云原生模式部署Flink应用

入门指南
本入门部分将指导您在 Kubernetes 上设置功能齐全的 Flink 集群。
基本介绍
Kubernetes 是一种流行的容器编排系统,用于自动化计算机应用程序的部署、扩展和管理。 Flink 的原生 Kubernetes 集成允许您直接在运行的 Kubernetes 集群上部署 Flink。 此外,Flink 能够根据所需资源动态分配和取消分配 TaskManager,因为它可以直接与 Kubernetes 对话。
准备
入门部分假设正在运行的 Kubernetes 集群满足以下要求:
-
Kubernetes >= 1.9。
-
KubeConfig,它可以列出、创建、删除 Pod 和服务,可通过 ~/.kube/config 进行配置。 您可以通过运行 kubectl auth can-i <list|create|edit|delete> pods 来验证权限。
-
启用 Kubernetes DNS。
-
具有创建、删除 Pod 的 RBAC 权限的默认服务帐户。
如果您还没有创建k8s集群,可参考文章:https://lrting.top/backend/3919/快速搭建一个k8s集群。
在k8s上启动flink session
在kubernetes上启动flink session时,还需要额外的两个jar包,需要将其放到flink/lib目录下:
cd flink/lib
wget https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-jdk15on/1.69/bcpkix-jdk15on-1.69.jar
wget https://repo1.maven.org/maven2/org/bouncycastle/bcprov-jdk15on/1.69/bcprov-jdk15on-1.69.jar
创建flink用户和授权
kubectl create namespace flink
kubectl create serviceaccount flink
kubectl create clusterrolebinding flink-role-binding-flink \
--clusterrole=edit \
--serviceaccount=default:flink
如果不创建flink用户并授权,而是使用默认用户提交Flink任务会有如下报错:
Caused by: io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: GET at: https://10.10.0.1/api/v1/namespaces/default/pods?labelSelector=app%3Dkaibo-test%2Ccomponent%3Dtaskmanager%2Ctype%3Dflink-native-kubernetes. Message: Forbidden!Configured service account doesn't have access. Service account may have been revoked. pods is forbidden: User "system:serviceaccount:default:default" cannot list resource "pods" in API group "" in the namespace "default".
一旦你的 Kubernetes 集群运行并且 kubectl 被配置为指向它,你可以在会话模式下启动一个 Flink 集群
# (1) Start Kubernetes session
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.namespace=flink
# (2) Submit example job
$ ./bin/flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dkubernetes.namespace=flink \
./examples/streaming/TopSpeedWindowing.jar
# (3) Stop Kubernetes session by deleting cluster deployment
$ kubectl delete deployment/my-first-flink-cluster
使用 Minikube 时,需要调用 minikube tunnel 才能在 Minikube 上暴露 Flink 的 LoadBalancer 服务。
Flink session在启动之后即默认将8081暴露到本机端口,下述为运行启动k8s session命令的输出:
[root@rancher02 flink-1.13.5]# ./bin/kubernetes-session.sh \
> -Dkubernetes.cluster-id=my-first-flink-cluster \
> -Dkubernetes.namespace=flink
2022-02-26 14:49:16,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, localhost
2022-02-26 14:49:16,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2022-02-26 14:49:16,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.endpoint, http://10.0.2.70:9000
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.path.style.access, true
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.access.key, PCGIXWJBM78H74CWUITM
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: s3.secret.key, ******
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend, rocksdb
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.checkpoints.dir, s3://flink/checkpoints
2022-02-26 14:49:16,206 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.savepoints.dir, s3://flink/savepoints
2022-02-26 14:49:16,207 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend.incremental, false
2022-02-26 14:49:16,207 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2022-02-26 14:49:16,249 INFO org.apache.flink.client.deployment.DefaultClusterClientServiceLoader [] - Could not load factory due to missing dependencies.
