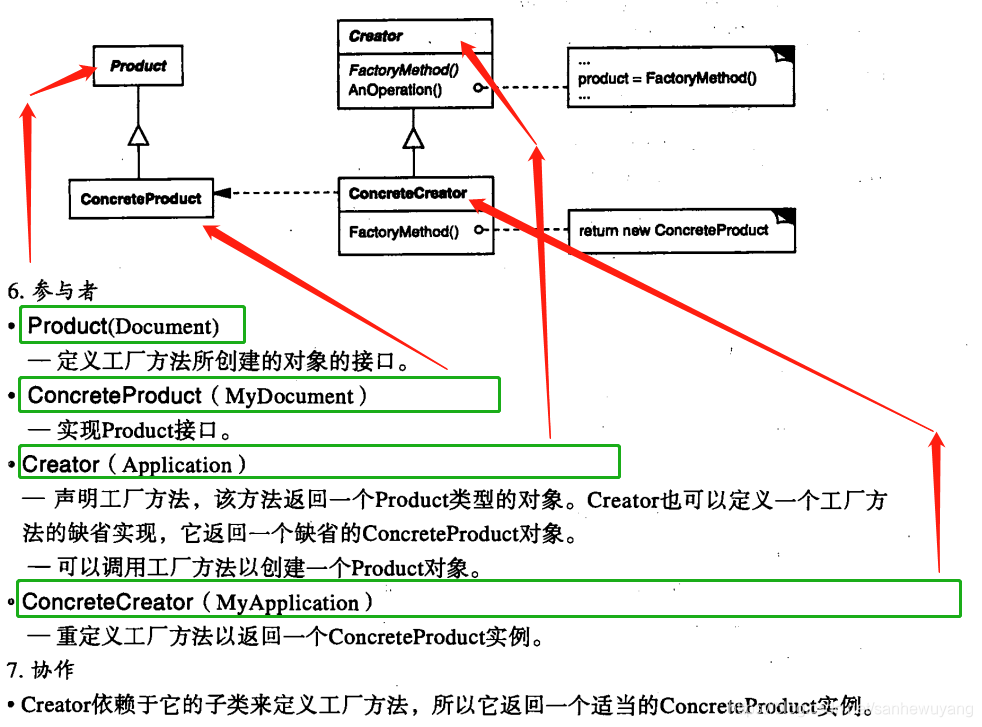
情境:如何将实例化具体类的代码从应用中抽离,或者封装起来,使它们不会干扰应用的其他部分?
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
分为:简单工厂模式,工厂方法模式
区别:
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
- 屏蔽产品的具体实现,调用者只关心产品的接口。
- . 对于静态工厂来讲,不必在每次
调用它们的时候都创建一个新对象。 它从来不创建对象。 这种方法类似于享元 (Flyweight)模式 。 如果程序经常请求创建相同的对象,并且创建对象的代价很高,则这项技术可以极大地提升性能。它们可以返回原返回类型的任何子类 型的对象。 所返回的对象的类可以随着每次调用而发生变化,这取 决于静态工厂方法的参数值。 性能上优于构造方法。
- 每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加.
- 在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
- 日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
- 数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
- 设计一个连接服务器的框架,需要三个协议,“POP3”、“IMAP”、“HTTP”,可以把这三个作为产品类,共同实现一个接口。
注意事项:作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
静态工厂方法实现jdk源码Boolean对象通过静态工厂生成
/**
* The Boolean class wraps a value of the primitive type
* {@code boolean} in an object. An object of type
* {@code Boolean} contains a single field whose type is
* {@code boolean}.
* <p>
* In addition, this class provides many methods for
* converting a {@code boolean} to a {@code String} and a
* {@code String} to a {@code boolean}, as well as other
* constants and methods useful when dealing with a
* {@code boolean}.
*
* @author Arthur van Hoff
* @since JDK1.0
*/
public final class Boolean implements java.io.Serializable,
Comparable<Boolean>
{
/**
* The {@code Boolean} object corresponding to the primitive
* value {@code true}.
*/
public static final Boolean TRUE = new Boolean(true);
/**
* The {@code Boolean} object corresponding to the primitive
* value {@code false}.
*/
public static final Boolean FALSE = new Boolean(false);
/**
* Allocates a {@code Boolean} object representing the
* {@code value} argument.
*
* <p><b>Note: It is rarely appropriate to use this constructor.
* Unless a <i>new</i> instance is required, the static factory
* {@link #valueOf(boolean)} is generally a better choice. It is
* likely to yield significantly better space and time performance.</b>
*
* @param value the value of the {@code Boolean}.
*/
public Boolean(boolean value) {
this.value = value;
}
/**
* Returns a {@code Boolean} instance representing the specified
* {@code boolean} value. If the specified {@code boolean} value
* is {@code true}, this method returns {@code Boolean.TRUE};
* if it is {@code false}, this method returns {@code Boolean.FALSE}.
* If a new {@code Boolean} instance is not required, this method
* should generally be used in preference to the constructor
* {@link #Boolean(boolean)}, as this method is likely to yield
* significantly better space and time performance.
* TODO 如果不是必需的新{@code boolean}实例,则此方法通常应优先于构造函数{@link #boolean(boolean)},因为此方法可能会产生明显更好的空间和时间性能。
* @param b a boolean value.
* @return a {@code Boolean} instance representing {@code b}.
* @since 1.4
*/
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
}
实例构建不同类型的小汽车,对于简单工厂模式,有一个问题就是,
类的创建依赖工厂类,也就是说,如果想要拓展程序,必须对工厂类进行修改。假如增加其他,工厂类需要修改,不满足开闭原则如何解决?就用到工厂方法模式,创建一个工厂接口和创建多个工厂实现类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
比如:比亚迪的产品线原来生成汽车的,后来疫情来了,要生产口罩,使用工厂方法模式后,核心的产品模式没变,只需要增加新的生产口罩的工厂类就可以了,不需要改变之前生产汽车的工厂。

/**
* @Description : 产品
* @Author: Liruilong
* @Date: 2019/9/12 19:35
*/
public abstract class Product {
public abstract void use();
}
/**
* @Description : 抽象工厂
* @Author: Liruilong
* @Date: 2019/9/12 19:35
*/
public abstract class Factory {
public final Product create(String owner){
Product p = createProducer(owner);
registerProduct(p);
return p;
}
// 创建一个汽车
protected abstract Product createProducer(String owner);
// 根据不同配件类型注册汽车产品
protected abstract void registerProduct(Product product);
}
/**
* @Description : 一个汽车产品
* @Author: Liruilong
* @Date: 2019/9/12 19:35
*/
public class Car extends Product {
private String owner;
Car(String owner){
System.out.println("制作"+owner+"类型的汽车");
this.owner = owner;
}
@Override
public void use() {
System.out.println("使用"+owner+"汽车。");
}
public String getOwner(){
return owner;
}
}
/**
* @Description : 构建汽车工厂
* @Author: Liruilong
* @Date: 2019/9/12 19:36
*/
public class CarFactory extends Factory {
private List owners = new ArrayList();
// 生产owner产品
@Override
protected Product createProducer(String owner) {
return new Car(owner);
}
// 注册owner产品
@Override
protected void registerProduct(Product producer) {
owners.add(((Car)producer).getOwner());
}
public List getOwners(){
return owners;
}
}
/**
* @Description : 使用
* @Author: Liruilong
* @Date: 2019/9/12 20:45
*/
public class Main {
public static void main(String[] args) {
Factory factory = new CarFactory();
Product product = factory.create("汽车1");
Product product1 = factory.create("汽车2");
Product product2 = factory.create("汽车3");
Product product3 = factory.create("汽车4");
product.use();
product1.use();
product2.use();
product3.use();
}
}
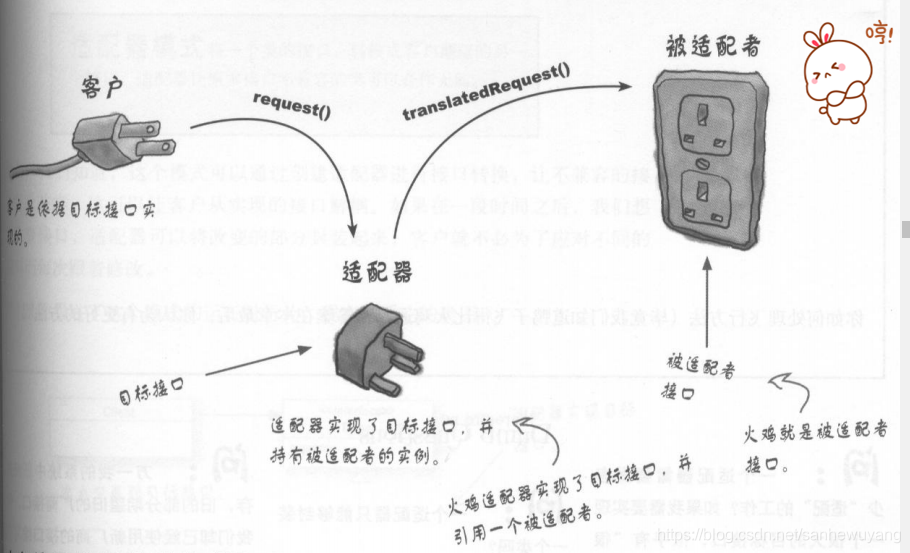
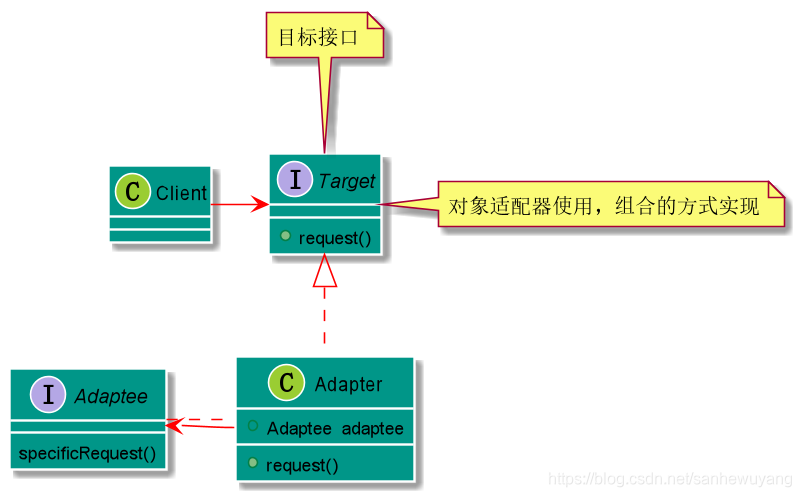
适配器模式将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。在实际情况和需求之间,填补两者之间的差异的设计模式,即将一个类的接口转换为客户期望的另一个接口,
适配器有两种:类适配器模式(使用继承的适配器)和对象适配器模式(使用委托的适配器).
- 类适配器模式:使用继承,即适配器继承于被适配者,实现了需求对象接口,可以理解为需求对象接口将需求告诉适配器(实现了接口方法),适配器对被适配者进行加工,然后满足客户需求.
- 对象适配器模式:使用委托,适配器继承了需求抽象类,与被适配者为聚合关系.可以理解需求对象抽象类将需求告诉适配器(实现了抽象类方法),适配器委托被适配者进行加工.然后满足客户需求.
情境:对于策略模式中使用的鸭子,当我们需要一只鸭子的时候,使用鸭子的接口实现一只火鸡的,这样火鸡看上来就是一只鸭子,

package headfirst.designpatterns.adapter.ducks;
public class TurkeyAdapter implements Duck {
Turkey turkey;
public TurkeyAdapter(Turkey turkey) {
this.turkey = turkey;
}
public void quack() {
turkey.gobble();
}
public void fly() {
for(int i=0; i < 5; i++) {
turkey.fly();
}
}
}
package headfirst.designpatterns.adapter.ducks;
public interface Duck {
public void quack();
public void fly();
}
package headfirst.designpatterns.adapter.ducks;
public class TurkeyTestDrive {
public static void main(String[] args) {
MallardDuck duck = new MallardDuck();
Turkey duckAdapter = new DuckAdapter(duck);
for(int i=0;i<10;i++) {
System.out.println("The DuckAdapter says...");
duckAdapter.gobble();
duckAdapter.fly();
}
}
}
同理,将交流的220V的电由ac适配器转换为直流电100v,ac适配器就充当适配角色.
- 客户通过目标接口调用适配器的方法对适配器发出请求。
- 适配器使用
被适配者接口把请求转换成被适配者的一个或多个调用接口。- 客户接收到调用的结果,但并未察觉这一切是适配器在起转换作用。

`问`:一个适配器需要做多少“适配”的工作?如果我需要实现一个很大的目标接口,似乎有“很多”工作要做。
`答`:的que是如此,实现一个造配器所需要进行的工作,的确和目标接口的大小成正比。如果不用适配器,你就必须改写客户端的代码来调用这个新的接口,将会花许多力气来做大量的调查工作和代码改写工作相比之下,`提供一个适配器类,将所有的改变封装在一个类中,是比较好的做法。`
`问`:一个适配器只能够封裝一个类吗?
`答`:追配器模式的工作是得一个接口转换成另一个。虽然大多数的适配器模式所采取的例子都是让一·个适配器包装一个被造配者,但我们都知道这个世界其实复杂多了,所以你可能遇到一些状况,需要让一个适配器包装多个被适配者。这涉及另一个模式,`被称为外观模式(Facade Pattern) ,人们常常将外观模式和适配器模式混为一谈`,本章稍后将对此详细说明。
如果你已经使用过Java,可能记得早期的集合(collection)类型(例如: Vector.Stack, Hashtable)都实现了一个名为.·elements()的方法。该方法会返回一个.Enumeration。这个Enumeration接口可以逐一走过此集合内的每个元素,而无需知道它们在集合内是如何被管理的。
当Sun推出更新后的集合类时,开始使用了Iterator (迭代器)接口,这个接口和枚举接·口很像,都可以让你遍历此集合类型内的每个元素,但不同的是,迭代器还提供了删除元素的能力。
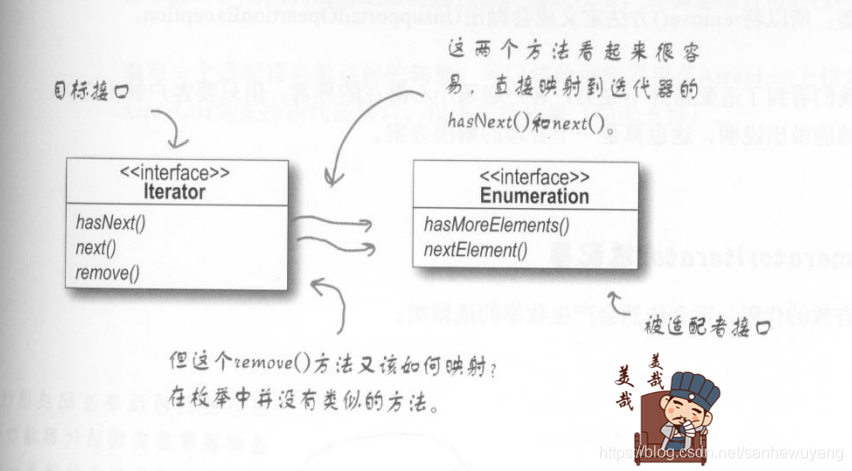
我们需要一个适配器,实现了目标接口,而此目标接口是由被适配接口组合的,hasNext()和next()方法很容易实现,直接把它们从目标对应到适配者就可以了,但是对于remove)方法,我们又该怎么办?
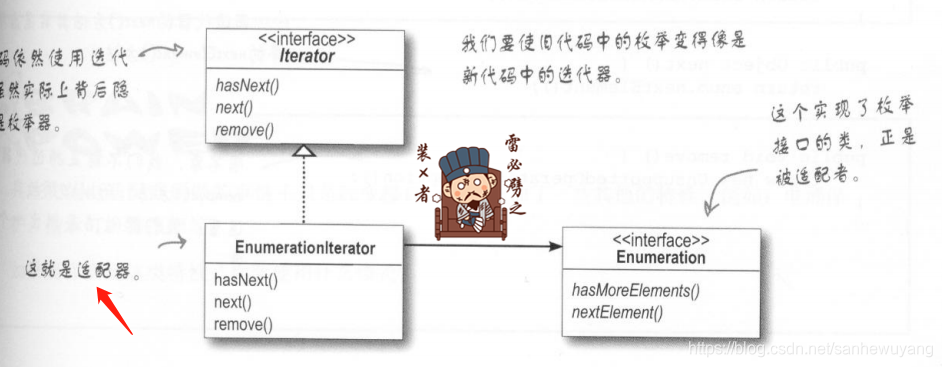
package headfirst.designpatterns.adapter.iterenum;
import java.util.*;
public class EnumerationIterator implements Iterator<Object> {
Enumeration<?> enumeration;
public EnumerationIterator(Enumeration<?> enumeration) {
this.enumeration = enumeration;
}
public boolean hasNext() {
return enumeration.hasMoreElements();
}
public Object next() {
return enumeration.nextElement();
}
public void remove() {
throw new UnsupportedOperationException();
}
}
类适配器和对象适配器有不同的权衡。
类适配器:用一个具体的Adapter类对Adaptee和Target进行匹配。结果是当我们想要匹配一个类以及所有它的子类时,类Adapter将不能胜任工作。使得Adapter可以重定义Adaptee的部分行为,因为Adapter是Adaptee的一个子类。仅仅引入了一个对象,并不需要额外的指针以间接得到adaptee。对象适配器则:允许一个Adapter与多个Adaptee-即Adaptee本身以及它的所有子类(如果有子类的话)一同时工作。Adapter也可以一次给所有的Adaptee添加功能。使得重定义Adaptee的行为比较困难。这就需要生成Adaptee的子类并且使得Adapter引用这个子类而不是引用Adaptee本身。
使用Adapter模式时需要考虑的其他一些因素有:
- 1)
Adapter的匹配程度对Adaptee的接口与Target的接口进行匹配的工作量各个Adapter可能不一样。工作范围可能是,从简单的接口转换(例如改变操作名)到支持完全不同的操作集合。Adapter的工作量取决于Target接口与Adaptee接口的相似程度。 - 2)
可插入的Adapter当其他的类使用一个类时,如果所需的假定条件越少,这个类就更具可复用性。如果将接口匹配构建为一个类,就不需要假定对其他的类可见的是一个相同的接口。也就是说,接口匹配使得我们可以将自己的类加入到一些现有的系统中去,而这些系统对这个类的接口可能会有所不同。Object-Work/Smalltalk(Par90]使用pluggable adapter-词描述那些具有内部接口适配的类。
- 3)
使用双向适配器提供透明操作使用适配器的一个潜在问题是,它们不对所有的客户都透明。被适配的对象不再兼容Adaptee的接口,因此并不是所有Adaptee对象可以被使用的


