CoordConv:给你的卷积加上坐标

CoordConv:给你的卷积加上坐标
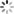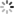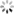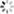
一、理论介绍
1.1 CoordConv理论详解
这是一篇考古的论文复现项目,在2018年Uber团队提出这个CoordConv模块的时候有很多文章对其进行批评,认为这个不值得发布一篇论文,但是现在重新看一下这个idea,同时再对比一下目前Transformer中提出的位置编码(Position Encoding),你就会感概历史是个圈,在角点卷积中,为卷积添加两个坐标编码实际上与Transformer中提出的位置编码是同样的道理。
众所周知,深度学习里的卷积运算是具有平移等变性的,这样可以在图像的不同位置共享统一的卷积核参数,但是这样卷积学习过程中是不能感知当前特征在图像中的坐标的,论文中的实验证明如下图所示。通过该实验,作者证明了传统卷积在卷积核进行局部运算时,仅仅能感受到局部信息,并且是无法感受到位置信息的。CoordConv就是通过在卷积的输入特征图中新增对应的通道来表征特征图像素点的坐标,让卷积学习过程中能够一定程度感知坐标来提升检测精度。
传统卷积无法将空间表示转换成笛卡尔空间中的坐标和one-hot像素空间中的坐标。卷积是等变的,也就是说当每个过滤器应用到输入上时,它不知道每个过滤器在哪。我们可以帮助卷积,让它知道过滤器的位置。这一过程需要在输入上添加两个通道实现,一个在i坐标,另一个在j坐标。通过上面的添加坐标的操作,我们可以的出一种新的卷积结构–CoordConv,其结构如下图所示:
二、代码实战
本部分根据CoordConv论文并参考飞桨的官方实现完成CoordConv的复现。
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import ParamAttr
from paddle.regularizer import L2Decay
from paddle.nn import AvgPool2D, Conv2D
2.2 CoordConv类代码实现
首先继承nn.Layer基类,其次使用paddle.arange定义gx``gy两个坐标,并且停止它们的梯度反传gx.stop_gradient = True,最后将它们concat到一起送入卷积即可。
class CoordConv(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(CoordConv, self).__init__()
self.conv = Conv2D(
in_channels + 2, out_channels , kernel_size , stride , padding)
def forward(self, x):
b = x.shape[0]
h = x.shape[2]
w = x.shape[3]
gx = paddle.arange(w, dtype='float32') / (w - 1.) * 2.0 - 1.
gx = gx.reshape([1, 1, 1, w]).expand([b, 1, h, w])
gx.stop_gradient = True
gy = paddle.arange(h, dtype='float32') / (h - 1.) * 2.0 - 1.
gy = gy.reshape([1, 1, h, 1]).expand([b, 1, h, w])
gy.stop_gradient = True
y = paddle.concat([x, gx, gy], axis=1)
y = self.conv(y)
return y
class dcn2(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(dcn2, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.offsets = paddle.nn.Conv2D(64, 18, kernel_size=3, stride=2, padding=1)
self.mask = paddle.nn.Conv2D(64, 9, kernel_size=3, stride=2, padding=1)
self.conv4 = CoordConv(64, 64, (3,3), 2, 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
cnn3 = dcn2()
model3 = paddle.Model(cnn3)
model3.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-26 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-27 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-28 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-31 [[64, 66, 7, 7]] [64, 64, 4, 4] 38,080
CoordConv-4 [[64, 64, 7, 7]] [64, 64, 4, 4] 0
Flatten-1 [[64, 64, 4, 4]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 64] 65,600
Linear-2 [[64, 64]] [64, 1] 65
===========================================================================
Total params: 160,065
Trainable params: 160,065
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 26.09
Params size (MB): 0.61
Estimated Total Size (MB): 27.45
---------------------------------------------------------------------------
{'total_params': 160065, 'trainable_params': 160065}
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn1 = MyNet()
model1 = paddle.Model(cnn1)
model1.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-2 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-3 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-4 [[64, 64, 7, 7]] [64, 64, 4, 4] 36,928
Flatten-1 [[64, 64, 4, 4]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 64] 65,600
Linear-2 [[64, 64]] [64, 1] 65
===========================================================================
Total params: 158,913
Trainable params: 158,913
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.59
Params size (MB): 0.61
Estimated Total Size (MB): 26.95
---------------------------------------------------------------------------
{'total_params': 158913, 'trainable_params': 158913}
总结
相信通过之前的教程,相信大家已经能够熟练掌握了迅速开启训练的方法。所以,之后的教程我都会关注于具体的代码实现以及相关的理论介绍。如无必要,不再进行对比实验。本次教程主要对CoordConv的理论进行了介绍,对其进行了复现,并展示了其在网络结构中的用法。大家可以根据的实际需要,将其移植到自己的网络中。
- 一些需要注意的点
-
CoordConv的位置在网络中应该尽量靠前
-
最好的应用方向是姿态估计等对位置高度敏感的CV任务
- 点赞
- 收藏
- 关注作者
评论(0)