2022-02-26 14:49:17,310 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-02-26 14:49:17,320 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-02-26 14:49:17,437 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration blob.server.port will be set to 6124
2022-02-26 14:49:17,437 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration taskmanager.rpc.port will be set to 6122
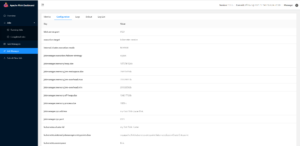
2022-02-26 14:49:18,174 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink session cluster my-first-flink-cluster successfully, JobManager Web Interface: http://10.0.2.78:8081
查看打开运行flink session的8081端口,可以看到:
部署模式
对于生产使用,我们建议在应用模式下部署 Flink 应用程序,因为这些模式为应用程序提供了更好的隔离。
Application Mode
Application Mode 要求用户代码与 Flink 镜像捆绑在一起,因为它在集群上运行用户代码的 main() 方法。 Application Mode 确保在应用程序终止后正确清理所有 Flink 组件。
Flink 社区提供了一个基础 Docker 镜像,可用于捆绑用户代码:
FROM flink
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
在 custom-image-name 下创建并发布 Docker 镜像后,您可以使用以下命令启动应用程序集群:
$ ./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=custom-image-name \
local:///opt/flink/usrlib/my-flink-job.jar
local 是应用模式下唯一支持的方案。
kubernetes.cluster-id 选项指定集群名称并且必须是唯一的。 如果不指定此选项,则 Flink 将生成一个随机名称。
kubernetes.container.image 选项指定启动 pod 的镜像。
部署应用程序集群后,您可以与之交互:
# List running job on the cluster
$ ./bin/flink list --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster
# Cancel running job
$ ./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster <jobId>
您可以通过将键值对 -Dkey=value 传递给 bin/flink 来覆盖 conf/flink-conf.yaml 中设置的配置。
Per-Job Cluster Mode
Flink on Kubernetes 不支持 Per-Job Cluster Mode。
Session Mode
您已经在本页顶部的入门指南中看到了 Session 集群的部署。
会话模式可以在两种模式下执行:
- 分离模式(默认):kubernetes-session.sh 在 Kubernetes 上部署 Flink 集群,然后终止。
- 附加模式(-Dexecution.attached=true):kubernetes-session.sh 保持活动状态并允许输入命令来控制正在运行的 Flink 集群。 例如,stop 停止正在运行的 Session 集群。 键入 help 以列出所有支持的命令。
为了使用集群 ID my-first-flink-cluster 重新连接到正在运行的会话集群,请使用以下命令:
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
您可以通过将键值对 -Dkey=value 传递给 bin/kubernetes-session.sh 来覆盖 conf/flink-conf.yaml 中设置的配置。
停止正在运行的Session集群
为了停止运行集群 id 为 my-first-flink-cluster 的会话集群,您可以删除 Flink 部署或使用:
$ echo 'stop' | ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
k8s上运行Flink程序更多参考资料
在 Kubernetes 上配置 Flink
特定于 Kubernetes 的配置选项列在配置页面上。
Flink 使用 Fabric8 Kubernetes 客户端与 Kubernetes APIServer 通信来创建/删除 Kubernetes 资源(例如 Deployment、Pod、ConfigMap、Service 等),以及观察 Pod 和 ConfigMap。 除了上述 Flink 配置选项外,Fabric8 Kubernetes 客户端的一些专家选项可以通过系统属性或环境变量进行配置。
例如,用户可以使用以下 Flink 配置选项来设置并发最大请求数,这允许在使用 Kubernetes HA 服务时在会话集群中运行更多作业。 请注意,每个 Flink 作业会消耗 3 个并发请求。
containerized.master.env.KUBERNETES_MAX_CONCURRENT_REQUESTS: 200
env.java.opts.jobmanager: "-Dkubernetes.max.concurrent.requests=200"
访问Flink的Web UI