外观模式隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。这种模式涉及到一个单一的类,该类提供了客户端请求的简化方法和对现有系统类方法的委托调用。
意图:为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。主要解决:降低访问复杂系统的内部子系统时的复杂度,简化客户端与之的接口。何时使用: 1、客户端不需要知道系统内部的复杂联系,整个系统只需提供一个"接待员"即可。 2、定义系统的入口。如何解决:客户端不与系统耦合,外观类与系统耦合。关键代码:在客户端和复杂系统之间再加一层,这一层将调用顺序、依赖关系等处理好。应用实例: 1、去医院看病,可能要去挂号、门诊、划价、取药,让患者或患者家属觉得很复杂,如果有提供接待人员,只让接待人员来处理,就很方便。 2、winOS 的图形化界面和linuxOS的命令行方式,使用linuxOS分盘需要分区,格式化,挂载,而使用winOS快捷键只需要一步就可以。优点: 1、减少系统相互依赖。 2、提高灵活性。 3、提高了安全性。缺点:不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。使用场景: 1、为复杂的模块或子系统提供外界访问的模块。 2、子系统相对独立。 3、预防低水平人员带来的风险。注意事项:在层次化结构中,可以使用外观模式定义系统中每一层的入口。情境:家庭影院在播放电影的时候需要操作很多的设备,繁琐的很,这时候想通过遥控器来调用这些所有的设备开始工作,遥控器就可以看做是其他设备的一个外观样子,这种行为称为外观模式。


源代码设备接口很多,这里仅摘部分。
package headfirst.designpatterns.facade.hometheater;
public class HomeTheaterFacade {
Amplifier amp;
Tuner tuner;
StreamingPlayer player;
CdPlayer cd;
Projector projector;
TheaterLights lights;
Screen screen;
PopcornPopper popper;
public HomeTheaterFacade(Amplifier amp,
Tuner tuner,
StreamingPlayer player,
Projector projector,
Screen screen,
TheaterLights lights,
PopcornPopper popper) {
this.amp = amp;
this.tuner = tuner;
this.player = player;
this.projector = projector;
this.screen = screen;
this.lights = lights;
this.popper = popper;
}
public void watchMovie(String movie) {
System.out.println("Get ready to watch a movie...");
popper.on();
popper.pop();
lights.dim(10);
screen.down();
projector.on();
projector.wideScreenMode();
amp.on();
amp.setStreamingPlayer(player);
amp.setSurroundSound();
amp.setVolume(5);
player.on();
player.play(movie);
}
public void endMovie() {
System.out.println("Shutting movie theater down...");
popper.off();
lights.on();
screen.up();
projector.off();
amp.off();
player.stop();
player.off();
}
public void listenToRadio(double frequency) {
System.out.println("Tuning in the airwaves...");
tuner.on();
tuner.setFrequency(frequency);
amp.on();
amp.setVolume(5);
amp.setTuner(tuner);
}
public void endRadio() {
System.out.println("Shutting down the tuner...");
tuner.off();
amp.off();
}
}
package headfirst.designpatterns.facade.hometheater;
public class Amplifier {
String description;
Tuner tuner;
StreamingPlayer player;
public Amplifier(String description) {
this.description = description;
}
public void on() {
System.out.println(description + " on");
}
public void off() {
System.out.println(description + " off");
}
public void setStereoSound() {
System.out.println(description + " stereo mode on");
}
public void setSurroundSound() {
System.out.println(description + " surround sound on (5 speakers, 1 subwoofer)");
}
public void setVolume(int level) {
System.out.println(description + " setting volume to " + level);
}
public void setTuner(Tuner tuner) {
System.out.println(description + " setting tuner to " + player);
this.tuner = tuner;
}
public void setStreamingPlayer(StreamingPlayer player) {
System.out.println(description + " setting Streaming player to " + player);
this.player = player;
}
public String toString() {
return description;
}
}
外观不只是简化了接口,也将客户从组件的子系统中解耦。外观和适配器可以包装许多类但是外观的意图是简化接口,而适配器的意图是将接口转换成不同接口。
最少知识(Least Knowledge)原则告诉我们要减少对象之间的交互,只留下几个“密友” 。这个原则通常是这么说的:设计原则,最少知识原则:只和你的密友谈话。

究竟要怎样才能避免这样呢?这个原则提供了一些方针:就·任何对象而言·,在该对象的方法内,我们只应该调用属干以下范围的方法;
- 该对象本身
- 被当做方法的参数而传递进来的对象
- 此方法所创建或实例化的任何对象
- 对象的任何组件
这听起来有点严厉,不是吗?如果调用从另一个调用中返回的对象的方法,会有什么害处呢?
如果我们这样做,相当于向另一个对象的子部分发请求(而增加我们直接认识·的对象数目)。在这种情况下,原则要我们改为要求该对象为我们做出请求,这么一来,我们就不需要认识该对象的组件了(让我们的朋友圈子维持在最小的状态)。比方说:


Facade模式有下面一些优点:
- 1)它对
客户屏蔽子系统组件,因而减少了客户处理的对象的数目并使得子系统使用起来更加方便。- 2)
它实现了子系统与客户之间的松耦合关系,而子系统内部的功能组件往往是紧耦合的。松耦合关系使得子系统的组件变化不会影响到它的客户。Facade模式有助于建立层次结构系统,也有助于对对象之间的依赖关系分层。Facade模式可以消除复杂的循环依赖关系。这一点在客户程序与子系统是分别实现的时候尤为重要。
在大型软件系统中降低编译依赖性至关重要。在子系统类改变时,希望尽量减少重编译工作以节省时间。用Facade可以降低编译依赖性,限制重要系统中较小的变化所需的重编译工作。Facade模式同样也有利于简化系统在不同平台之间的移植过程,因为编译一个子系统一般不需要编译所有其他的子系统。???不理解這個- 3)如果应用需要,它并不限制它们使用子系统类。因此你可以在系统易用性和通用性之间加以选择。

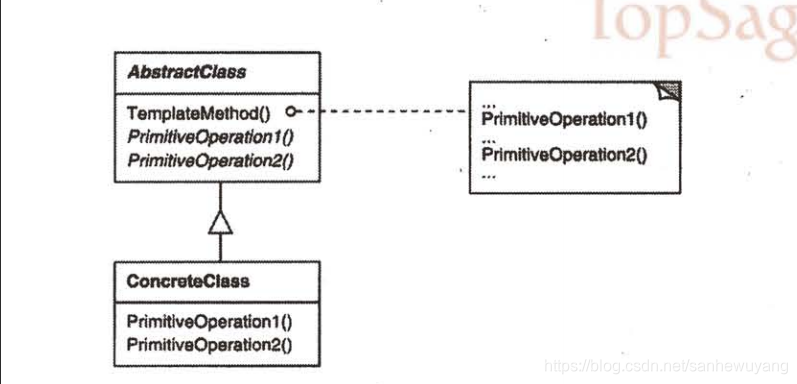
模板方法定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。TemplateMethod使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。定义了一个算法的步骤,并允许子类为一个或多个步骤提供实现。
模板方法可以使得子类在不改变算法算法结构的情况下,重新定义算法中的某些步骤.Thread类中,start方法就是一种模板方法模式的应用,对于不同的实现,有不同的run()方法.
我们看一个简单一点的:
/**
* @Author Liruilong
* @Description 模板方法
* 需要采用某个算法框架,但同时有希望有一定的灵活度
* Thread类的start方法和run方法就是模板方法的体现
* start方法确定算法框架,run方法确定对算法中一部分内容的更改.
* @Date 7:41 2019/9/5
**/
class TemplateMethod {
/**
* @return void
* @Author Liruilong
* @Description 模板方法,确定算法结构代码,类似与start方法。
* @Date 22:28 2019/7/15
* @Param [message]
**/
public final void print(String message) {
System.out.println("&&&&&&&&&&&&&&&&&&");
wrapPrint(message);
System.out.println("&&&&&&&&&&&&&&&&&&");
}
/**
* @Author Liruilong
* @Description 模板方法,确定算法结构代码,类似与start方法。
* 这里 为了是用Lambda把参数行为化,传入了一个函数式接口
* @Date 9:41 2019/9/5
* @Param [message, wrapPrint]
* @return void
**/
public final void print(String message,WrapPrint wrapPrint ) {
System.out.println("&&&&&&&&&&&&&&&&&&");
wrapPrint.wrapPrint(message);
System.out.println("&&&&&&&&&&&&&&&&&&");
}
/**
* @Author Liruilong
* @Description 子类方法,重写实现逻辑细节。类似与run() Method
* @Date 22:29 2019/7/15
* @Param [message]
* @return void
**/
public void wrapPrint(String message) {}
}
@FunctionalInterface
interface WrapPrint{
void wrapPrint(String message);
}
package com.liruilong.design_pattern.TemplaterMethod;
public class TemplateMethods {
public static void main(String[] args) {
// 不使用lambda表达式
TemplateMethod templateMethod = new TemplateMethod() {
@Override
public void wrapPrint(String message) {
System.out.println("@ " + message + " @");
}
};
templateMethod.print("Hello Thread");
TemplateMethod templateMethod1 = new TemplateMethod() {
@Override
public void wrapPrint(String message) {
System.out.println("$ " + message + " $");
}
};
templateMethod1.print("Hello Thread");
// 使用Lambda表达式
new TemplateMethod().print("",(message) ->System.out.println("@ " + message + " @"));
}
}
这个模式是用来创建一个算法的模板。什么是模板?如你所见的,模板就是一个方法。更具体地说,这个方法将算法定义成一组步骤,其中的任何步骤都可以是抽象的,由子类负责实现。这可以确保算法的结构保持不变,同时由子类是供部分实现。

钩子是一种被声明在抽象类中的方法,但只有空的或者默认的实现。钩子的存在,可以让子类有能力对算法的不同点进行挂·钩。要不要挂钩,由子类自行决定。钩子有好几种用途,让我们先看其中一个,稍后再看其他几个:

好菜坞原则可以给我们一种防止“依赖腐败”的方法。当高层组件依赖低层组件,而低层组件又依赖高层组件,而高层组件又依赖边侧组件,而边侧组件又依赖低层组件时,依赖腐败就发生了。在这种情况下,没有人可以轻易地搞懂系统是如何设计的。在好莱坞原则之下,我们允许低层组件将自己挂钩到系统上,但是高层组件会决定什么时候和怎样使用这些低层组件。换句话说,高层组件对待低层组件的方式是“别调用我们,我们会调用你,你只要告诉我需要调用的信号,具体怎么调用不用你来操作。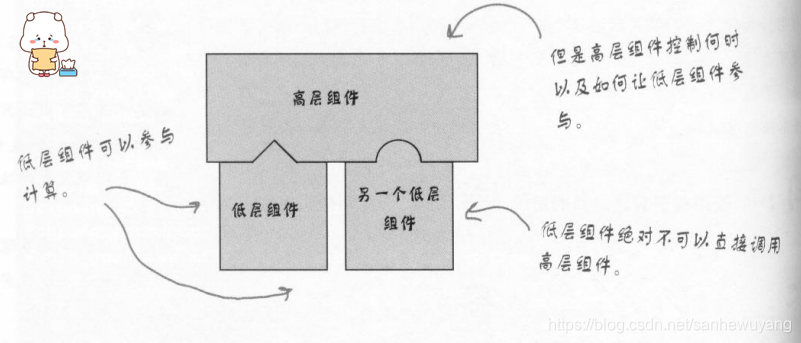
问: 好莱坞原则和依赖倒置原则之间的关系如何?
答:依赖倒置原则教我们尽量避免使用具体类,而多使用抽象。而好莱坞原则是用在创建框架或组件上的一种技巧,好让低层组件能够被挂钩进计算中,而且又不会让高层组件依赖低层组件。两者的目标都是在于解耦,但是依赖倒置原则更加注重如何在设计中避免依赖 。好莱坞原则教我们一个技巧,创建一个有弹性的设计,允许低层结构能够互相操作,而又防止其他类太过依赖它们。
问:低层组件不可以调用层组件中的方法吗?
答:并不尽想。事实上虽层组件在结束时,常常会调用从超类中继承来的方法。我们所要做的是,避免让高层和低层组件之间有明显的环状依赖。
嘻嘻,好激动,我们又要看源码啦!!额…java的水太深啦,啥都看不懂…
/*
* Sorting of complex type arrays. todo 复杂类型数组的排序。
*/
/**
* 可以选择旧的合并排序实现(用于
* 与破比较器的兼容性)使用一个系统属性。
* 在封闭类中不能是静态布尔值,因为
* 循环依赖。将在未来的版本中删除。
*/
static final class LegacyMergeSort {
// AccessController.doPrivileged:不用做权限检查. jar中如果读取文件的方法是通过doPrivileged
private static final boolean userRequested =java.security.AccessController.doPrivileged(
new sun.security.action.GetBooleanAction("java.util.Arrays.useLegacyMergeSort")).booleanValue();
}
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
/** To be removed in a future release. 遗留的归并排序 */
private static void legacyMergeSort(Object[] a) {
// 数组拷贝,同时传入mesgeSort()方法当做目标数组,同时传入目标数组。还包括数组的长度
Object[] aux = a.clone();
mergeSort(aux, a, 0, a.length, 0);
}
/** 具体的排序算法
* mergeSort方法中包含排序算法,
* 此算法依赖于ComparableTo()方法的实现来完成算法
* mergeSort即为一个模板方法
* Comparable.compareTo()为具体的比较算法,即模板方法中需要填补的东西。
*/
@SuppressWarnings({"unchecked", "rawtypes"})
private static void mergeSort(Object[] src,
Object[] dest,
int low,
int high,
int off) {
int length = high - low;
// Insertion sort on smallest arrays
if (length < INSERTIONSORT_THRESHOLD) {
for (int i=low; i<high; i++)
for (int j=i; j>low &&
((Comparable) dest[j-1]).compareTo(dest[j])>0; j--)
swap(dest, j, j-1);
return;
}
// Recursively sort halves of dest into src
int destLow = low;
int destHigh = high;
low += off;
high += off;
int mid = (low + high) >>> 1;
mergeSort(dest, src, low, mid, -off);
mergeSort(dest, src, mid, high, -off);
// If list is already sorted, just copy from src to dest. This is an
// optimization that results in faster sorts for nearly ordered lists.
//如果已经排序,直接进行数组的拷贝
if (((Comparable)src[mid-1]).compareTo(src[mid]) <= 0) {
System.arraycopy(src, low, dest, destLow, length);
return;
}
// Merge sorted halves (now in src) into dest 合并排序的一半(现在在src)到dest
//
for(int i = destLow, p = low, q = mid; i < destHigh; i++) {
if (q >= high || p < mid && ((Comparable)src[p]).compareTo(src[q])<=0)
dest[i] = src[p++];
else
dest[i] = src[q++];
}
}
/*
* @since 1.8
*/
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen) {
assert a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi);
binarySort(a, lo, hi, lo + initRunLen);
return;
}
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*/
ComparableTimSort ts = new ComparableTimSort(a, work, workBase, workLen);
int minRun = minRunLength(nRemaining);
do {
// Identify next run
int runLen = countRunAndMakeAscending(a, lo, hi);
// If run is short, extend to min(minRun, nRemaining)
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
ts.pushRun(lo, runLen);
ts.mergeCollapse();
// Advance to find next run
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
String[] strings = new String[]{"123","234","546","56657","567"};
Arrays.sort(strings);
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
模板方法是一种代码复用的基本技术。它们在类库中尤为重要,它们提取了类库中的公共行为。
模板方法导致一种反向的控制结构,这种结构有时被称为“好莱坞法则”,即“别找我们,我们找你”。这指的是一个父类调用一个子类的操作,而不是相反。模板方法调用下列类型的操作:,
- 具体的操作(ConcreteClass或对客户类的操作)。
- 具体的AbstractClass的操作(即,通常对子类有用的操作)。
- 原语操作(即,抽象操作)。
- Factory Method (见Factory Method (3.5)。
- 钩子操作( hook operations ),它提供了缺省的行为,子类可以在必要时进行扩展。一个钩子操作在缺省操作通常是一个空操作。
很重要的一点是模板方法应该指明哪些操作是钩子操作(可以被重定义)以及哪些是抽象操作(必须被重定义),要有效地重用一个抽象类,子类编写者必须明确了解哪些操作是设计为有待重定义的。子类可以通过
重定义父类的操作来扩展该操作的行为,其间可显式地调用父类操作。不幸的是,人们很容易忘记去调用被继承的行为。我们可以将这样一个操作转换为一个模板方法,以使得父类可以对子类的扩展方式进行控制。也就是,在父类的模板方法中调用钩子操作。子类可以重定义这个钩子操作:**

