spark SQL配置连接Hive Metastore 3.1.2

【摘要】 Hive Metastore作为元数据管理中心,支持多种计算引擎的读取操作,例如Flink、Presto、Spark等。本文讲述通过spark SQL配置连接Hive Metastore,并以3.1.2版本为例。通过Spark连接Hive Metastore,需要准备如下文件:hive-site.xmlapache-hive-3.1.2-binspark-3.0.3-bin-hadoop3....
Hive Metastore作为元数据管理中心,支持多种计算引擎的读取操作,例如Flink、Presto、Spark等。本文讲述通过spark SQL配置连接Hive Metastore,并以3.1.2版本为例。
通过Spark连接Hive Metastore,需要准备如下文件:
- hive-site.xml
- apache-hive-3.1.2-bin
- spark-3.0.3-bin-hadoop3.2
在完成下述操作之前,当然首先需要安装并启动hive standalone metastore,并将hive-site.xml文件拷贝到spark的conf目录下。
然后修改conf/spark-default.conf文件,新增如下配置
spark.sql.hive.metastore.version 3.1.2
spark.sql.hive.metastore.jars /data/apache-hive-3.1.2-bin/lib/*
接着便可启动spark sql
bin/spark-sql
查看databases
show databases;

查看hive_storage中的所有表
use hive_storage;
show tables;

查看sample_table_1表中的数据
select * from sample_table_1;

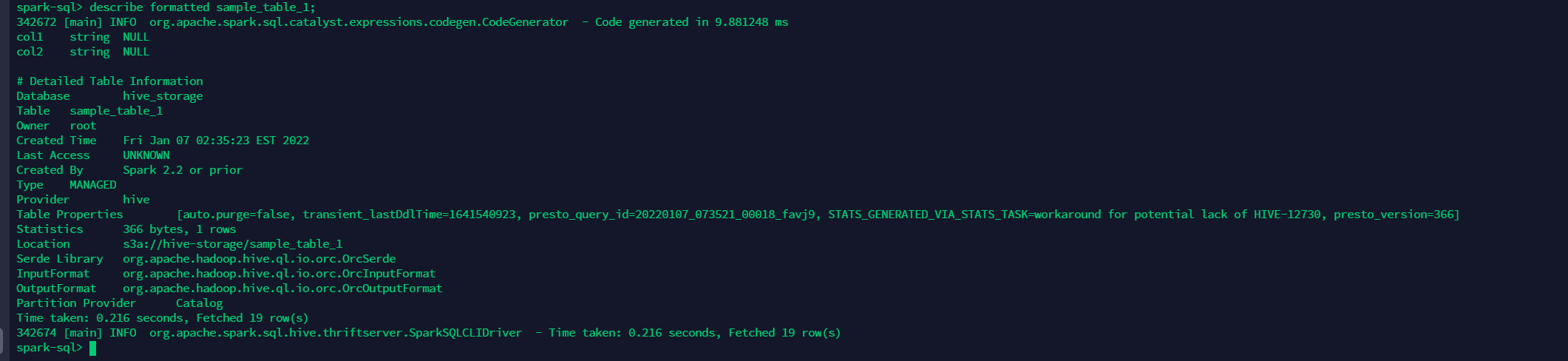
查看表sample_table_1的详细信息
describe formatted sample_table_1;
【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)