Flink 的 Web UI 和 REST 端点可以通过 kubernetes.rest-service.exposed.type 配置选项以多种方式公开。
ClusterIP:在集群内部 IP 上公开服务。 该服务只能在集群内访问。 如果要访问 JobManager UI 或将作业提交到现有会话,则需要启动本地代理。 然后,您可以使用 localhost:8081 将 Flink 作业提交到会话或查看仪表板。
$ kubectl port-forward service/<ServiceName> 8081
NodePort:在每个 Node 的 IP 上的静态端口(NodePort)上公开服务。 <NodeIP>:<NodePort> 可用于联系 JobManager 服务。 NodeIP 也可以替换为 Kubernetes ApiServer 地址。 你可以在你的 kube 配置文件中找到它的地址。
LoadBalancer:使用云提供商的负载均衡器向外部公开服务。 由于云提供商和 Kubernetes 需要一些时间来准备负载均衡器,您可能会在客户端日志中获得一个 NodePort JobManager Web 界面。 您可以使用 kubectl get services/<cluster-id>-rest 获取 EXTERNAL-IP 并手动构建负载均衡器 JobManager Web 界面 http://<EXTERNAL-IP>:8081。
更多信息请参考 Kubernetes 发布服务的官方文档。
根据您的环境,使用 LoadBalancer REST 服务公开类型启动 Flink 集群可能会使集群可公开访问(通常具有执行任意代码的能力)。
日志
Kubernetes 集成将 conf/log4j-console.properties 和 conf/logback-console.xml 作为 ConfigMap 暴露给 pod。 对这些文件的更改将对新启动的集群可见。
访问日志
默认情况下,JobManager 和 TaskManager 会同时将日志输出到控制台和每个 pod 中的 /opt/flink/log。 STDOUT 和 STDERR 输出只会被重定向到控制台。 您可以通过以下方式访问它们
$ kubectl logs <pod-name>
如果 pod 正在运行,您还可以使用 kubectl exec -it <pod-name> bash 隧道进入并查看日志或调试进程。
访问 TaskManager 的日志
Flink 会自动取消分配空闲的 TaskManager,以免浪费资源。 这种行为会使访问各个 pod 的日志变得更加困难。 您可以通过配置 resourcemanager.taskmanager-timeout 来增加空闲 TaskManager 释放前的时间,以便您有更多时间检查日志文件。
动态修改日志级别
如果您已将 logger 配置为自动检测配置更改,那么您可以通过更改相应的 ConfigMap 来动态调整日志级别(假设集群 id 是 my-first-flink-cluster):
$ kubectl edit cm flink-config-my-first-flink-cluster
使用插件
为了使用插件,您必须将它们复制到 Flink JobManager/TaskManager pod 中的正确位置。 您可以使用内置插件,而无需安装卷或构建自定义 Docker 映像。 例如,使用以下命令为您的 Flink 会话集群启用 S3 插件。
$ ./bin/kubernetes-session.sh
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.5.jar \
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.5.jar
自定义Docker镜像
如果你想使用自定义的 Docker 镜像,那么你可以通过配置选项 kubernetes.container.image 来指定它。 Flink 社区提供了丰富的 Flink Docker 镜像,可以作为一个很好的起点。 了解如何自定义 Flink 的 Docker 镜像,了解如何启用插件、添加依赖项和其他选项。
使用密钥
Kubernetes Secrets 是一个包含少量敏感数据的对象,例如密码、令牌或密钥。 此类信息可能会以其他方式放入特定pod或镜像中。 Flink on Kubernetes 可以通过两种方式使用 Secret:
- 使用 Secrets 作为 pod 中的文件;
- 使用 Secrets 作为环境变量;
使用 Secrets 作为 pod 中的文件
以下命令将在已启动的 pod 中的路径 /path/to/secret 下挂载密钥 mysecret:
$ ./bin/kubernetes-session.sh -Dkubernetes.secrets=mysecret:/path/to/secret
然后可以在文件 /path/to/secret/username 和 /path/to/secret/password 中找到密钥 mysecret 的用户名和密码。 有关更多详细信息,请参阅 Kubernetes 官方文档。
使用 Secrets 作为环境变量
以下命令会将密钥 mysecret 公开为已启动 pod 中的环境变量:
$ ./bin/kubernetes-session.sh -Dkubernetes.env.secretKeyRef=\
env:SECRET_USERNAME,secret:mysecret,key:username;\
env:SECRET_PASSWORD,secret:mysecret,key:password
环境变量 SECRET_USERNAME 包含用户名,环境变量 SECRET_PASSWORD 包含密钥 mysecret 的密码。 有关更多详细信息,请参阅 Kubernetes 官方文档。
K8s上的高可用设置
可参考:https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/ha/overview/
手动资源清理
Flink 使用 Kubernetes OwnerReference 清理所有集群组件。 所有 Flink 创建的资源,包括 ConfigMap、Service 和 Pod,都将 OwnerReference 设置为 deployment/<cluster-id>。 当部署被删除时,所有相关资源将被自动删除。