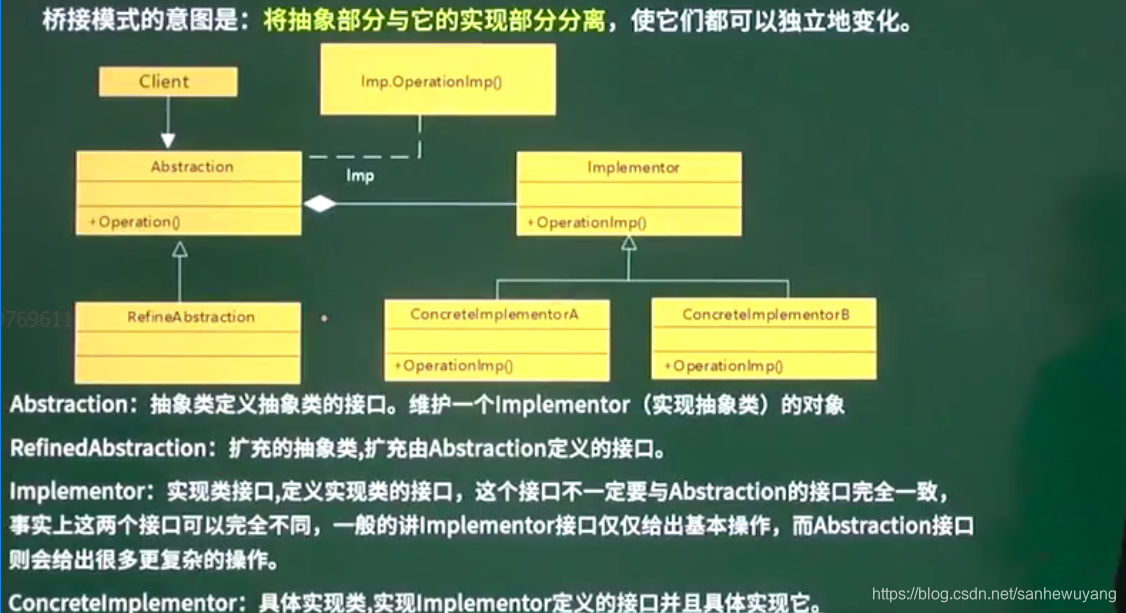
桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。与策略模式类似,所以本书里没有这个模式
这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类。这两种类型的类可被结构化改变而互不影响。
情景: 1、如果一个系统需要在
构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。 2、对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。 3、一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。意图:将抽象部分与实现部分分离,使它们都可以独立的变化。主要解决:在有多种可能会变化的情况下,用继承会造成类爆炸问题,扩展起来不灵活。何时使用:实现系统可能有多个角度分类,每一种角度都可能变化。如何解决:把这种多角度分类分离出来,让它们独立变化,减少它们之间耦合。关键代码:抽象类依赖实现类。
应用实例: 1、猪八戒从天蓬元帅转世投胎到猪,转世投胎的机制将尘世划分为两个等级,即:灵魂和肉体,前者相当于抽象化,后者相当于实现化。生灵通过功能的委派,调用肉体对象的功能,使得生灵可以动态地选择。 2、墙上的开关,可以看到的开关是抽象的,不用管里面具体怎么实现的。
优点:1、抽象和实现的分离。 2、优秀的扩展能力。 3、实现细节对客户透明。缺点:桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。
我们通过下面的实例来演示桥接模式(Bridge Pattern)的用法。其中,可以使用相同的抽象类方法但是不同的桥接实现类,来画出不同颜色的圆。
注意事项:对于两个独立变化的维度,使用桥接模式再适合不过了。
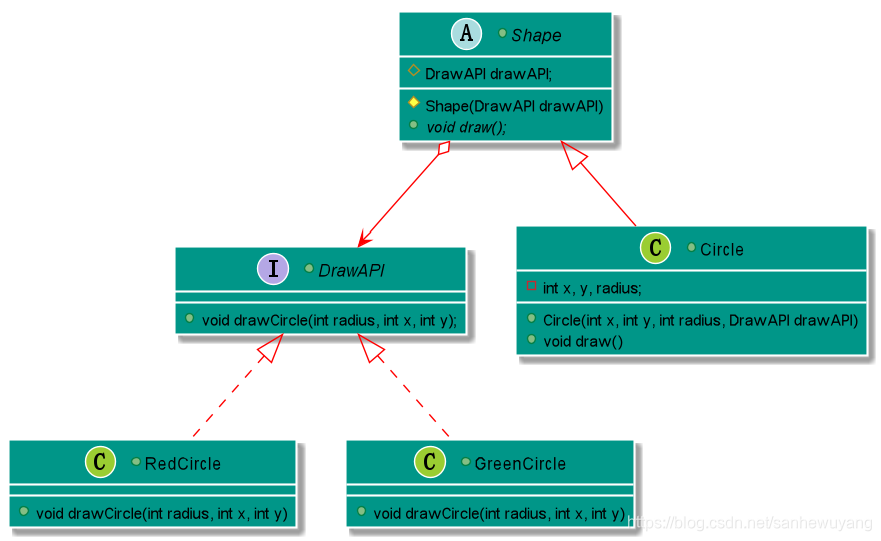
public interface DrawAPI {
public void drawCircle(int radius, int x, int y);
}
public class RedCircle implements DrawAPI {
@Override
public void drawCircle(int radius, int x, int y) {
System.out.println("Drawing Circle[ color: red, radius: "
+ radius +", x: " +x+", "+ y +"]");
}
}
public class GreenCircle implements DrawAPI {
@Override
public void drawCircle(int radius, int x, int y) {
System.out.println("Drawing Circle[ color: green, radius: "
+ radius +", x: " +x+", "+ y +"]");
}
}
public abstract class Shape {
protected DrawAPI drawAPI;
protected Shape(DrawAPI drawAPI){
this.drawAPI = drawAPI;
}
public abstract void draw();
}
public class Circle extends Shape {
private int x, y, radius;
public Circle(int x, int y, int radius, DrawAPI drawAPI) {
super(drawAPI);
this.x = x;
this.y = y;
this.radius = radius;
}
public void draw() {
drawAPI.drawCircle(radius,x,y);
}
}
public class BridgePatternDemo {
public static void main(String[] args) {
Shape redCircle = new Circle(100,100, 10, new RedCircle());
Shape greenCircle = new Circle(100,100, 10, new GreenCircle());
redCircle.draw();
greenCircle.draw();
}
}
1)
分离接口及其实现部分: 一个实现未必不变地绑定在一个接口上。抽象类的实现可以在运行时刻进行配置,一个对象甚至可以在运行时刻改变它的实现。将Abstraction与Implementor分离有助于降低对实现部分编译时刻的依赖性,当改变一个实现类时,并不需要重新编译Abstraction类和它的客户程序。为了保证一个类库的不同版本之间的二进制兼容性,一定要有这个性质。另外,接口与实现分离有助于分层,从而产生更好的结构化系统,系统的高层部分仅需知道Abstraction和Implementor即可。
2)提高可扩充性你可以独立地对Abstraction和Implementor层次结构进行扩充。
3)实现细节对客户透明你可以对客户隐藏实现细节,例如共享Implementor对象以及相应的引用计数机制(如果有的话)。

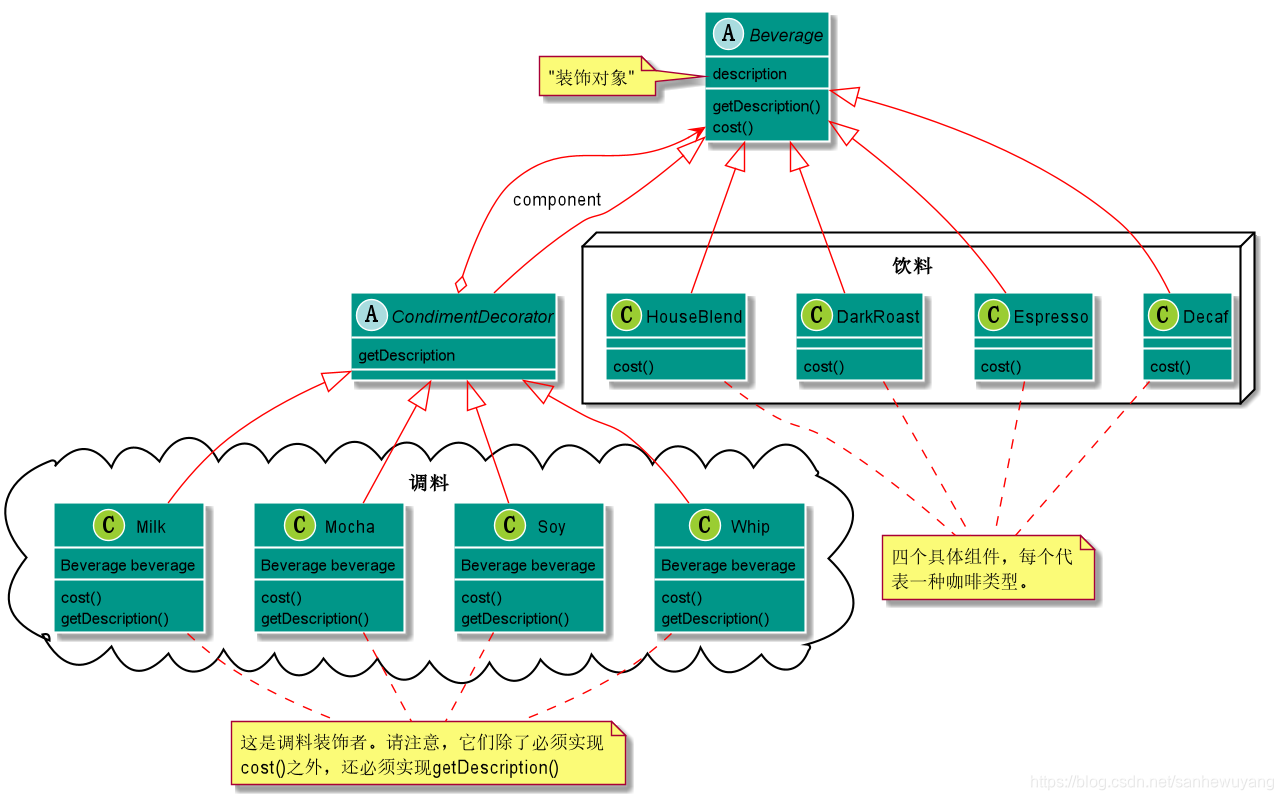
情景:咖啡不同的配料有不同的价格,由于配料繁多,组合不同,价格不同,通过继承的方式会照成
类爆炸,而且后期价格调整,需要修改继承类,维护特别麻烦,同过属性的方式处理,当价格变动,或者对配量有要求时,我们还是需要调整类的结构。特别麻烦,不符合开闭原则。所以在咖啡问题上我们遇到的问题:类数量爆炸、设计死板,以及基类加入的新功能并不适用于所有的子类。,
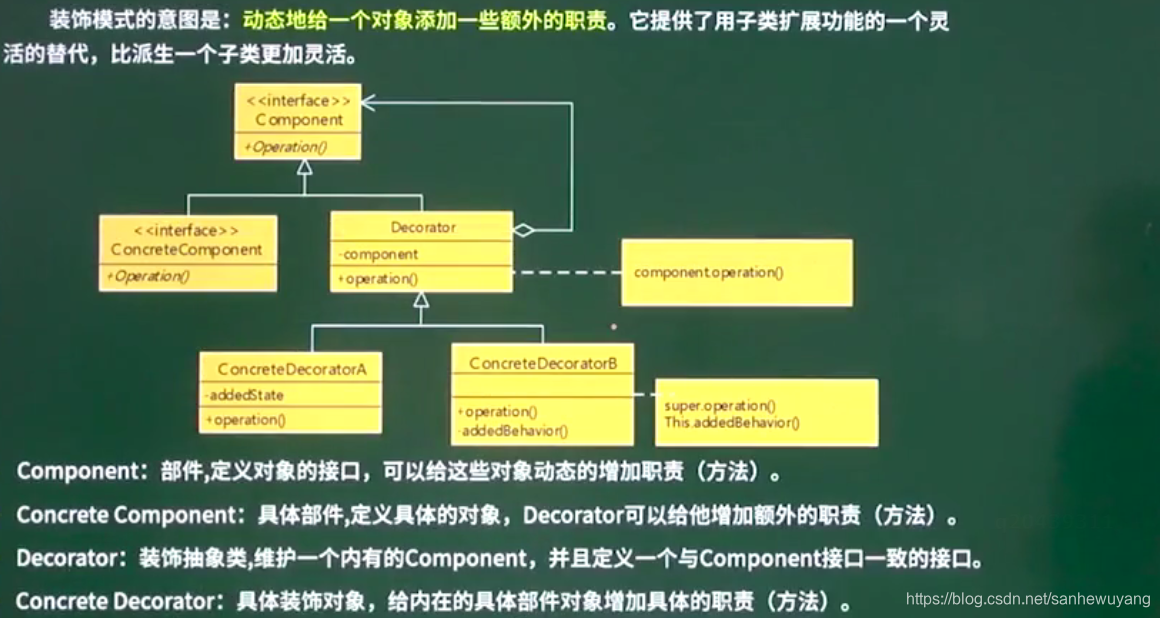
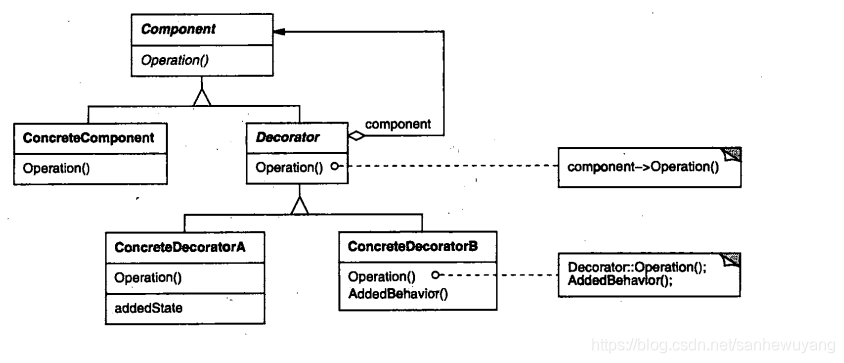
利用组合(composition)和委托(delegation)可以在运行时動態具有继承行为的效果,利用继承设计子类的行为,是在编译时静态决定的,而且所有的子类都会继承到相同的行为。然而,如果能够利用组合的做法扩展对象的行为,就可以在运行时动态地进行扩展。
设计原则:类应该对扩展开放,对修改关闭(开放 -关闭原则)
上面問題换一种思路,我们把变化的部分提出来,我们要以饮料为主体,然后在运行时以调料来“装饰”(decorate)饮料。比方说,如果顾客想要摩卡和奶泡深焙咖啡,那么,要做的是:
1 拿一个咖啡(DarkRoast)对象
2 以摩卡(Mocha)对象装饰它
3 以奶泡(Whip)对象装饰它
4 调用cost()方法,并依赖委托(delegate)将调料的价钱加上去。
装饰者和被装饰对象有相同的超类型。
你可以用一个或多个装饰者包装一个对象。
既然装饰者和被装饰对象有相同的超类型,所以在任何需要原始对象(被包装的)的场合,
可以用装饰过的对象代替它。
装饰者可以在所委托被装饰者的行为之前与/或之后,加上自己的行为,以达到特定的目的。
对象可以在任何时候被装饰,所以可以在运行时动态地、不限量地用你喜欢的装饰者来装饰对象那个咖啡的例子