$ kubectl delete deployment/<cluster-id>
支持的K8S版本
目前所有大于1.9版本的k8s都支持
命名空间(namespace)
Kubernetes 中的命名空间通过资源配额在多个用户之间划分集群资源。 Flink on Kubernetes 可以使用命名空间来启动 Flink 集群。 命名空间可以通过 kubernetes.namespace 进行配置。
RBAC
基于角色的访问控制 (RBAC) 是一种根据企业内个人用户的角色来调节对计算或网络资源的访问的方法。 用户可以配置 JobManager 使用的 RBAC 角色和服务帐户来访问 Kubernetes 集群内的 Kubernetes API 服务器。
每个命名空间都有一个默认服务帐户。 但是,默认服务帐户可能没有在 Kubernetes 集群中创建或删除 Pod 的权限。 用户可能需要更新默认服务帐号的权限或指定另一个绑定了正确角色的服务帐号。
$ kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=default:default
如果不想使用默认服务账号,可以使用如下命令新建一个 flink-service-account 服务账号并设置角色绑定。 然后使用配置选项 -Dkubernetes.service-account=flink-service-account 使 JobManager pod 使用 flink-service-account 服务帐户来创建/删除 TaskManager pods 和 leader ConfigMaps。 这也将允许 TaskManager 监视领导者 ConfigMaps 以检索 JobManager 和 ResourceManager 的地址。
$ kubectl create serviceaccount flink-service-account
$ kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink-service-account
有关更多信息,请参阅有关 RBAC 授权的官方 Kubernetes 文档。
Pod模板
Flink 允许用户通过模板文件定义 JobManager 和 TaskManager pod。 这允许直接支持 Flink Kubernetes 配置选项不支持的高级功能。 使用 kubernetes.pod-template-file 指定包含 pod 定义的本地文件。 它将用于初始化 JobManager 和 TaskManager。 主容器应使用名称 flink-main-container 定义。 有关更多信息,请参阅 pod 模板示例。
Flink 覆盖的字段
pod 模板的某些字段会被 Flink 覆盖。 解析有效字段值的机制可以分为以下几类:
-
Flink 定义:用户无法配置。
-
由用户定义:用户可以自由指定该值。 Flink 框架不会设置任何额外的值,有效值来自 config 选项和模板。
-
优先顺序:首先采用显式配置选项值,然后是 pod 模板中的值,最后是配置选项的默认值(如果未指定)。
-
与 Flink 合并:Flink 会将设置的值与用户定义的值合并(参见“由用户定义”的优先顺序)。 在同名字段的情况下,Flink 值具有优先权。
有关将被覆盖的 pod 字段的完整列表,请参考:Pod Template。 pod 模板中定义的所有未在表中列出的字段将不受影响。
Example of Pod Template
pod-template.yaml
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
initContainers:
- name: artifacts-fetcher
image: artifacts-fetcher:latest
# Use wget or other tools to get user jars from remote storage
command: [ 'wget', 'https://path/of/StateMachineExample.jar', '-O', '/flink-artifact/myjob.jar' ]
volumeMounts:
- mountPath: /flink-artifact
name: flink-artifact
containers:
# Do not change the main container name
- name: flink-main-container
resources:
requests:
ephemeral-storage: 2048Mi
limits:
ephemeral-storage: 2048Mi
volumeMounts:
- mountPath: /opt/flink/volumes/hostpath
name: flink-volume-hostpath
- mountPath: /opt/flink/artifacts
name: flink-artifact
- mountPath: /opt/flink/log
name: flink-logs
# Use sidecar container to push logs to remote storage or do some other debugging things
- name: sidecar-log-collector
image: sidecar-log-collector:latest
command: [ 'command-to-upload', '/remote/path/of/flink-logs/' ]
volumeMounts:
- mountPath: /flink-logs
name: flink-logs
volumes:
- name: flink-volume-hostpath
hostPath:
path: /tmp
type: Directory
- name: flink-artifact
emptyDir: { }
- name: flink-logs
emptyDir: { }
- 点赞
- 收藏
- 关注作者
评论(0)