package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description 被装饰对象(原味咖啡)
* @author Liruilong
* @date 2021/5/13 6:47
**/
public abstract class Beverage {
String description = "Unknown Beverage";
/*
* @return getDescriptiono已经在此实现了,但是cost ()必须在子类中实现。
* @Description
* @author Liruilong
* @date 2021/5/13 6:49
**/
public String getDescription() {
return description;
}
public abstract double cost();
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description DarkRoast饮料。
* @author Liruilong
* @date 2021/5/13 6:51
**/
public class DarkRoast extends Beverage {
public DarkRoast() {
description = "DarkRoast";
}
@Override
public double cost() {
return 0.99;
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description Decaf饮料。
* @author Liruilong
* @date 2021/5/13 6:51
**/
public class Decaf extends Beverage {
public Decaf() {
description = "Decaf";
}
@Override
public double cost() {
return 0.99;
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description 首先,让Espresso扩展自"Beverage类, 因为Espresso是一种饮料。
* @author Liruilong
* @date 2021/5/13 6:51
**/
public class Espresso extends Beverage {
public Espresso() {
description = "Espresso";
}
@Override
public double cost() {
return 1.99;
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description HouseBlend 是饮料。
* @author Liruilong
* @date 2021/5/13 6:51
**/
public class HouseBlend extends Beverage {
public HouseBlend() {
description = "HouseBlend";
}
@Override
public double cost() {
return 0.99;
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description 首先,必须让Condiment Decorator能取代Beverage,所以将CondimentDecorator扩展自Beverage类。
* @author Liruilong
* @date 2021/5/13 6:50
**/
public abstract class CondimentDecorator extends Beverage {
/*
* @return
* @Description 所有的调料装饰者都必须重新实现getDescription()方法。
* @author Liruilong
* @date 2021/5/13 6:50
**/
public abstract String getDescription();
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description 摩卡是一个装饰者,所以让它扩展自CondimentDecorator。
* @author Liruilong
* @date 2021/5/13 7:05
**/
public class Mocha extends CondimentDecorator {
Beverage beverage;
public Mocha(Beverage beverage) {
this.beverage = beverage;
}
@Override
public String getDescription() {
return beverage.getDescription() + ", Mocha";
}
@Override
public double cost() {
return .20 + beverage.cost();
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description Soy是一个装饰者,所以让它扩展自CondimentDecorator。
* @author Liruilong
* @date 2021/5/13 7:05
**/
public class Soy extends CondimentDecorator {
Beverage beverage;
public Soy(Beverage beverage) {
this.beverage = beverage;
}
@Override
public String getDescription() {
return beverage.getDescription() + ", Soy";
}
@Override
public double cost() {
return 5.20 + beverage.cost();
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description Whip是一个装饰者,所以让它扩展自CondimentDecorator。
* @author Liruilong
* @date 2021/5/13 7:05
**/
public class Whip extends CondimentDecorator {
Beverage beverage;
public Whip(Beverage beverage) {
this.beverage = beverage;
}
@Override
public String getDescription() {
return beverage.getDescription() + ", Whip";
}
@Override
public double cost() {
return 45.20 + beverage.cost();
}
}
package com.liruilong.design_pattern.Decorator;
/*
* @return
* @Description test
* @author Liruilong
* @date 2021/5/13 7:08
**/
public class StarbuzzCoffee {
public static void main(String[] args) {
//一杯Espresso,不需要调料,打印出它的描述与价钱。
Beverage beverage = new Espresso();
System.out.println(beverage.getDescription()
+ " $" + beverage.cost());
//双倍Mocha一个Whip
Beverage beverage2 = new DarkRoast();
beverage2 = new Mocha(beverage2);
beverage2 = new Mocha(beverage2);
beverage2 = new Whip(beverage2);
System.out.println(beverage2.getDescription()
+ " $" + beverage2.cost());
//Mocha,Soy,Whip各一份
Beverage beverage3 = new HouseBlend();
beverage3 = new Soy(beverage3);
beverage3 = new Mocha(beverage3);
beverage3 = new Whip(beverage3);
System.out.println(beverage3.getDescription()
+ " $" + beverage3.cost());
}
}
D:\Java\jdk1.8.0_251\bin\java.exe "-javaagent:E:\学习软件\IntelliJ IDEA 2018.3.1\lib\idea_rt.jar=4118:E:\学习软件\IntelliJ IDEA 2018.3.1\bin" -Dfile.encoding=UTF-8 -classpath D:\Java\jdk1.8.0_251\jre\lib\charsets.jar;D:\Java\jdk1.8.0_251\jre\lib\deploy.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\access-bridge-64.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\cldrdata.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\dnsns.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\jaccess.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\jfxrt.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\localedata.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\nashorn.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\sunec.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\sunjce_provider.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\sunmscapi.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\sunpkcs11.jar;D:\Java\jdk1.8.0_251\jre\lib\ext\zipfs.jar;D:\Java\jdk1.8.0_251\jre\lib\javaws.jar;D:\Java\jdk1.8.0_251\jre\lib\jce.jar;D:\Java\jdk1.8.0_251\jre\lib\jfr.jar;D:\Java\jdk1.8.0_251\jre\lib\jfxswt.jar;D:\Java\jdk1.8.0_251\jre\lib\jsse.jar;D:\Java\jdk1.8.0_251\jre\lib\management-agent.jar;D:\Java\jdk1.8.0_251\jre\lib\plugin.jar;D:\Java\jdk1.8.0_251\jre\lib\resources.jar;D:\Java\jdk1.8.0_251\jre\lib\rt.jar;D:\code\workspack\out\production\workspack;D:\code\workspack\lib\cglib-3.2.12.jar;D:\code\workspack\lib\mysql-connector-java-5.1.18-bin.jar com.liruilong.design_pattern.Decorator.StarbuzzCoffee
Espresso $1.99
DarkRoast, Mocha, Mocha, Whip $46.59
HouseBlend, Soy, Mocha, Whip $51.59
Process finished with exit code 0
下面是一个典型的对象集合,用装饰者来将功能结合起来,以读取文件数据,
BufferedInputStream及LineNumberInputStream都扩展自FilterInputStream,而FilterInputStream是一个抽象的装饰类。和咖啡类对一下,发现基本一样。
FilterInputStream是一个抽象装饰者。

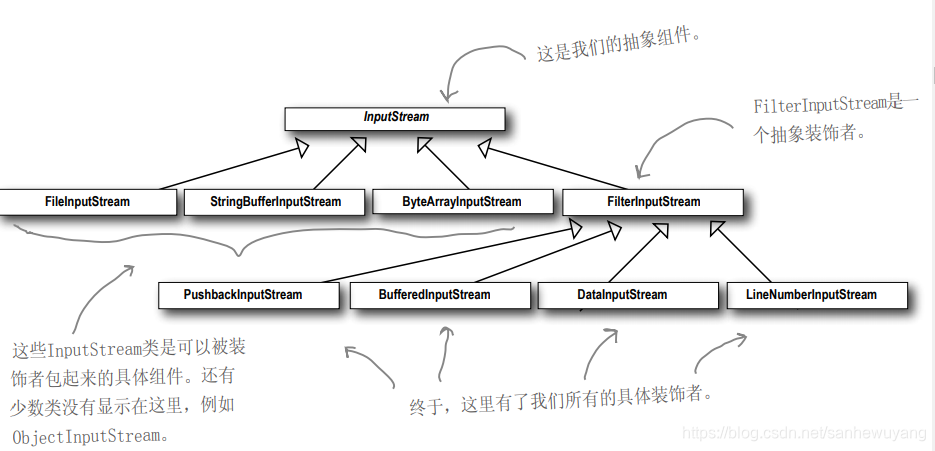
*
* @author Jonathan Payne
* @since JDK1.0
*/
public
class FilterInputStream extends InputStream {
/**
* The input stream to be filtered.
*/
protected volatile InputStream in;
/**
* Creates a <code>FilterInputStream</code>
* by assigning the argument <code>in</code>
* to the field <code>this.in</code> so as
* to remember it for later use.
*
* @param in the underlying input stream, or <code>null</code> if
* this instance is to be created without an underlying stream.
*/
protected FilterInputStream(InputStream in) {
this.in = in;
}
编写一个装饰者,把输入流内的所有大写字符转成小写
package com.liruilong.design_pattern.Decorator;
import java.io.FilterInputStream;
import java.io.IOException;
import java.io.InputStream;
/*
* @return
* @Description 把输入流内的所有大写字符转成小写
* @author Liruilong
* @date 2021/5/13 23:20
**/
public class LowerCaseInputStream extends FilterInputStream {
/**
* Creates a <code>FilterInputStream</code>
* by assigning the argument <code>in</code>
* to the field <code>this.in</code> so as
* to remember it for later use.
*
* @param in the underlying input stream, or <code>null</code> if
* this instance is to be created without an underlying stream.
*/
protected LowerCaseInputStream(InputStream in) {
super(in);
}
@Override
public int read() throws IOException {
int c = super.read();
return c == -1 ? c:Character.toLowerCase((char) c);
}
@Override
public int read(byte[] b) throws IOException {
int c = super.read(b);
for (byte b_ : b) {
b_ = (byte)Character.toLowerCase((char)b_);
}
return c;
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
int result = super.read(b, off, len);
for (int i = off; i < off+result; i++) {
b[i] = (byte)Character.toLowerCase((char)b[i]);
}
return result;
}
}
package com.liruilong.design_pattern.Decorator;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
/*
* @return
* @Description
* @author Liruilong
* @date 2021/5/13 23:35
**/
public class InputTest {
public static void main(String[] args) {
int c;
try (InputStream inputStream = new LowerCaseInputStream(
new BufferedInputStream(new FileInputStream("")))){
while ((c = inputStream.read()) >=0){
System.out.print((char)c);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
- 1)
比静态继承更灵活与对象的静态继承(多重继承)相比, Decorator模式提供了更加灵活的向对象添加职责的方式。可以用添加和分离的方法,用装饰在运行时刻增加和删除职责。相比之下,继承机制要求为每个添加的职责创建一个新的子类(例如, BorderscrollableTextView, BorderedTextView ),这会产生许多新的类,并且会增加系统的复杂度。此外,为一个特定的Component类提供多个不同的Decorator类,这就使得你可以对一些职责进行混合和匹配。使用Decorator模式可以很容易地重复添加一个特性,例如在TextView上添加双边框时,仅需将添加两个BorderDecorator即可。而两次继承Border类则极容易出错的- 2)
避免在层次结构高层的类有太多的特征Decorator模式提供了一种“即用即付”的方法来添加职责。它并不试图在一个复杂的可定制的类中支持所有可预见的特征,相反,你可以定义一个简单的类,并且用Decorator类给它逐渐地添加功能。可以从简单的部件组合出复杂的功能。这样,应用程序不必为不需要的特征付出代价。同时也更易于不依赖于Decorator昕扩展(甚至是不可预知的扩展)的类而独立地定义新类型的Decorator。扩展一个复杂类的时候,很可能会暴露与添加的职责无关的细节。- 3)
Decorator与它的Component不一样Decorator是一个透明的包装。如果我们从对象标识的观点出发,一个被装饰了的组件与这个组件是有差别的,因此,使用装饰时不应该依赖对象标识。- 4)
有许多小对象采用Decorator模式进行系统设计往往会产生许多看上去类似的小对象这些对象仅仅在他们相互连接的方式上有所不同,而不是它们的类或是它们的属性值有所不同。尽管对于那些了解这些系统的人来说,很容易对它们进行定制,但是很难学习这些系统,排错也很困难。
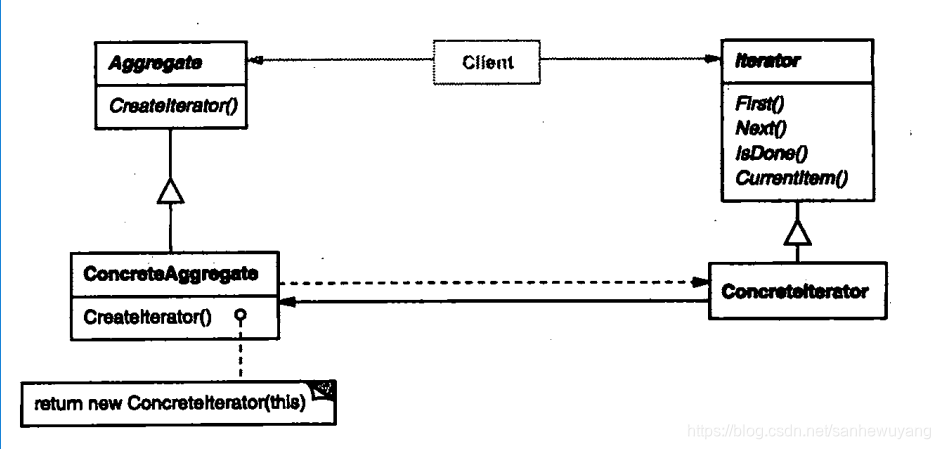
动机:一个聚合对象,如列表(ist),应该提供一种方法来让别人可以访问它的元素,而又不需暴露它的内部结构,此外,针对不同的需要,可能要以不同的方式遍历这个列表。但是即使可以预见到所需的那些遍历操作,你可能也不希望列表的接口中充斥着各种不同遍历的操作。有,时还可能需要在同一个表列上同时进行多个遍历。迭代器模式都可帮你解决所有这些问题。
关键思想是将对列表的访问和遍历从列表对象中分离出来并放入一个迭代器(iterator)对象中。迭代器类定义了一个访问该列表元素的接口。迭代器对象负责跟踪当前的元素;即,它知道哪些元素已经遍历过了。
在实例化列表迭代器之前,必须提供待遍历的列表。一旦有了该列表迭代器的实例,就可以顺序地访问该列表的各个元素。 Currentitem操作返回表列中的当前元素, First操作初始化迭代器,使当前元素指向列表的第一个元素,Next操作将当前元素指针向前推进一步,指向下一个元素,而IsDone检查是否已越过最后一个元素,也就是完成了这次遍历。
将遍历机制与列表对象分离使我们可以定义不同的迭代器来实现不同的遍历策略,而无需在列表接口中列举它们。例如,过滤表列迭代器(FilteringListiterator)可能只访问那些满足特定过滤约束条件的元素。
注意迭代器和列表是耦合在一起的,而且客户对象必须知道遍历的是一个列表而不是其他聚合结构。最好能有一种办法使得不需改变客户代码即可改变该聚合类。可以通过将迭代器的概念推广到
多态迭代(polymorphic iteration)来达到这个目标。
例如,假定我们还有一个列表的特殊实现,比如说SkipList, SkipList是一种具有类似于平衡树性质的随机数据结构。我们希望我们的代码对List和Skiplist对象都适用。首先,定义一个抽象列表类AbstractList,它提供操作列表的公共接口。类似地,我们也需要一个抽象的迭代器类Iterator,它定义公共的迭代接口。然后我们可以为每个不同的列表实现定义具体的Iterator子类。这样迭代机制就与具体的聚合类无关了。
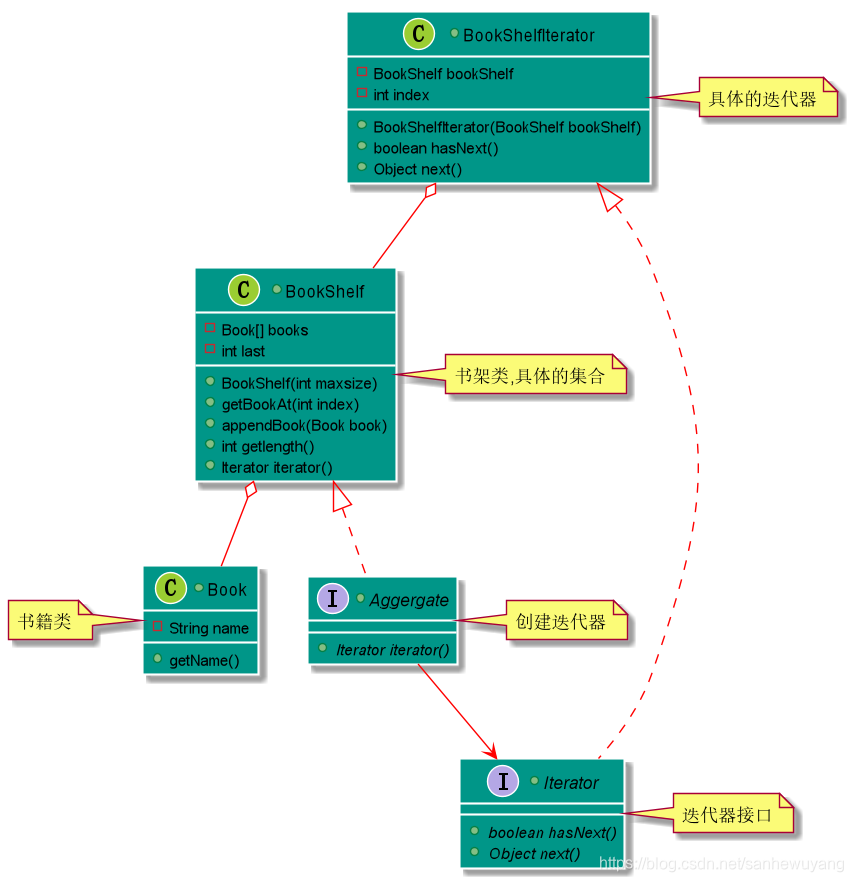
package com.liruilong.design_pattern.Iterator;
/**
* @Description : 遍历集合的接口
* @Author: Liruilong
* @Date: 2019/9/11 0:11
*/
public interface Iterator {
boolean hasNext();
Object next();
}
package com.liruilong.design_pattern.Iterator;
/**
* @Description : 表示集合的接口
* @Author: Liruilong
* @Date: 2019/9/11 0:10
*/
public interface Aggregate {
Iterator iterator();
}
package com.liruilong.design_pattern.Iterator;
/**
* @Description :表示书架的类
* @Author: Liruilong
* @Date: 2019/9/11 0:14
*/
public class BookShelf implements Aggregate {
private Book[] books;
private int last = 0;
// 初始化书架
public BookShelf(int maxsize) {
this.books = new Book[maxsize];
}
// 在书架的最后放入书
public void appendBook(Book book){
this.books[last] = book;
last++;
}
// 获取指定书籍
public Book getBooksAt(int index) {
return books[index];
}
// 获取书架容量
public int getlength() {
return last;
}
@Override
public Iterator iterator() {
return new BooShifkIterator(this);
}
}
package com.liruilong.design_pattern.Iterator;
/**
* @Description : 遍历书籍的类
* @Author: Liruilong
* @Date: 2019/9/11 0:21
*/
public class BooShifkIterator implements Iterator {
private BookShelf bookShelf;
private int index;
public BooShifkIterator(BookShelf bookShelf) {
this.bookShelf = bookShelf;
this.index = 0;
}
@Override
public boolean hasNext() {
if (index < bookShelf.getlength()){
return true;
} else {
return false;
}
}
@Override
public Object next() {
Book book = bookShelf.getBooksAt(index);
index++;
return book;
}
}
package com.liruilong.design_pattern.Iterator;
/**
* @Description :
* @Author: Liruilong
* @Date: 2019/9/11 0:28
*/
public class Main {
public static void main(String[] args) {
BookShelf bookShelf = new BookShelf(4);
bookShelf.appendBook(new Book("1"));
bookShelf.appendBook(new Book("2"));
bookShelf.appendBook(new Book("3"));
bookShelf.appendBook(new Book("4"));
Iterator it = bookShelf.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
设计原则:一个类应该只有一个引起变化的原因
类的每个责任都有改变的潜在区域。超过一个责任,意味着超过一个改变的区域。这个原则告诉我们,尽量让每个类保持单一责任。内聚(cohesion)这个术语你应该听过,它用来度量一个类或模块紧密地达到单一目的或责任。当一个模块或一个类被设计成只支持一组相关的功能时,我们说它具有高内聚;反之,当被设计成支持一组不相关的功能时,我们说它具有低内聚。内聚是一个比单一责任原则更普遍的概念,但两者其实关系是很密切的。遵守这个原则的类容易具有很高的凝聚力,而且比背负许多责任的低内聚类更容易维护。
嘻嘻,是不是发现了简单工厂的影子
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
/**
* Sole constructor. (For invocation by subclass constructors, typically
* implicit.)
*/
protected AbstractList() {
}
//普通的迭代器
public Iterator<E> iterator() {
return new Itr();
}
/**
* {@inheritDoc}
*
* <p>This implementation returns {@code listIterator(0)}.
*
* @see #listIterator(int)
*/
// 其他的迭代器
public ListIterator<E> listIterator() {
return listIterator(0);
}
//这里是通过内部类的方法实现了一个迭代器
private class Itr implements Iterator<E> {
/**
* Index of element to be returned by subsequent call to next.
*/
int cursor = 0;
/**
* Index of element returned by most recent call to next or
* previous. Reset to -1 if this element is deleted by a call
* to remove.
*/
int lastRet = -1;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public E previous() {
checkForComodification();
try {
int i = cursor - 1;
E previous = get(i);
lastRet = cursor = i;
return previous;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.set(lastRet, e);
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
AbstractList.this.add(i, e);
lastRet = -1;
cursor = i + 1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
源码的设计上迭代器是基于ListIterator是一个功能更加强大的, 它继承于Iterator接口,只能用于各种List类型的访问。
- (1)ListIterator有add()方法,可以向List中添加对象,而Iterator不能
- (2)ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
- (3)ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
- (4)都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
public abstract class AbstractCollection<E> implements Collection<E> {
/**
* Sole constructor. (For invocation by subclass constructors, typically
* implicit.)
*/
protected AbstractCollection() {
}
// Query Operations
/**
* Returns an iterator over the elements contained in this collection.
*
* @return an iterator over the elements contained in this collection
*/
public abstract Iterator<E> iterator();
public interface Collection<E> extends Iterable<E> {
......
/**
* Returns an iterator over the elements in this collection. There are no
* guarantees concerning the order in which the elements are returned
* (unless this collection is an instance of some class that provides a
* guarantee).
*
* @return an <tt>Iterator</tt> over the elements in this collection
*/
Iterator<E> iterator();
public interface Iterable<T> {
/**
* Returns an iterator over elements of type {@code T}.
*
* @return an Iterator.
*/
Iterator<T> iterator();
/**
* Performs the given action for each element of the {@code Iterable}
* until all elements have been processed or the action throws an
* exception. Unless otherwise specified by the implementing class,
* actions are performed in the order of iteration (if an iteration order
* is specified). Exceptions thrown by the action are relayed to the
* caller.
*
* @implSpec
* <p>The default implementation behaves as if:
* <pre>{@code
* for (T t : this)
* action.accept(t);
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
/**
* Creates a {@link Spliterator} over the elements described by this
* {@code Iterable}.
*
* @implSpec
* The default implementation creates an
* <em><a href="Spliterator.html#binding">early-binding</a></em>
* spliterator from the iterable's {@code Iterator}. The spliterator
* inherits the <em>fail-fast</em> properties of the iterable's iterator.
*
* @implNote
* The default implementation should usually be overridden. The
* spliterator returned by the default implementation has poor splitting
* capabilities, is unsized, and does not report any spliterator
* characteristics. Implementing classes can nearly always provide a
* better implementation.
*
* @return a {@code Spliterator} over the elements described by this
* {@code Iterable}.
* @since 1.8
*/
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
public interface Iterator<E> {
/**
* Returns {@code true} if the iteration has more elements.
* (In other words, returns {@code true} if {@link #next} would
* return an element rather than throwing an exception.)
*
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
*
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();
/**
* Removes from the underlying collection the last element returned
* by this iterator (optional operation). This method can be called
* only once per call to {@link #next}. The behavior of an iterator
* is unspecified if the underlying collection is modified while the
* iteration is in progress in any way other than by calling this
* method.
*
* @implSpec
* The default implementation throws an instance of
* {@link UnsupportedOperationException} and performs no other action.
*
* @throws UnsupportedOperationException if the {@code remove}
* operation is not supported by this iterator
*
* @throws IllegalStateException if the {@code next} method has not
* yet been called, or the {@code remove} method has already
* been called after the last call to the {@code next}
* method
*/
default void remove() {
throw new UnsupportedOperationException("remove");
}
/**
* Performs the given action for each remaining element until all elements
* have been processed or the action throws an exception. Actions are
* performed in the order of iteration, if that order is specified.
* Exceptions thrown by the action are relayed to the caller.
*
* @implSpec
* <p>The default implementation behaves as if:
* <pre>{@code
* while (hasNext())
* action.accept(next());
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
java5 包含一种新形式的for语句,称为for/in,这可以让你在一个集合或者一个数组中遍历,而且不需要显长的创建迭代器。
迭代器模式有三个重要的作用:
- 1)
它支持以不同的方式遍历一个聚合复杂的聚合可用多种方式进行遍历。例如,代码生成和语义检查要遍历语法分析树。代码生成可以按中序或者按前序来遍历语法分析树。迭代器模式使得改变遍历算法变得很容易:仅需用一个不同的迭代器的实例代替原先的实例即可。你也可以自己定义迭代器的子类以支持新的遍历。- 2)
迭代器简化了聚合的接口有了迭代器的遍历接口,聚合本身就不再需要类似的遍历接口了。这样就简化了聚合的接口。- 3)
在同一个聚合上可以有多个遍历每个迭代器保持它自己的遍历状态。因此你可以同时进行多个遍历。

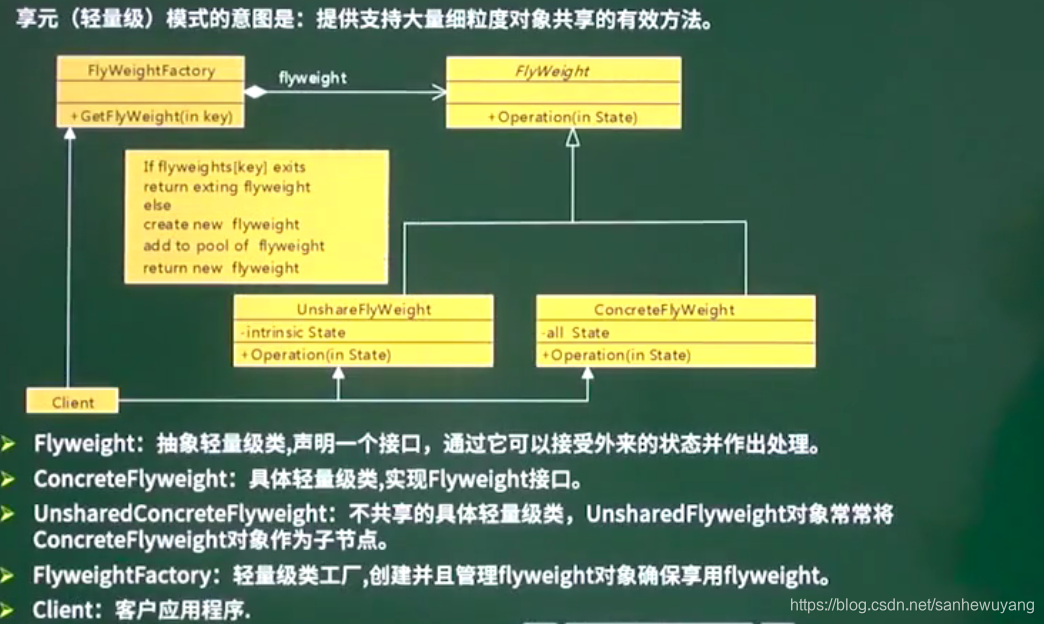
这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。或者可以理解为细粒度的缓存
意图:运用共享技术有效地支持大量细粒度的对象。
主要解决`:在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽象出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
何时使用: 1、系统中有大量对象。 2、这些对象消耗大量内存。 3、这些对象的状态大部分可以外部化。 4、这些对象可以按照内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替。 5、系统不依赖于这些对象身份,这些对象是不可分辨的。
如何解决:用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象关键代码:用 HashMap 存储这些对象。应用实例: 1、JAVA 中的 String,Intege有对应的常量池,如果有则返回,如果没有则创建一个字符串保存在字符串缓存池里面。 2、数据库的数据池。优点:大大减少对象的创建,降低系统的内存,使效率提高。缺点:提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。使用场景: 1、系统有大量相似对象。 2、需要缓冲池的场景。注意事项: 1、注意划分外部状态和内部状态,否则可能会引起线程安全问题。 2、这些类必须有一个工厂对象加以控制。
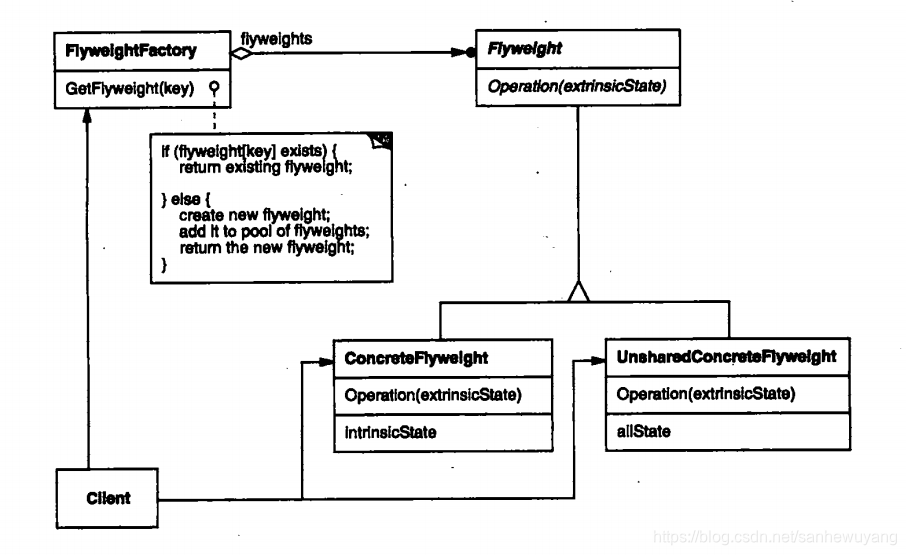
实现:我们将通过创建 5 个对象来画出 20 个分布于不同位置的圆来演示这种模式。由于只有 5 种可用的颜色,所以 color 属性被用来检查现有的 Circle 对象。
创建一个Shape 接口和实现了 Shape 接口的实体类 Circle。下一步是定义工厂类ShapeFactory。
ShapeFactory 有一个Circle 的 HashMap,其中键名为Circle 对象的颜色。无论何时接收到请求,都会创建一个特定颜色的圆。ShapeFactory 检查它的 HashMap 中的circle 对象,如果找到 Circle 对象,则返回该对象,否则将创建一个存储在 hashmap 中以备后续使用的新对象,并把该对象返回到客户端。FlyWeightPatternDemo类使用ShapeFactory来获取Shape对象。它将向ShapeFactory传递信息(red / green / blue/ black / white),以便获取它所需对象的颜色。

public interface Shape {
void draw();
}
public class Circle implements Shape {
private String color;
private int x;
private int y;
private int radius;
public Circle(String color){
this.color = color;
}
public void setX(int x) {
this.x = x;
}
public void setY(int y) {
this.y = y;
}
public void setRadius(int radius) {
this.radius = radius;
}
@Override
public void draw() {
System.out.println("Circle: Draw() [Color : " + color
+", x : " + x +", y :" + y +", radius :" + radius);
}
}
import java.util.HashMap;
public class ShapeFactory {
private static final HashMap<String, Shape> circleMap = new HashMap<>();
public static Shape getCircle(String color) {
Circle circle = (Circle)circleMap.get(color);
if(circle == null) {
circle = new Circle(color);
circleMap.put(color, circle);
System.out.println("Creating circle of color : " + color);
}
return circle;
}
}
public class FlyweightPatternDemo {
private static final String colors[] =
{ "Red", "Green", "Blue", "White", "Black" };
public static void main(String[] args) {
for(int i=0; i < 20; ++i) {
Circle circle =
(Circle)ShapeFactory.getCircle(getRandomColor());
circle.setX(getRandomX());
circle.setY(getRandomY());
circle.setRadius(100);
circle.draw();
}
}
private static String getRandomColor() {
return colors[(int)(Math.random()*colors.length)];
}
private static int getRandomX() {
return (int)(Math.random()*100 );
}
private static int getRandomY() {
return (int)(Math.random()*100);
}
}
使用Flyweigh模式时,传输、查找和/或计算外部状态都会产生运行时的开销,尤其当fyweight原先被存储为内部状态时。然而,空间上的节省抵消了这些开销。共享的nyweight越多,空间节省也就越大
存储节约由以下几个因素决定:
+ 因为共享,实例总数减少的数目·
+ 对象内部状态的平均数目
+ 外部状态是计算的还是存储的
共享的Flyweight越多,存储节约也就越多。节约量随着共享状态的增多而增大。当对象使用大量的内部及外部状态,并且外部状态是计算出来的而非存储的时候,节约量将达到最大。所以,可以用两种方法来节约存储:用共享减少内部状态的消耗,用计算时间换取对外部状态的存储。Flyweight模式经常和Composite 模式结合起来表示一个层次式结构,这一层次式结构是一个共享叶节点的图。共享的结果是, Flyweight的叶节点不能存储指向父节点的指针。而父节点的指针将传给Flyweight作为它的外部状态的一部分。这对于该层次结构中对象之间相互通讯的方式将产生很大的影响。

Flyweight模式经常和Composite 模式结合這快不太懂以後在看????
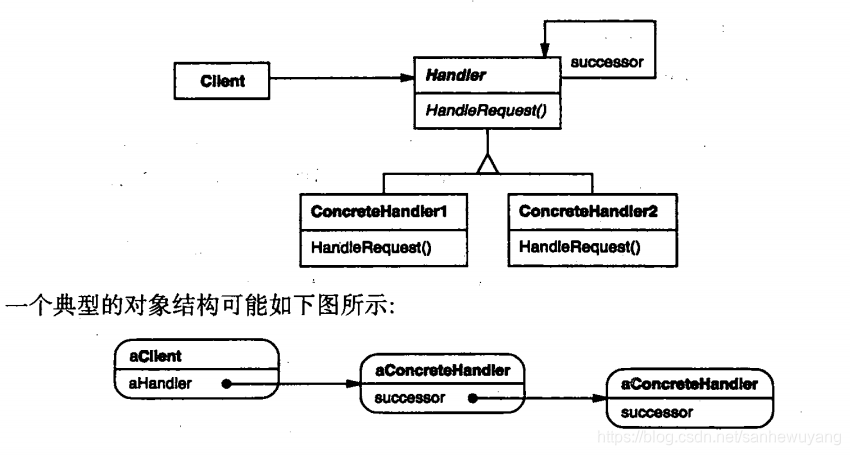
在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。MVC 的异常处理,异常链意图:避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
主要解决:职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。
何时使用:在处理消息的时候以过滤很多道,常用于异常处理,构成异常链。如何解决:拦截的类都实现统一接口。关键代码:Handler 里面聚合它自己,在 HandlerRequest 里判断是否合适,如果没达到条件则向下传递,向谁传递之前 set 进去。应用实例: 1、红楼梦中的"击鼓传花"。 2、JS 中的事件冒泡。 3、JAVA WEB 中 Apache Tomcat 对 Encoding 的处理,Struts2 的拦截器,jsp servlet 的 Filter。使用场景: 1、有多个对象可以处理同一个请求,具体哪个对象处理该请求由运行时刻自动确定。 2、在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。 3、可动态指定一组对象处理请求。
注意事项:在 JAVA WEB 中遇到很多应用。
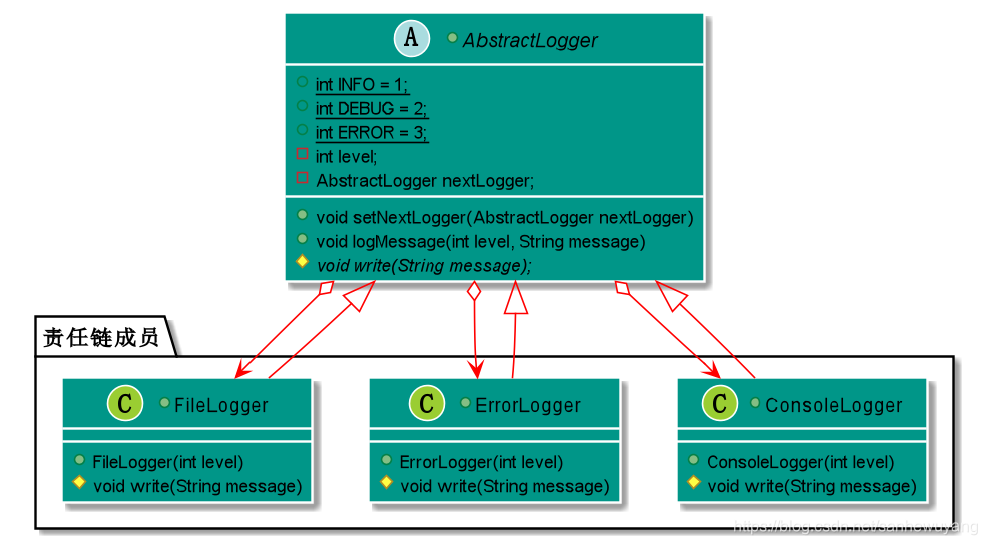
优点: 1、降低耦合度。它将请求的发送者和接收者解耦。 2、简化了对象。使得对象不需要知道链的结构。 3、增强给对象指派职责的灵活性。通过改变链内的成员或者调动它们的次序,允许动态地新增或者删除责任。 4、增加新的请求处理类很方便。缺点: 1、不能保证请求一定被接收。 2、系统性能将受到一定影响,而且在进行代码调试时不太方便,可能会造成循环调用。 3、可能不容易观察运行时的特征,有碍于除错。
public abstract class AbstractLogger {
public static int INFO = 1;
public static int DEBUG = 2;
public static int ERROR = 3;
protected int level;
//责任链中的下一个元素
protected AbstractLogger nextLogger;
public void setNextLogger(AbstractLogger nextLogger){
this.nextLogger = nextLogger;
}
public void logMessage(int level, String message){
if(this.level <= level){
write(message);
}
if(nextLogger !=null){
nextLogger.logMessage(level, message);
}
}
abstract protected void write(String message);
}
public class ConsoleLogger extends AbstractLogger {
public ConsoleLogger(int level){
this.level = level;
}
@Override
protected void write(String message) {
System.out.println("Standard Console::Logger: " + message);
}
}
public class ErrorLogger extends AbstractLogger {
public ErrorLogger(int level){
this.level = level;
}
@Override
protected void write(String message) {
System.out.println("Error Console::Logger: " + message);
}
}
public class FileLogger extends AbstractLogger {
public FileLogger(int level){
this.level = level;
}
@Override
protected void write(String message) {
System.out.println("File::Logger: " + message);
}
}
public class ChainPatternDemo {
private static AbstractLogger getChainOfLoggers(){
AbstractLogger errorLogger = new ErrorLogger(AbstractLogger.ERROR);
AbstractLogger fileLogger = new FileLogger(AbstractLogger.DEBUG);
AbstractLogger consoleLogger = new ConsoleLogger(AbstractLogger.INFO);
errorLogger.setNextLogger(fileLogger);
fileLogger.setNextLogger(consoleLogger);
return errorLogger;
}
public static void main(String[] args) {
AbstractLogger loggerChain = getChainOfLoggers();
loggerChain.logMessage(AbstractLogger.INFO, "This is an information.");
loggerChain.logMessage(AbstractLogger.DEBUG,
"This is a debug level information.");
loggerChain.logMessage(AbstractLogger.ERROR,
"This is an error information.");
}
}
Standard Console::Logger: This is an information.
File::Logger: This is a debug level information.
Standard Console::Logger: This is a debug level information.
Error Console::Logger: This is an error information.
File::Logger: This is an error information.
Standard Console::Logger: This is an error information.
- 1)
降低耦合度该模式使得一个对象无需知道是其他哪一个对象处理其请求。对象仅需知道该请求会被“正确”地处理。接收者和发送者都没有对方的明确的信息,且链中的对象不需知道链的结构。结果是,职责链可简化对象的相互连接。它们仅需保持一个指向其后继者的引用,而不需保持它所有的候选接受者的引用。- 2)
增强了给对象指派职责(Responsibility)的灵活性当在对象中分派职责时,职责链给你更多的灵活性。你可以通过在运行时刻对该链进行动态的增加或修改来增加或改变处理一个请求的那些职责。你可以将这种机制与静态的特例化处理对象的继承机制结合起来使用。- 3)
不保证被接受既然一个请求没有明确的接收者,那么就不能保证它一定会被处理.该请求可能一直到链的末端都得不到处理。一个请求也可能因该链没有被正确配置而得不到处理。

解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
意图:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。主要解决:对于一些固定文法构建一个解释句子的解释器。何时使用:如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。如何解决:构建语法树,定义终结符与非终结符。关键代码:构建环境类,包含解释器之外的一些全局信息,一般是 HashMap。应用实例:编译器、运算表达式计算。优点: 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。缺点: 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。使用场景: 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。 2、一些重复出现的问题可以用一种简单的语言来进行表达。 3、一个简单语法需要解释的场景。
注意事项:可利用场景比较少,JAVA 中如果碰到可以用 expression4J 代替。

实现我们将创建一个接口
Expression和实现了 Expression 接口的实体类。定义作为上下文中主要解释器的TerminalExpression类。其他的类OrExpression、AndExpression用于创建组合式表达式。InterpreterPatternDemo,我们的演示类使用 Expression 类创建规则和演示表达式的解析。
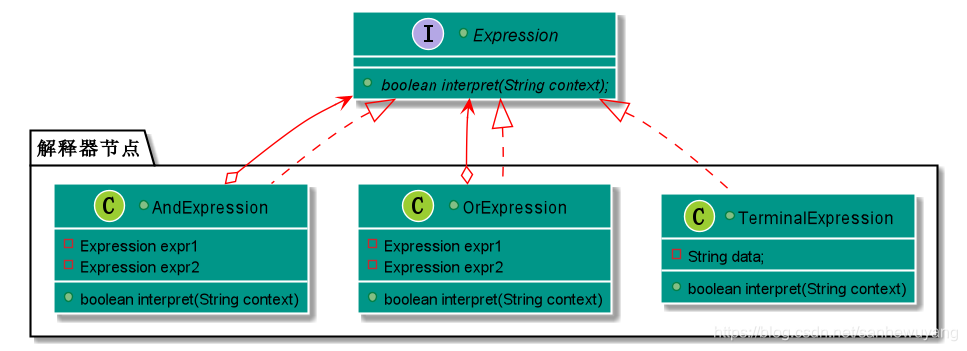

public interface Expression {
public boolean interpret(String context);
}
public class TerminalExpression implements Expression {
private String data;
public TerminalExpression(String data){
this.data = data;
}
@Override
public boolean interpret(String context) {
if(context.contains(data)){
return true;
}
return false;
}
}
public class OrExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public OrExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) || expr2.interpret(context);
}
}
public class AndExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public AndExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) && expr2.interpret(context);
}
}
/**
* @author Liruilong
* @Date 2021-05-14 11:33
* @Description:
*/
public class InterpreterPatternDemo {
//规则:包含字符123或子母abc
public static Expression get_123_abc_Expression(){
Expression number_123 = new TerminalExpression("123");
Expression mother_abc = new TerminalExpression("abc");
return new OrExpression(number_123, mother_abc);
}
//规则:包含符号$$且包含子母abc
public static Expression get_$$_abc_Expression(){
Expression symbol_$$ = new TerminalExpression("$$");
Expression mother_abc = new TerminalExpression("abc");
return new AndExpression(symbol_$$, mother_abc);
}
//规则:包含 (符号$$或者包含子母abc) 且 包含(包含字符123和子母abc)
public static Expression get_123_abc__$$_abc_Expression_And(){
Expression isMale = get_123_abc_Expression();
Expression isMarriedWoman = get_$$_abc_Expression();
return new AndExpression(isMale, isMarriedWoman);
}
//规则:包含 (符号$$或者包含子母abc) 或 包含(包含字符123和子母abc)
public static Expression get_123_abc__$$_abc_Expression_Or(){
Expression isMale = get_123_abc_Expression();
Expression isMarriedWoman = get_$$_abc_Expression();
return new OrExpression(isMale, isMarriedWoman);
}
public static void main(String[] args) {
Expression is_123_abc_ = get_123_abc_Expression();
Expression is_$$_abc_ = get_$$_abc_Expression();
Expression is_123_abc__$$_abc_And = get_123_abc__$$_abc_Expression_And();
Expression is_123_abc__$$_abc__Or = get_123_abc__$$_abc_Expression_Or();
System.out.println("包含字符123 || abc ? " + is_123_abc_.interpret("123"));
System.out.println("包含字符123 && abc ? " + is_$$_abc_.interpret("$$"));
System.out.println("包含字符123 && abc ? " + is_$$_abc_.interpret("$$abc"));
System.out.println(is_123_abc__$$_abc_And.interpret("123"));
System.out.println(is_123_abc__$$_abc__Or.interpret("123"));
}
}
包含字符123 || abc ? true
包含字符123 && abc ? false
包含字符123 && abc ? true
false
true
解释器模式有下列的优点和不足:
1)
易于改变和扩展文法因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。已有的表达式可被增量式地改变,而新的表达式可定义为旧表达式的变体。
2)也易于实现文法定义抽象语法树中各个节点的类的实现大体类似。这些类易于直接编写,通常它们也可用一个编译器或语法分析程序生成器自动生成。
3)复杂的文法难以维护解释器模式为文法中的每一条规则至少定义了一个类(使用BNF定义的文法规则需要更多的类)。因此包含许多规则的文法可能难以管理和维护。可应用其他的设计模式来缓解这一问题。但当文法非常复杂时,其他的技术如语法分析程序或编译器生成器更为合适。
4)增加了新的解释表达式的方式解释器模式使得实现新表达式“计算”变得容易。例如,·你可以在表达式类上定义一个新的操作以支持优美打印或表达式的类型检查。如果你经常创建新的解释表达式的方式,那么可以考虑使用Visitor(5.11)模式以避免修改这些代表文法的类。
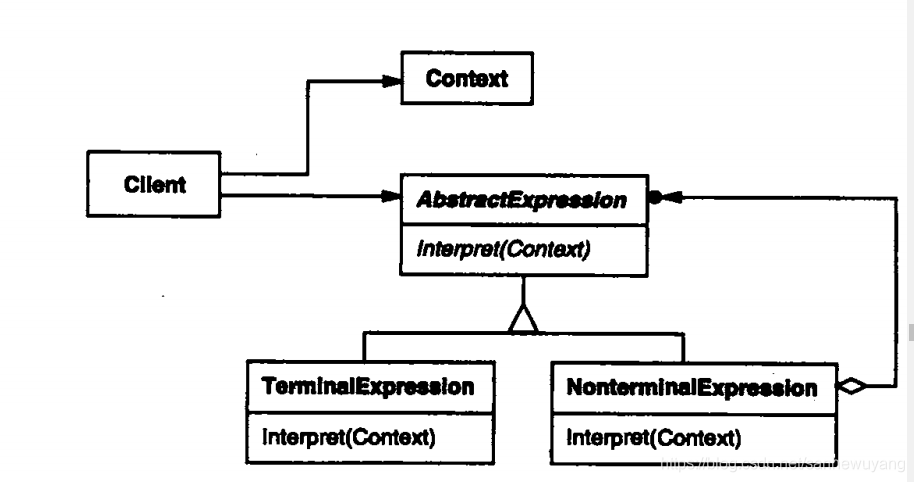
意图:用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。主要解决:对象与对象之间存在大量的关联关系,这样势必会导致系统的结构变得很复杂,同时若一个对象发生改变,我们也需要跟踪与之相关联的对象,同时做出相应的处理。何时使用:多个类相互耦合,形成了网状结构。如何解决:将上述网状结构分离为星型结构。关键代码:对象 Colleague 之间的通信封装到一个类中单独处理。应用实例: 1、中国加入 WTO 之前是各个国家相互贸易,结构复杂,现在是各个国家通过 WTO 来互相贸易。 2、机场调度系统。 3、MVC 框架,其中C(控制器)就是 M(模型)和 V(视图)的中介者。优点: 1、降低了类的复杂度,将一对多转化成了一对一。 2、各个类之间的解耦。 3、符合迪米特原则。缺点:中介者会庞大,变得复杂难以维护。使用场景: 1、系统中对象之间存在比较复杂的引用关系,导致它们之间的依赖关系结构混乱而且难以复用该对象。 2、想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。注意事项:不应当在职责混乱的时候使用。
实现我们通过聊天室实例来演示中介者模式。实例中,多个用户可以向聊天室发送消息,聊天室向所有的用户显示消息。我们将创建两个类 ChatRoom 和 User。User 对象使用 ChatRoom 方法来分享他们的消息。MediatorPatternDemo,我们的演示类使用 User 对象来显示他们之间的通信。
import java.util.Date;
public class ChatRoom {
public static void showMessage(User user, String message){
System.out.println(new Date().toString()
+ " [" + user.getName() +"] : " + message);
}
}
public class User {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public User(String name){
this.name = name;
}
public void sendMessage(String message){
ChatRoom.showMessage(this,message);
}
}
public class MediatorPatternDemo {
public static void main(String[] args) {
User robert = new User("Robert");
User john = new User("John");
robert.sendMessage("Hi! John!");
john.sendMessage("Hello! Robert!");
}
}
执行程序,输出结果:
Thu Jan 31 16:05:46 IST 2013 [Robert] : Hi! John!
Thu Jan 31 16:05:46 IST 2013 [John] : Hello! Robert!
中介者模式有以下优点和缺点:
1)减少了子类生成Mediator将原本分布于多个对象间的行为集中在一起。改变这些行为只需生成Meditator的子类即可。这样各个Colleague类可被重用。.
2)它将各Colleague解耦Mediator有利于各Colleague间的松耦合,你可以独立的改变和复用各Colleague类和Mediator类。
3)它简化了对象协议用Mediator和各Colleague间的一对多的交互来代替多对多的交互。一对多的关系更易于理解、维护和扩展。4)它对对象如何协作进行了抽象将中介作为一个独立的概念并将其封装在一个对象中,使你将注意力从对象各自本身的行为转移到它们之间的交互上来。这有助于弄清楚一个系统中的对象是如何交互的。
5)它使控制集中化中介者模式将交互的复杂性变为中介者的复杂性。因为中介者封装了协议,它可能变得比任一个Colleague都复杂。这可能使得中介者自身成为一个难于维护的庞然大物。
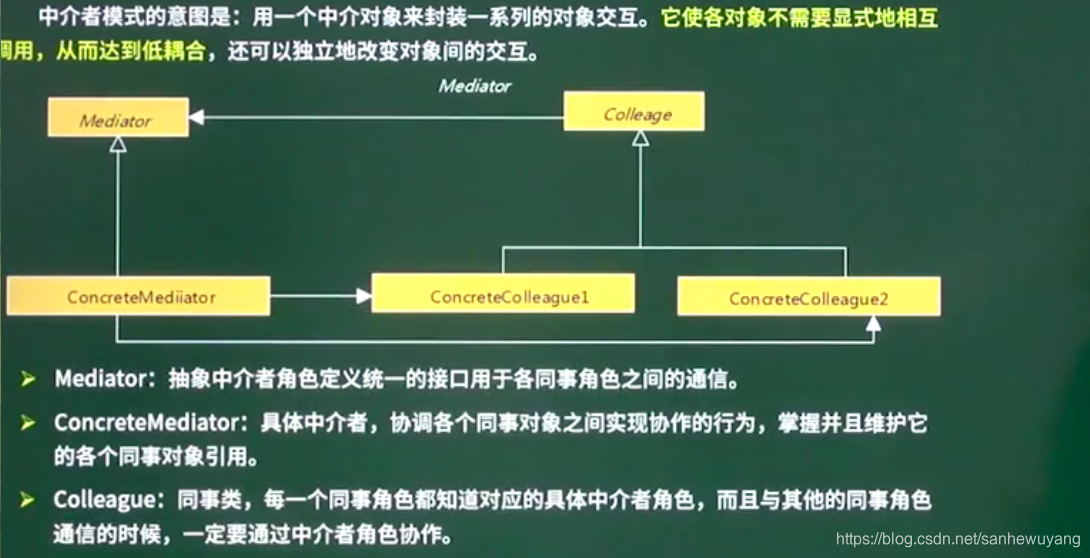
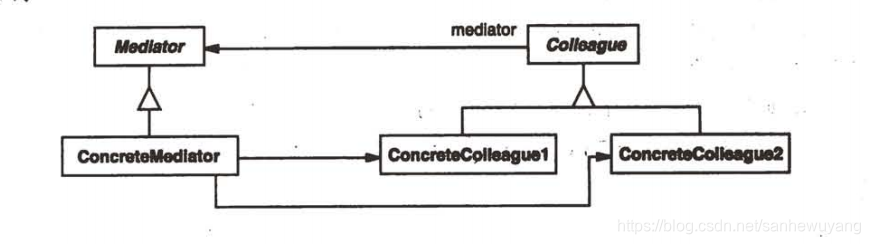
意图:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。主要解决:所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。何时使用:很多时候我们总是需要记录一个对象的内部状态,这样做的目的就是为了允许用户取消不确定或者错误的操作,能够恢复到他原先的状态,使得他有"后悔药"可吃。如何解决:通过一个备忘录类专门存储对象状态。关键代码:客户不与备忘录类耦合,与备忘录管理类耦合。应用实例: 1、后悔药。 2、打游戏时的存档。 3、Windows 里的 ctri + z。 4、IE 中的后退。 4、数据库的事务管理。优点: 1、给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态。 2、实现了信息的封装,使得用户不需要关心状态的保存细节。缺点:消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。使用场景: 1、需要保存/恢复数据的相关状态场景。 2、提供一个可回滚的操作。注意事项: 1、为了符合迪米特原则,还要增加一个管理备忘录的类。 2、为了节约内存,可使用原型模式+备忘录模式。
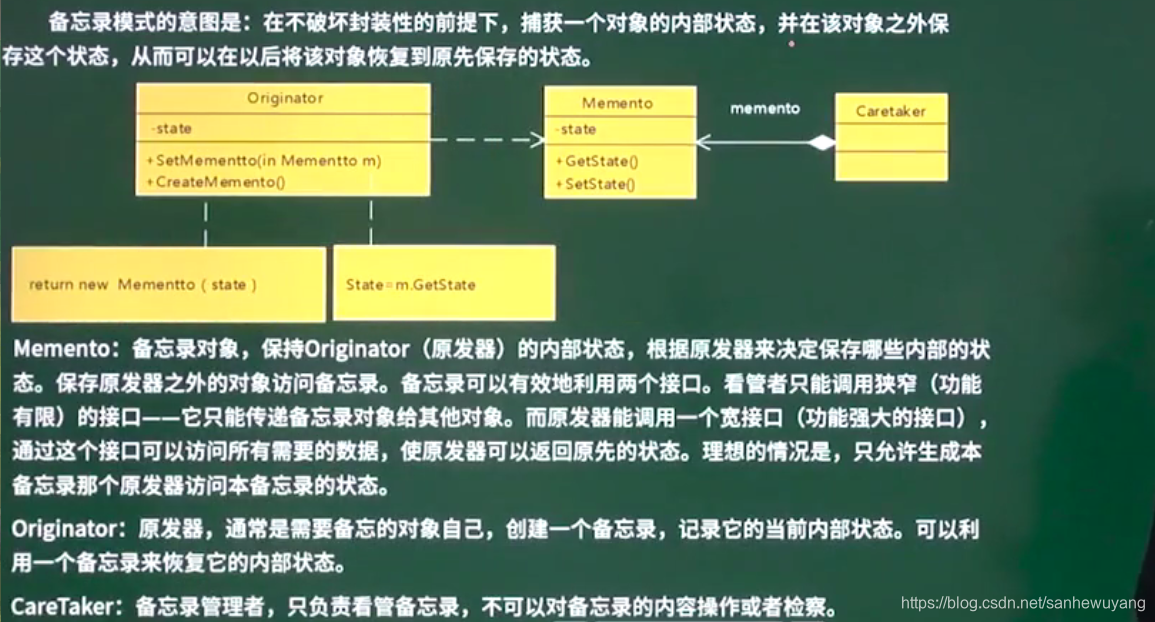
实现
备忘录模式使用三个类
Memento、Originator和CareTaker。Memento包含了要被恢复的对象的状态。Originator创建并在 Memento 对象中存储状态。Caretaker对象负责从Memento中恢复对象的状态。
MementoPatternDemo,我们的演示类使用 CareTaker 和 Originator 对象来显示对象的状态恢复。

public class Memento {
private String state;
public Memento(String state){
this.state = state;
}
public String getState(){
return state;
}
}
public class Originator {
private String state;
public void setState(String state){
this.state = state;
}
public String getState(){
return state;
}
public Memento saveStateToMemento(){
return new Memento(state);
}
public void getStateFromMemento(Memento Memento){
state = Memento.getState();
}
}
import java.util.ArrayList;
import java.util.List;
public class CareTaker {
private List<Memento> mementoList = new ArrayList<Memento>();
public void add(Memento state){
mementoList.add(state);
}
public Memento get(int index){
return mementoList.get(index);
}
}
public class MementoPatternDemo {
public static void main(String[] args) {
Originator originator = new Originator();
CareTaker careTaker = new CareTaker();
originator.setState("State #1");
originator.setState("State #2");
careTaker.add(originator.saveStateToMemento());
originator.setState("State #3");
careTaker.add(originator.saveStateToMemento());
originator.setState("State #4");
System.out.println("Current State: " + originator.getState());
originator.getStateFromMemento(careTaker.get(0));
System.out.println("First saved State: " + originator.getState());
originator.getStateFromMemento(careTaker.get(1));
System.out.println("Second saved State: " + originator.getState());
}
}
Current State: State #4
First saved State: State #2
Second saved State: State #3
1)·
保持封装边界使用备忘录可以避免暴露一些只应由原发器管理却又必须存储在原发器之外的信息。该模式把可能很复杂的Originator内部信息对其他对象屏蔽起来,从而保持了封装边界。.
2)它简化了原发器在其他的保持封装性的设计中, Originator负责保持客户请求过的内部状态版本。这就把所有存储管理的重任交给了Originator。让客户管理它们请求的状态将会简化Originator,并且使得客户工作结束时无需通知原发器。
3)使用备忘录可能代价很高如果原发器在生成备忘录时必须拷贝并存储大量的信息,或者客户非常频繁地创建备忘录和恢复原发器状态,可能会导致非常大的开销。除非封装和恢复Originator状态的开销不大,否则该模式可能并不合适。参见实现一节中关于增量式改变的
4)定义窄接口和宽接口在一些语言中可能难以保证只有原发器可访问备忘录的状态。
5)维护备忘录的潜在代价管理器负责删除它所维护的备忘录。然而,管理器不知道备忘录中有多少个状态。因此当存储备忘录时,一个本来很小的管理器,可能会产生大量的存储开销。

情境:构建一个鸭子超类,当用于扩展不同鸭子子类型,但是有些鸭子不是活的,不能实现超类的行为,比如叫,游泳等,这时候通过覆盖行为或将行为抽象成接口实现他们也是很繁琐的,因为行为有许多。这样行为来自Duck超类的具体实现,或是继承某个接口并由子类自行实现而来。这两种做法都是依赖于“
实现”,我们被实现绑得死死的,没办法更改行为(除非写更多代码)。所以当继承解决不了问题的时候…

设计原则:找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。把会变化的部分取出并“封装”起来,以便以后可以轻易地改动或扩充此部分,好让其他部分不会受到影响。结果如何?代码变化引起的不经意后果变少,系统变得更有弹性。
分开变化和不会变化的部分

设计鸭子的行为
鸭子的子类将使用接口(FlyBehavior与QuackBehavior)所表示的行为

设计原则:针对接口编程,而不是针对实现编程。针对接口编程”真正的意思是“针对超类型(supertype)编程,“针对接口编程”,关键就在多态。利用多态,程序可以针对超类型编程,执行时会根据实际状况执行到真正的行为,不会被绑死在超类型的行为上。
我不懂你为什么非要把FlyBehavior设计成接口。为何不使用抽象超类,这样不就可以使用多态了吗?
“针对超类型编程”这句话,可以更明确地说成“变量的声明类型应该是超类型,通常是一个抽象类或者是一个接口,如此,只要是具体实现此超类型的类所产生的对象,都可以指定给这个变量。这也意味着,声明类时不用理会以后执行时的真正对象类型!”简单的多态例子:假设有一个抽象类Animal,有两个具体的实现(Dog与Cat)继承Animal。
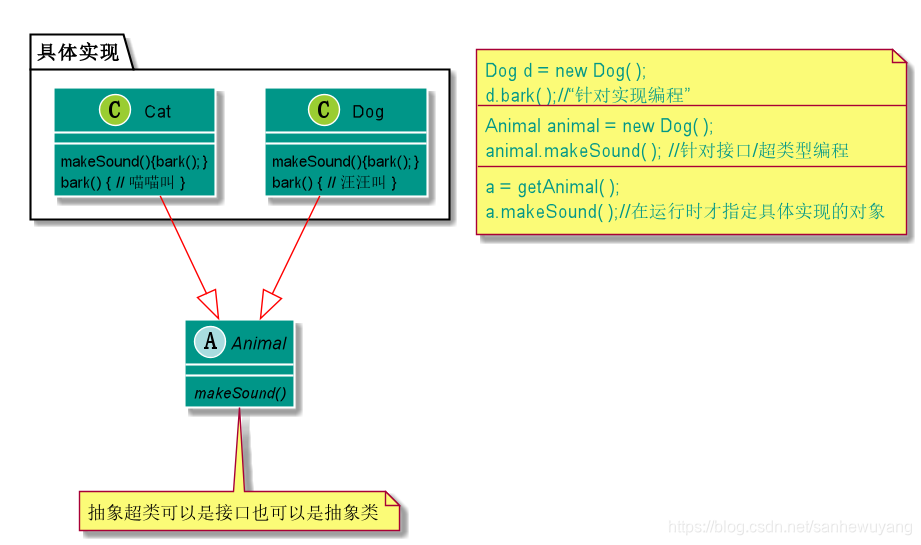
·
实现鸭子的行为
有两个接口,FlyBehavior和QuackBehavior,还有它们对应的类,负责实现具体的行为
- 这样的设计,可以让飞行和呱呱叫的动作被其他的对象复用,因为这些行为已经与鸭子类无关了。
- 而我们可以新增一些行为,不会影响到既有的行为类,也不会影响“使用”到飞行行为的鸭子类。
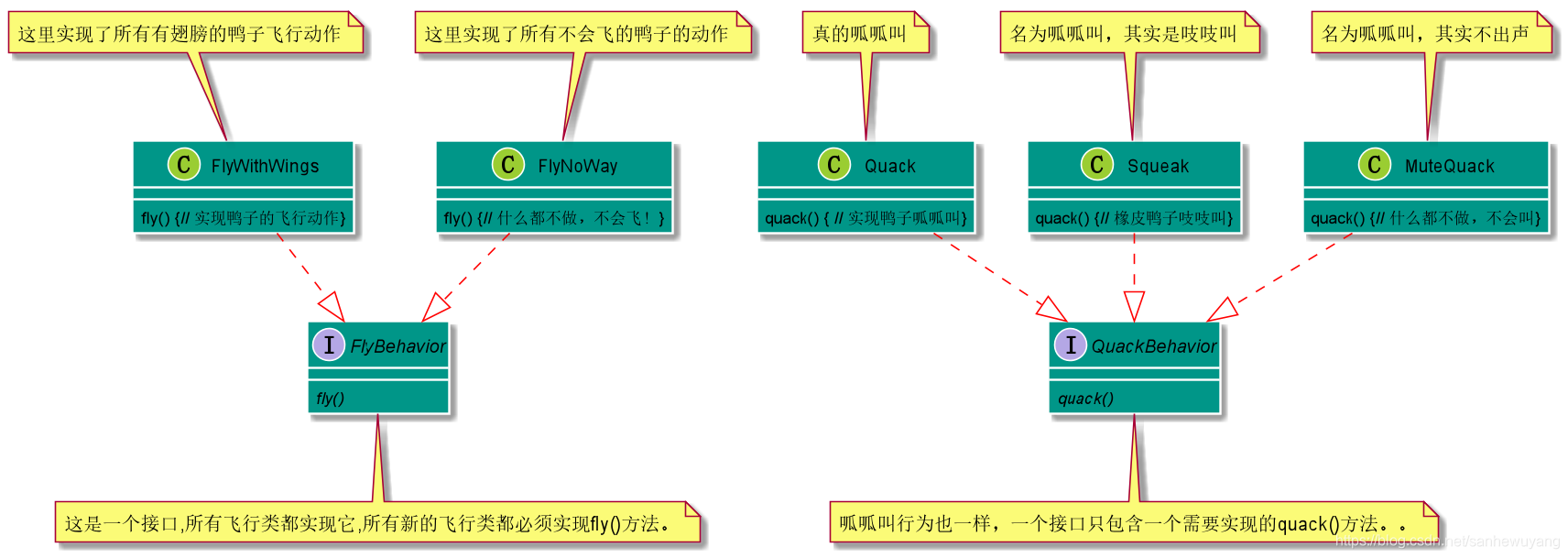
`问`:用一个类代表一个行为,感觉似乎有点奇怪。类不是应该代表某种“东西”吗?类不是应该同时具备状态“与”行为吗?
`答`:在OO系统中,是的,类代表的东西一般都是既有状态(实例变量)又有方法。只是在本例中,碰巧“东西”是个行为。但是即使是行为,也仍然可以有状态和方法,例如,飞行的行为可以具有实例变量,记录飞行行为的属性(每秒翅膀拍动几下、最大高度和速度等)。
`问`:我是不是一定要先把系统做出来,再看看有哪些地方需要变化,然后才回头去把这些地方分离&封装?
`答`:不尽然。通常在你设计系统时,预先考虑到有哪些地方未来可能需要变化,于是提前在代码中加入这些弹性。你会发现,原则与模式可以应用在软件开发生命周期的任何阶段。
·
整合鸭子的行为
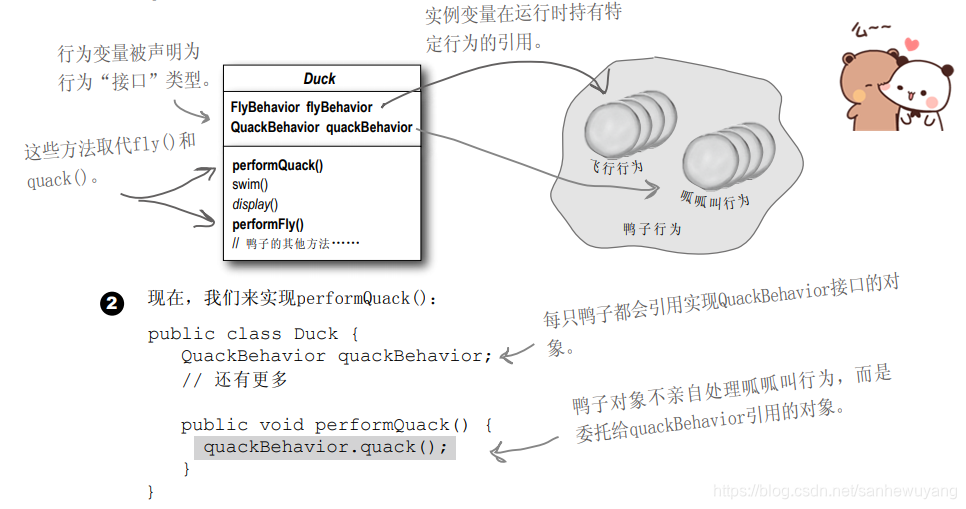

·具体的鸭子(绿头鸭子)通过
子类构造器的方式录入数据:
结合上面的UML看,(通过实例化类似Quack或FlyWithWings的行为类,并把它指定到行为引用变量中
动态设定行为,通过Setting方法。将构造器里的通过Setting方法获取

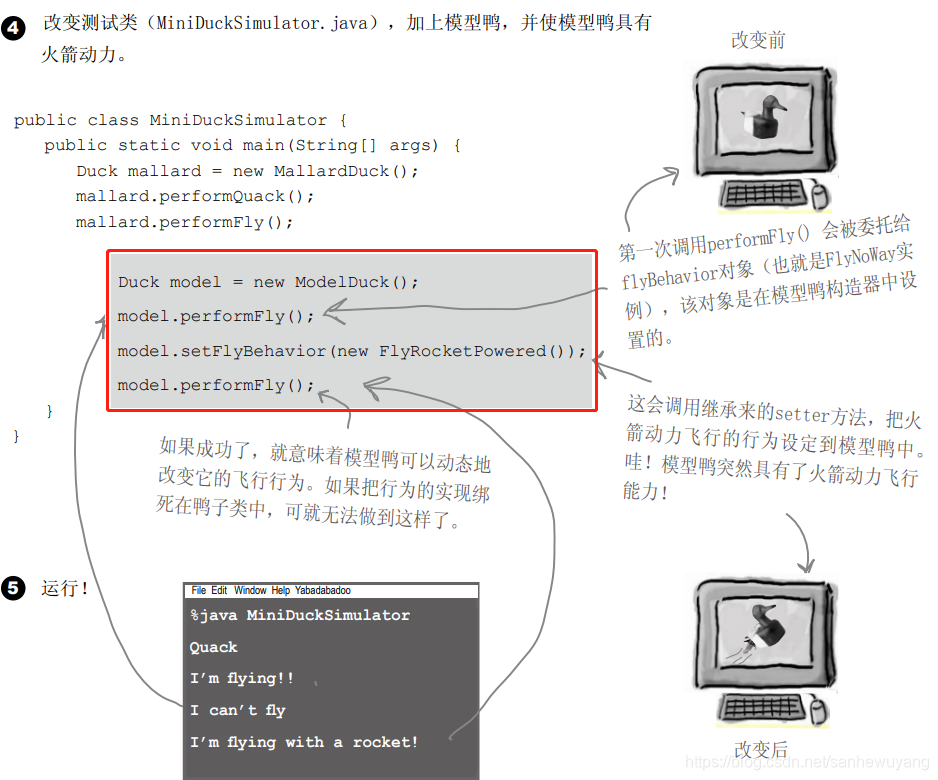
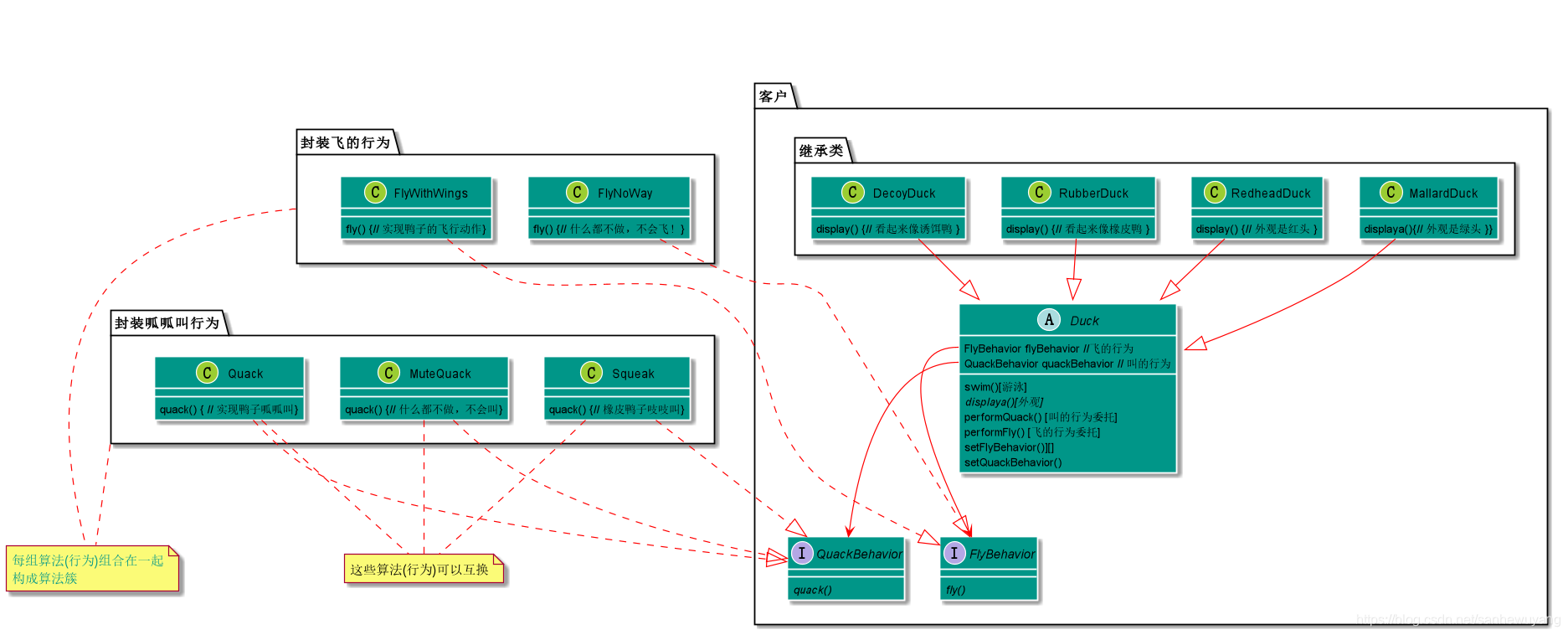
设计原则:多用组合,少用继承。使用组合建立系统具有很大的弹性,不仅可将算法族封装成类,更可以“在运行时动态地改变行为" ,只要组合的行为对象符合正确的接口标准即可。组合用在“许多”设计模式中.
Thread类也是一种策略模式的实现,Thread 是客户,Runnable是算法簇(行为),不同的线程构成算法簇
.............
* @author unascribed
* @see Runnable
* @see Runtime#exit(int)
* @see #run()
* @see #stop()
* @since JDK1.0
*/
public
class Thread implements Runnable {
.......
/* What will be run. */
private Runnable target;
.......
/**
* Allocates a new {@code Thread} object. This constructor has the same
* effect as {@linkplain #Thread(ThreadGroup,Runnable,String) Thread}
* {@code (null, target, gname)}, where {@code gname} is a newly generated
* name. Automatically generated names are of the form
* {@code "Thread-"+}<i>n</i>, where <i>n</i> is an integer.
*
* @param target
* the object whose {@code run} method is invoked when this thread
* is started. If {@code null}, this classes {@code run} method does
* nothing.
*/
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
Runnable接口,算法簇接口
* @author Arthur van Hoff
* @see java.lang.Thread
* @see java.util.concurrent.Callable
* @since JDK1.0
*/
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface <code>Runnable</code> is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
看一个具体实现:
+ oo基础:抽象封装多态继承
+ oo原则:封装变化,多用组合,少用继承针对接口编程,不针对实现编程
+ oo模式:策略模式一定义算法族,分别封装起来,让它们之间可以互相替换,此模武让算法的变化独立于使用算法的客户。
/*
* @Author Liruilong
* @Description :策略模式
* 一个包含某个算法的接口
* 一个或多个该接口的集体的实现,即对于接口的算法的不同的实现
* 一个或多个该接口的具体实现
*Thread类通过重复写run方法就是一种策略模式的体现
* @Date 7:21 2019/9/5
**/
public interface VzlidtionStrategy{
boolean executo(String s);
}
// 具体的实现
class IsAllLowerCase implements VzlidtionStrategy{
@Override
public boolean executo(String s) {
return s.matches("[a-z]+");
}
}
class IsNumeric implements VzlidtionStrategy{
@Override
public boolean executo(String s) {
return s.matches("\\d+");
}
}
class Validator {
private final VzlidtionStrategy vzlidtionStrategy;
Validator(VzlidtionStrategy vzlidtionStrategy) {
this.vzlidtionStrategy = vzlidtionStrategy;
}
public boolean validate(String e){
return vzlidtionStrategy.executo(e);
}
// 不同的算法实现
Validator validator = new Validator(new IsAllLowerCase());
boolean b1 = validator.validate("sddd");
Validator validator1 = new Validator(new IsNumeric());
boolean b2 = validator.validate("sddd");
// java8 使用lambda表达式
Validator validator2 = new Validator((s) ->s.matches("[a-z]+"));
boolean b3 = validator2.validate("ddfdf");
}
Strategy模式有下面的一些优点和缺点:
- 1)相关算法系列 Strategy类层次为Context定义了一系列的
可供重用的算法或行为。继承有助于·析取出这些算法中的公共功能- 2)
一个替代继承的方法继承提供了另一种支持多种算法或行为的方法。你可以直接生成一个Context类的子类,从而给它以不同的行为。但这会将行为硬行编制到Context中,而将算法的实现与Context的实现混合起来,从而使Context难以理解、难以维护和难以扩展,而且还不能动态地改变算法。最后你得到一堆相关的类,它们之间的唯一差别是它们所使用的算法或行为。将算法封装在独立的Strategy类中使得你可以独立于其Context改变它,使它易于切换、易于理解、易于扩展。- 3)
消除了一些条件语句Strategy模式提供了用条件语句选择所需的行为以外的另一种选择。当不同的行为堆砌在一个类中时,很难避免使用条件语句来选择合适的行为。将行为封装在一个个独立的Strategy类中消除了这些条件语句- 4)实现的选择Strategy模式可以提供相同行为的不同实现。客户可以根据不同时间/空间权衡取舍要求从不同策略中进行选择。
- 5)
客户必须了解不同的Strategy本模式有一个潜在的缺点,就是一个客户要选择一个合适的Strategy就必须知道这些Strategy到底有何不同。此时可能不得不向客户暴露具体的实现问题。因此仅当这些不同行为变体与客户相关的行为时,才需要使用Strategy模式。- 6)
Strategy和Context之间的通信开销,无论各个ConcreteStrategy实现的算法是简单还是复杂,它们都共享Strategy定义的接口。因此很可能某些ConcreteStrategy不会都用到所有通过这个接口传递给它们的信息;简单的ConcreteStrategy可能不使用其中的任何信息!这就意味着有时Context会创建和初始化一些永远不会用到的参数。如果存在这样问题;那么将需要在Strategy和Context之间更进行紧密的耦合。7)增加了对象的数目 Strategy增加了一个应用中的对象的数目。有时你可以将Strategy实现为可供各Context共享的无状态的对象来减少这一开销。任何其余的状态都由Context维护。
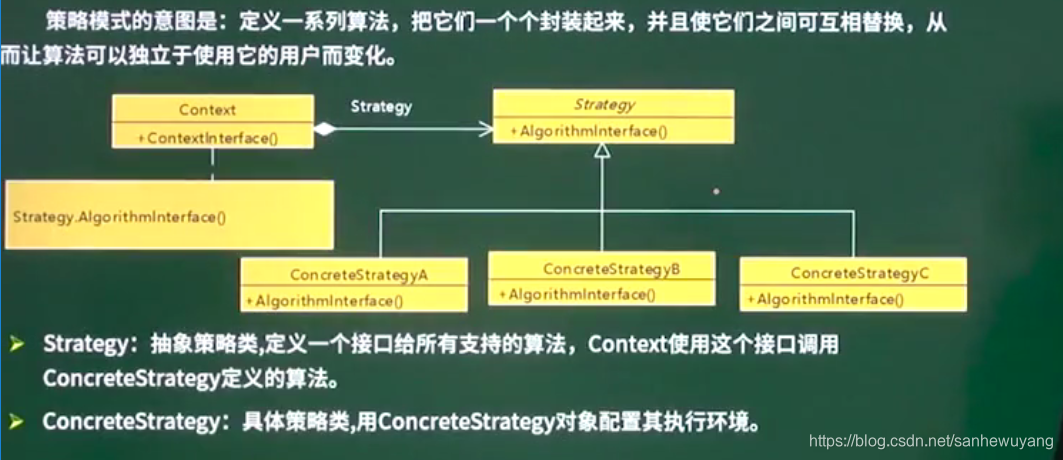

- 点赞
- 收藏
- 关注作者
评论(0)